📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Chain of Thought (CoT) Reasoning
Large Language Model (LLM) Post-training
VC-PPO stabilizes Proximal Policy Optimization (PPO) for long chain-of-thought tasks by pre-training the value model and decoupling advantage estimation parameters to fix reward signal decay.
Core Problem
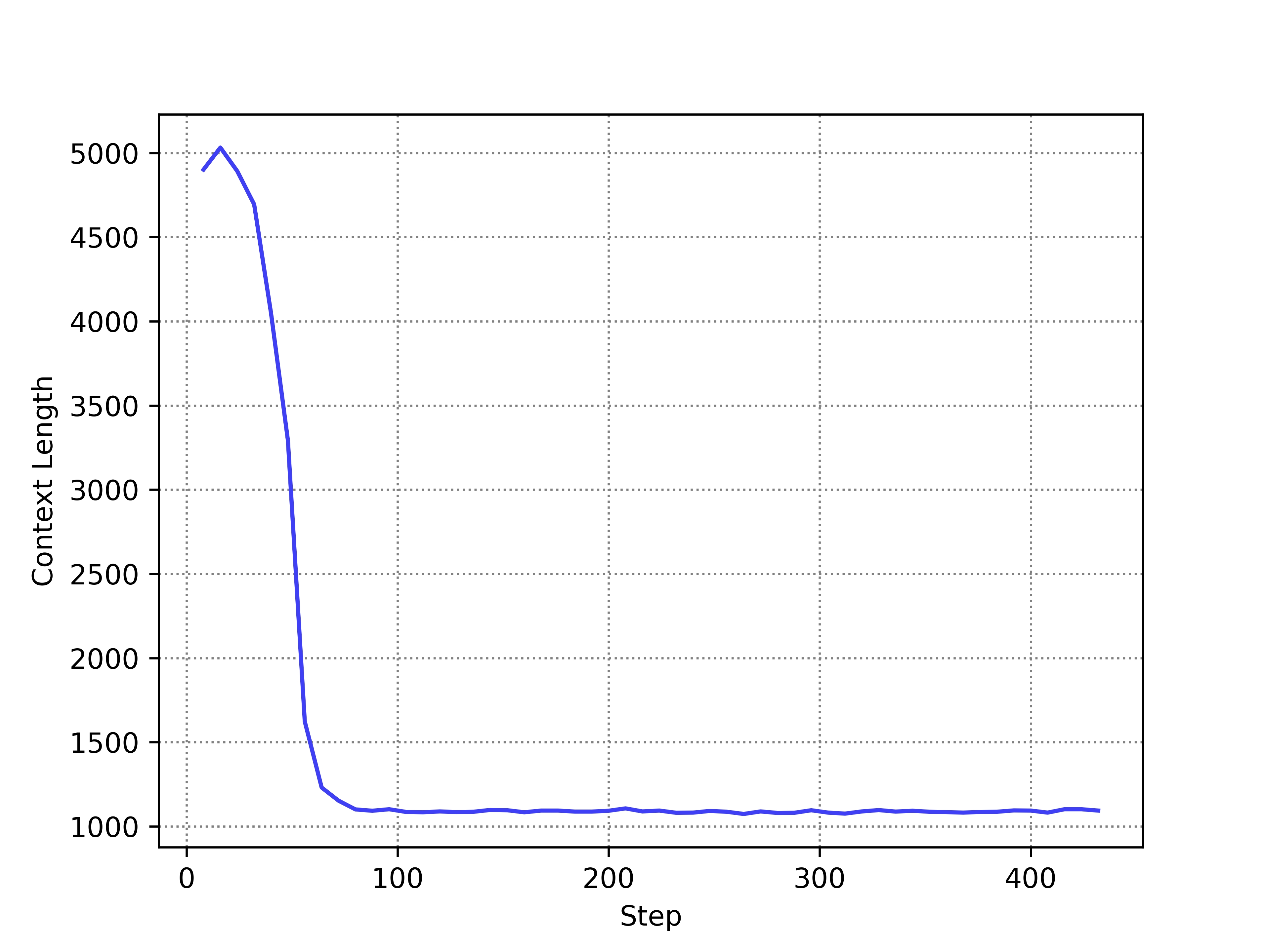
Standard PPO fails in long Chain-of-thought (CoT) tasks because the value model is biased, leading to inaccurate advantage estimation and a collapse in output length.
Why it matters:
- Current RLHF methods like PPO struggle with the long reasoning chains required for complex math problems, often degrading into short, incorrect answers
- Alternative methods like GRPO lack PPO's fine-grained token-level feedback, potentially limiting exploration efficiency in complex tasks
- The standard practice of initializing the value model from the reward model creates immediate bias, while standard GAE parameters cause reward signals to vanish over long sequences
Concrete Example:
When training on math problems, standard PPO rapidly shortens the model's response length (e.g., from thousands of tokens to very few) early in training. This happens because the value model underestimates the value of early tokens in long sequences due to discount factor decay, causing the policy to view early reasoning steps as having low advantage.
