📝 Paper Summary
Policy Gradient Methods
Advantage Estimation
AM-PPO stabilizes reinforcement learning by dynamically rescaling and gating advantage estimates using an adaptive controller that responds to evolving signal statistics like norm and variance.
Core Problem
Raw advantage estimates in PPO often exhibit significant variance, noise, and scale issues, which can destabilize gradient updates and hinder efficient policy learning.
Why it matters:
- High variance in advantage signals leads to unstable policy updates and brittle training performance in continuous control tasks
- Fixed scaling or simple normalization techniques (like standard GAE) may not adapt well to the changing statistical properties of the learning signal throughout training
- Optimization landscapes in RL are often ill-conditioned, and poor advantage scaling exacerbates this, slowing down convergence
Concrete Example:
In a continuous control task, if a raw advantage estimate is excessively large due to noise, standard PPO might make a destructive policy update even with clipping. AM-PPO's gating mechanism would detect this saturation and scale down the signal, preventing the instability.
Key Novelty
Adaptive Advantage Modulation Controller
- Introduces a dynamic 'alpha' controller that monitors the statistics (L2 norm, standard deviation) of advantage batches during training
- Applies a non-linear gating function (tanh-based) to the advantages, scaled by an adaptively evolving factor that targets a specific saturation level
- Uses these modulated advantages not just for the policy update, but also as the regression target for the value function, ensuring consistency between actor and critic learning
Architecture
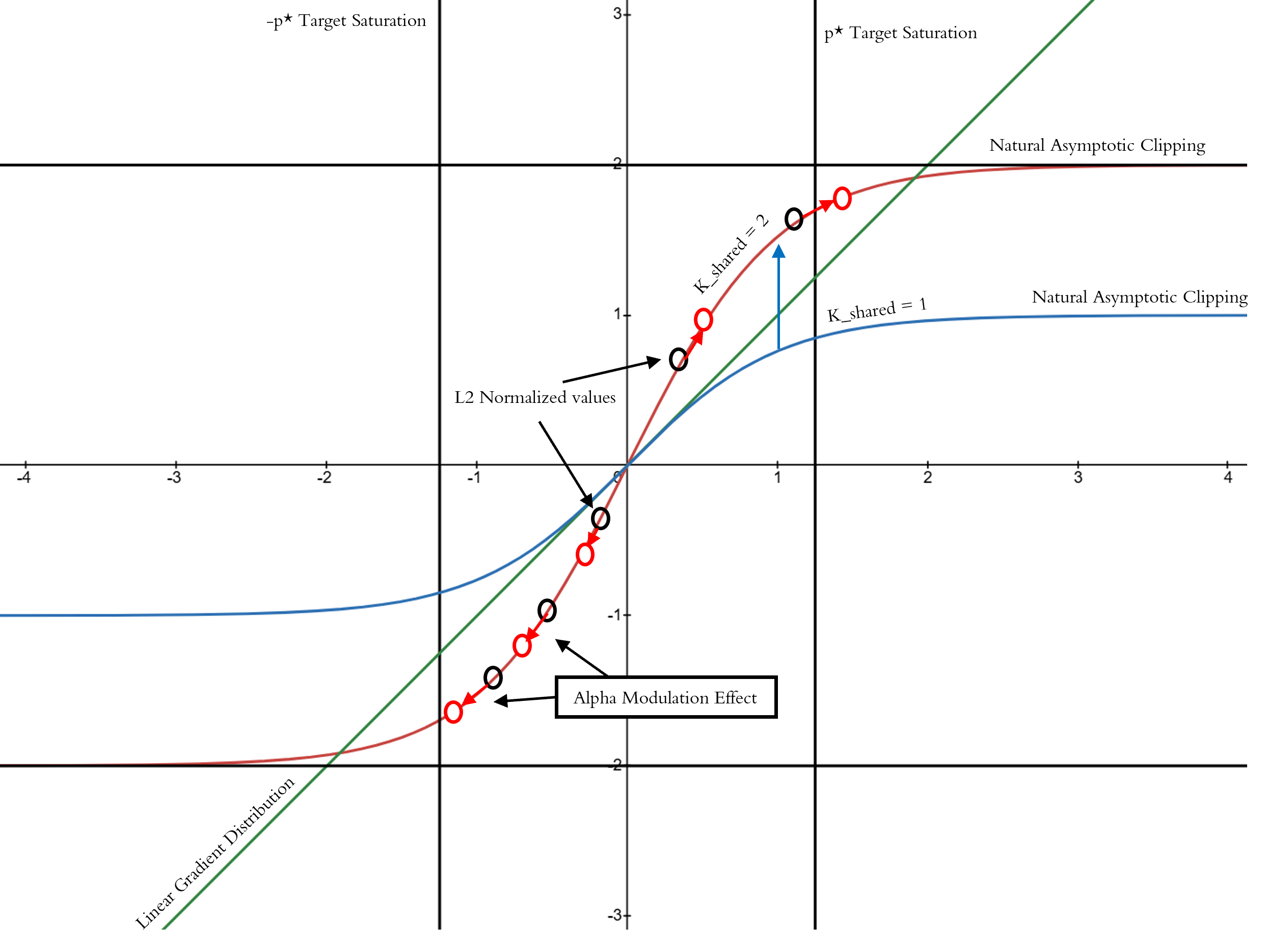
Mathematical visualization of the alpha modulation controller's effect on normalized values
Evaluation Highlights
- Achieves superior reward trajectories compared to standard PPO across standard continuous control benchmarks
- Significantly reduces the clipping rate required by adaptive optimizers, indicating a more stable optimization process
- Demonstrates sustained learning progression where standard PPO might plateau or destabilize
Breakthrough Assessment
7/10
Proposes a theoretically grounded modulation mechanism that addresses a core instability in PPO. While empirical results are described as superior, the paper is a preprint with limited visible benchmark data in the provided text.