📝 Paper Summary
Reinforcement Learning (RL)
On-policy Optimization
Large-scale Parallelization
Performance plateaus in PPO are caused by outer-loop step sizes that are too large relative to update noise, a problem resolvable by scaling to massive numbers of parallel environments while fixing inner-loop optimization parameters.
Core Problem
Deep RL agents frequently plateau at suboptimal performance levels long before reaching their theoretical potential, rendering extended training budgets (billions/trillions of steps) useless.
Why it matters:
- As simulation hardware improves, training for trillions of steps is feasible, but algorithms currently stagnate early, wasting computational resources
- Existing explanations (plasticity loss, insufficient exploration) do not explain plateaus in dense-reward environments where exploration is not the bottleneck
- Standard hyperparameter tuning strategies fail when scaling up parallelization, often leading to performance degradation
Concrete Example:
In the 'Kinetix' physics domain, standard PPO configurations plateau after less than 10 billion interactions. Even if run for longer, the agent simply thrashes around a suboptimal local optimum without improvement.
Key Novelty
PPO Outer-Loop as Stochastic Optimization
- Models PPO's data collection and update cycle (outer loop) as a stochastic optimization process where the 'step size' is determined by regularization strength and the 'noise' by the batch size
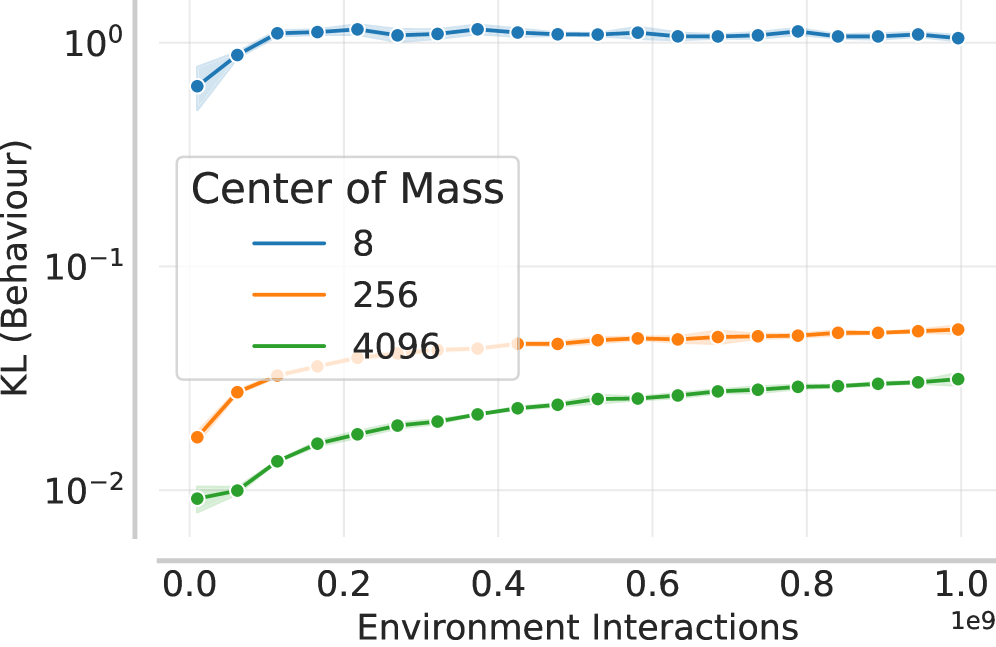
- Demonstrates that increasing parallel environments reduces both step size (via implicitly older behavior policies) and noise (via more data per step), preventing stagnation
- Proposes a scaling recipe: fix the inner loop (minibatch size, learning rate) and only increase optimization steps (epochs) as parallel environments increase
Architecture
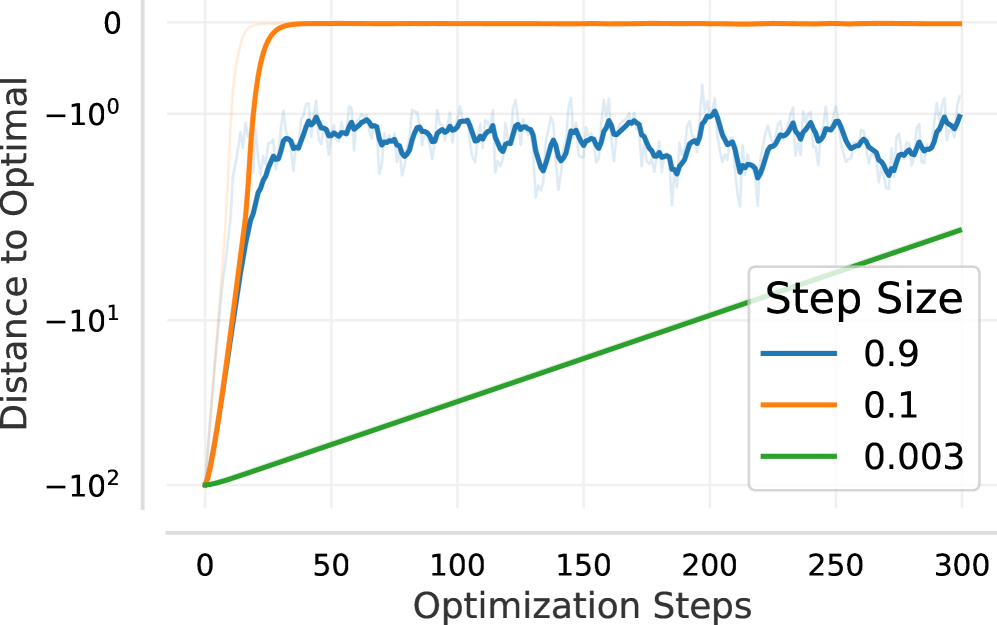
Illustrative comparison of SGD learning rate effects vs. PPO outer-loop step size effects on learning curves.
Evaluation Highlights
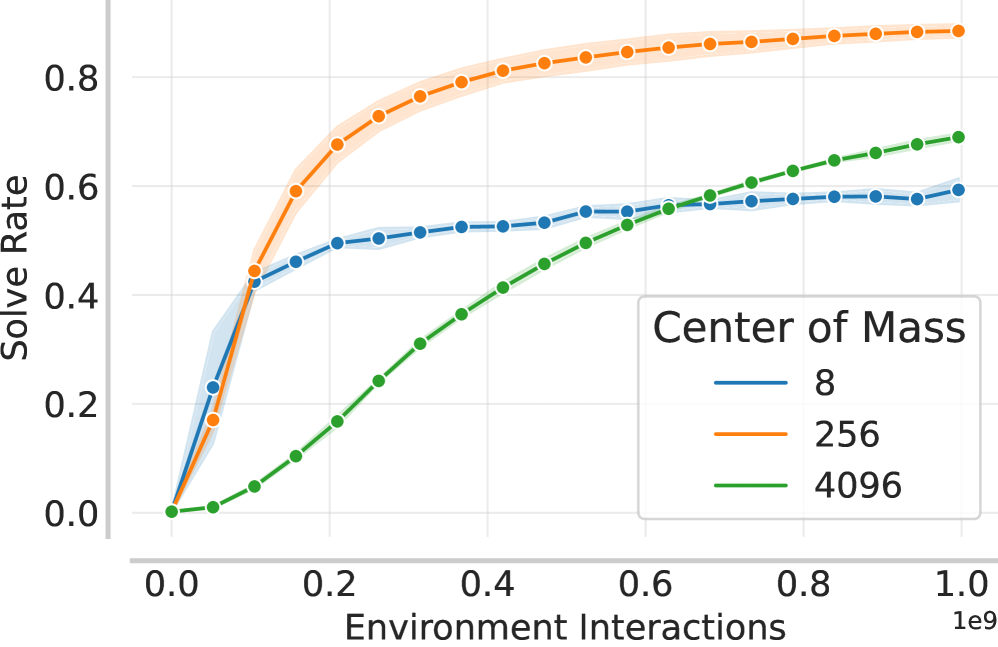
- Scaled PPO to >1,000,000 parallel environments, achieving monotonic performance improvement up to 1 trillion transitions in Kinetix
- Significantly exceeded prior performance ceilings in the Kinetix open-ended domain where standard configurations plateaued <10B steps
- Demonstrated that reducing the outer step size (via increased regularization) allows agents to recover from plateaus and resume learning
Breakthrough Assessment
8/10
Provides a fundamental re-interpretation of PPO plateaus and successfully demonstrates effective scaling to the trillion-step regime, a significant capability jump for on-policy RL.