📝 Paper Summary
Reinforcement Learning (RL)
On-policy algorithms
Exploration strategies
Replacing standard uncorrelated Gaussian noise with temporally correlated colored noise (specifically between white and pink) in PPO significantly improves exploration and learning performance in continuous control tasks.
Core Problem
Standard on-policy algorithms like PPO use uncorrelated white Gaussian noise for exploration, which often fails to generate coherent exploratory behaviors needed for efficient learning in continuous action spaces.
Why it matters:
- Effective exploration is critical for deep reinforcement learning in robotics where state and action spaces are infinite
- Prior work showed correlated noise helps off-policy methods, but on-policy methods like PPO still rely on inefficient uncorrelated noise
- Improving sample efficiency in on-policy methods is valuable because they are more stable and suffer less from distributional shift than off-policy alternatives
Concrete Example:
Consider a robot trying to push an object. With uncorrelated white noise, the robot's actuators jitter randomly around the mean, canceling out movement. With correlated noise, the robot commits to a direction for several steps (e.g., pushing forward consistently), leading to meaningful interaction with the object.
Key Novelty
Colored Noise Exploration for On-Policy RL
- Integrate temporally correlated noise (colored noise) directly into the stochastic policy of PPO using the re-parameterization trick, replacing standard white noise
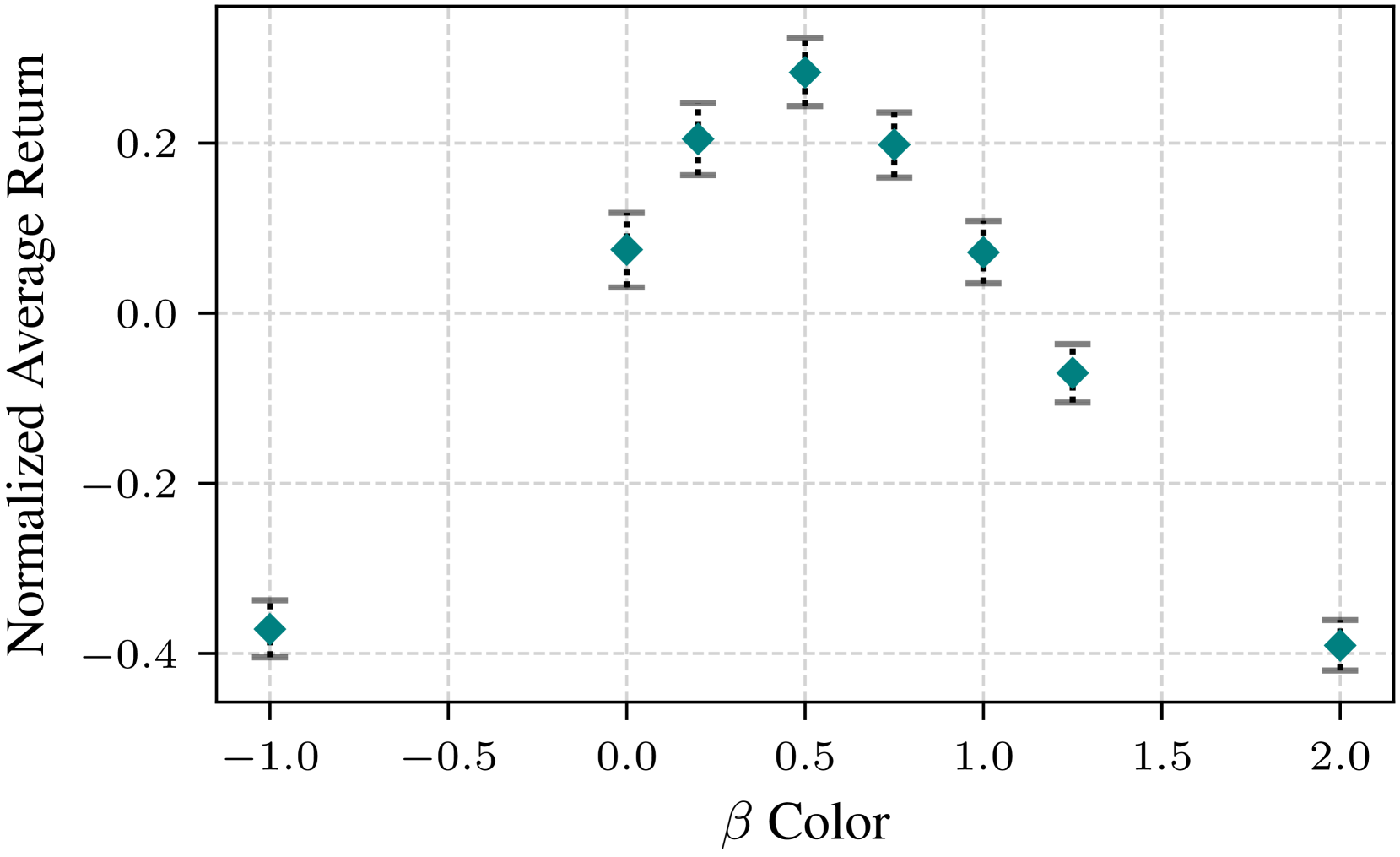
- Identify an optimal noise color (beta=0.5, between white and pink) specifically for on-policy learning, distinct from the pink noise preference found in off-policy settings
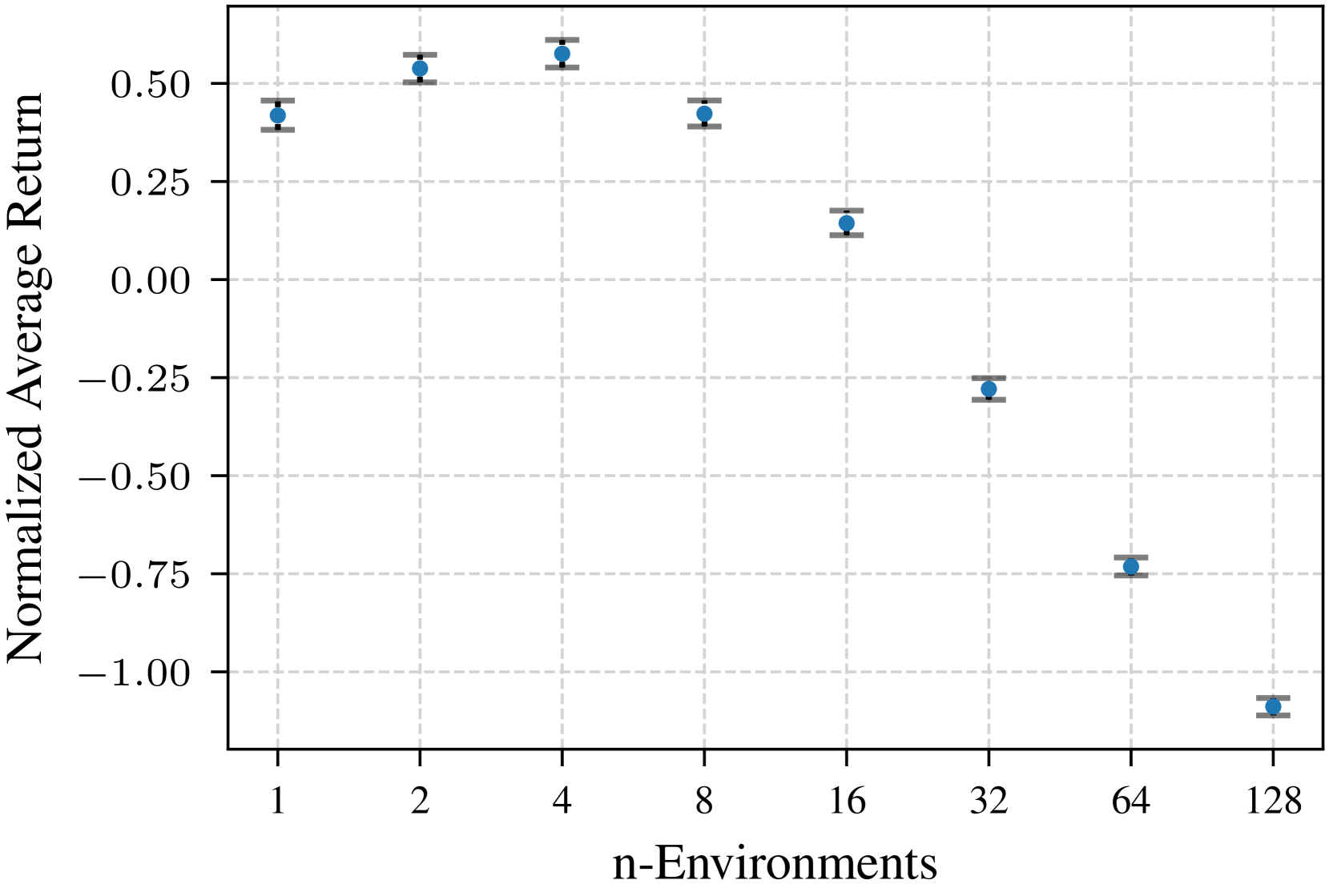
- Establish a relationship between the number of parallel data collection environments and the optimal noise correlation strength
