📝 Paper Summary
Reinforcement Learning
Policy Optimization
Trust Region Methods
PPO-BR dynamically modulates the PPO clipping threshold by expanding the trust region during high-entropy exploration and contracting it during reward-stable convergence phases.
Core Problem
Proximal Policy Optimization (PPO) uses a static trust region (clipping threshold) that fails to adapt to different learning phases, causing exploration starvation early on and instability near convergence.
Why it matters:
- Static clipping forces a brittle trade-off: aggressive clipping stifles early exploration in sparse-reward tasks, while loose clipping permits destabilizing updates in late stages
- Existing adaptive methods typically rely on heuristics or single signals (entropy OR reward), missing the synergy required for safety-critical domains like robotic surgery
- PPO's inability to adapt leads to 2x higher variance in safety-critical domains and 28% longer convergence in sparse-reward tasks
Concrete Example:
In the Humanoid control task, standard PPO with a fixed clip threshold continues to allow large policy updates even after the agent has learned to walk, leading to high reward variance (±300). PPO-BR detects the reward plateau, contracts the clipping threshold, and reduces variance to ±150, ensuring a smoother gait.
Key Novelty
Bidirectional Regularization (PPO-BR)
- Fuses two complementary signals into the clipping mechanism: expands the trust region when policy entropy is high (encouraging exploration) and contracts it when reward progression slows (enforcing stability)
- Introduces a unified, mathematically bounded adaptation rule that preserves monotonic improvement guarantees without requiring auxiliary networks or meta-optimization
Architecture
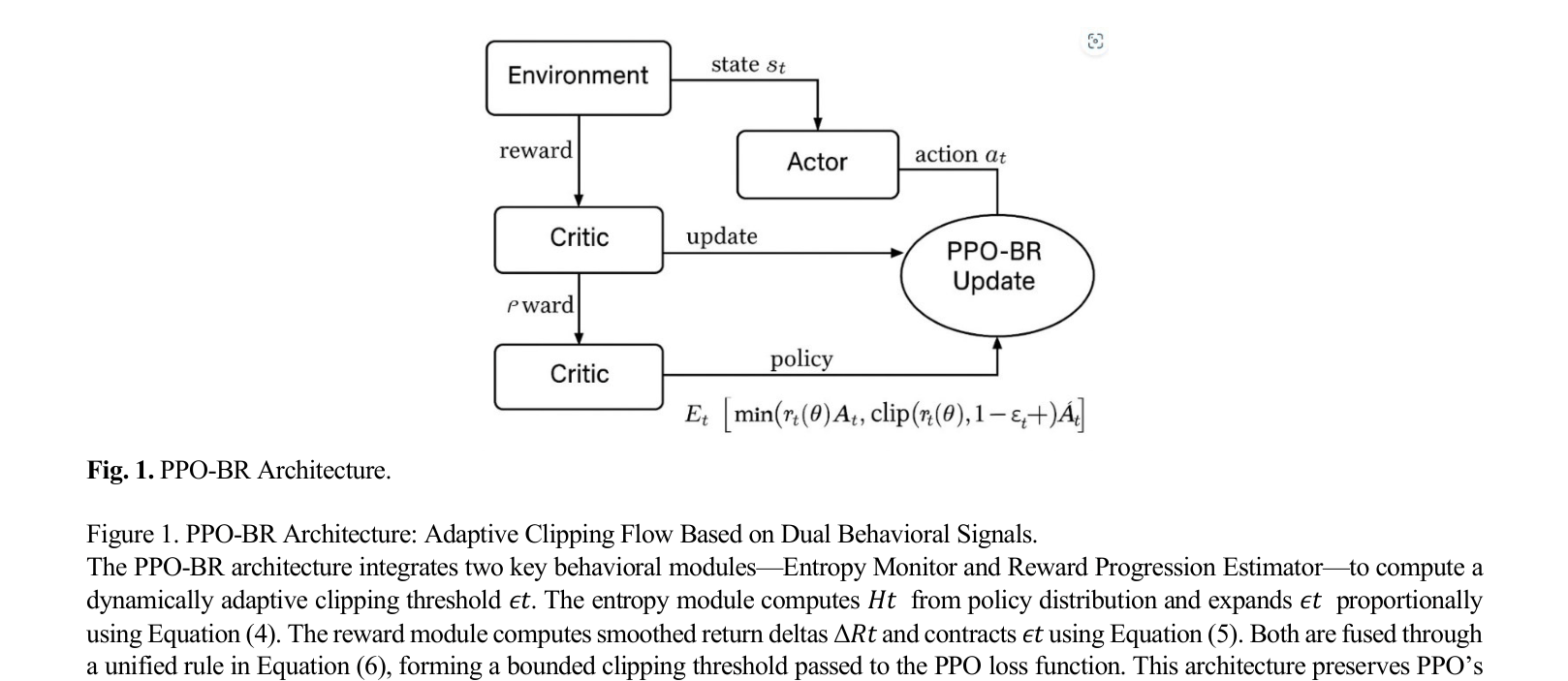
The adaptive clipping mechanism of PPO-BR, showing how entropy and reward signals modulate the epsilon threshold.
Evaluation Highlights
- +31.3% average return improvement on the complex Humanoid benchmark compared to standard PPO
- 50% reduction in reward variance on Humanoid (from 300 to 150), indicating significantly higher stability
- 98% success rate in simulated robotic arm pick-and-place tasks (vs. 82% for PPO), with 40.7% fewer collisions
Breakthrough Assessment
7/10
Strong empirical results and a theoretically grounded, lightweight modification to a standard algorithm (PPO). While the core concept of adaptive clipping isn't new, the dual-signal fusion and rigorous benchmarking make it a valuable contribution.