📝 Paper Summary
Reinforcement Learning
Policy Optimization
Representation Learning
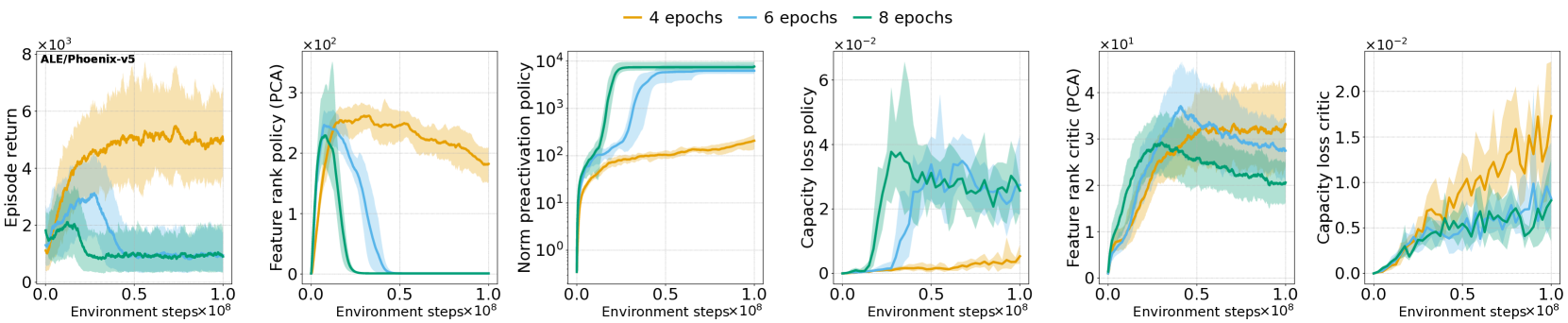
PPO agents suffer from performance collapse because non-stationarity degrades feature rank, rendering the trust region mechanism ineffective; regularizing feature dynamics prevents this failure.
Core Problem
Deep RL networks trained under non-stationarity lose plasticity (ability to learn) and suffer representation collapse, causing performance to degrade irrecoverably.
Why it matters:
- Neural networks in continuous learning settings eventually stop learning or diverge, limiting long-term training
- Standard trust region mechanisms (like PPO clipping) fail to prevent this collapse when representations degrade
- Prior work identified this in off-policy value-based methods, but the connection to on-policy trust region failure was unknown
Concrete Example:
In Atari or MuJoCo environments, a PPO agent might improve initially, but as its internal features collapse to a lower rank, the clipping mechanism fails to constrain updates effectively, causing the policy's performance to suddenly crash to zero.
Key Novelty
Proximal Feature Optimization (PFO)
- Identifies a causal link between feature rank collapse (loss of representation diversity) and the failure of PPO's trust region (clipping mechanism)
- Proposes PFO as an auxiliary loss that regularizes the change in the network's pre-activations (features) to maintain plasticity and ensure the trust region remains effective
Architecture
Pseudocode for PPO-Clip training loop
Evaluation Highlights
- First empirical demonstration that on-policy PPO agents in Atari and MuJoCo suffer from the same feature rank collapse and capacity loss previously observed in value-based methods
- Establishes that PPO's clipping mechanism becomes ineffective under poor representations, leading to performance collapse regardless of critic quality
- Demonstrates that regularizing representation dynamics (via PFO) prevents both feature collapse and performance collapse
Breakthrough Assessment
8/10
Significantly deepens understanding of why PPO fails in long runs by connecting representation theory to trust region mechanics. Proposed solution (PFO) addresses a fundamental instability in deep RL.