Architecture
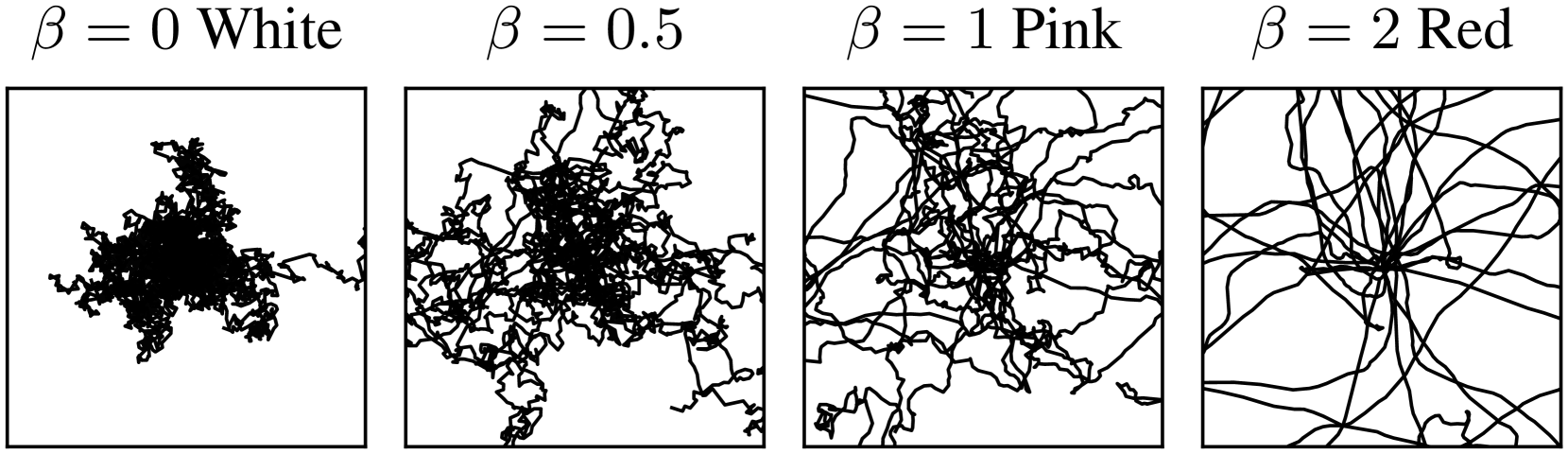
Conceptual illustration of colored noise vs. white noise in trajectory space and distribution space.
Evaluation Highlights
- Correlated noise with beta=0.5 outperforms standard white noise (beta=0) in 8 out of 16 continuous control benchmarks
- Beta=0.5 achieves comparable performance to the best environment-specific noise setting in 11/16 environments, making it a robust default
- Increasing parallel data collection environments requires more strongly correlated noise to maintain performance, though 4 parallel environments with beta=0.5 was found most efficient overall
Breakthrough Assessment
7/10
Simple yet effective modification to a standard algorithm (PPO) that yields consistent improvements. It successfully transfers insights from off-policy to on-policy RL with distinct findings regarding optimal noise color.