Key Novelty
Value-Calibrated PPO (VC-PPO)
- Pre-trains the value model on SFT data to eliminate the 'cold-start' bias caused by initializing it from a reward model that only scores end-of-sentence tokens
- Decouples Generalized Advantage Estimation (GAE) parameters: uses a discount factor of 1.0 for the value target to prevent signal decay over long chains, while keeping a lower factor for the policy to maintain stability
Architecture
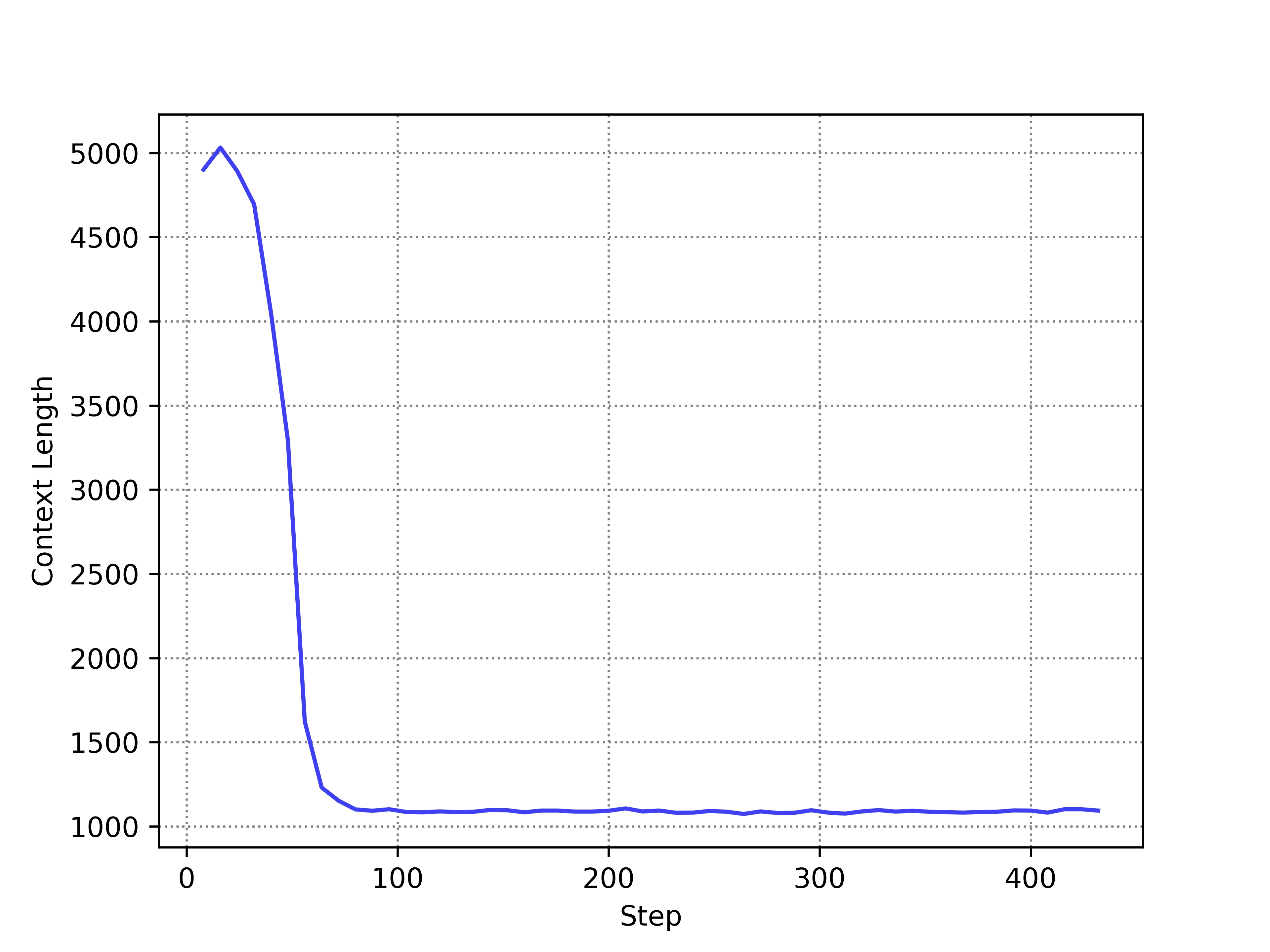
Comparison of PPO vs VC-PPO performance and length during training
Evaluation Highlights
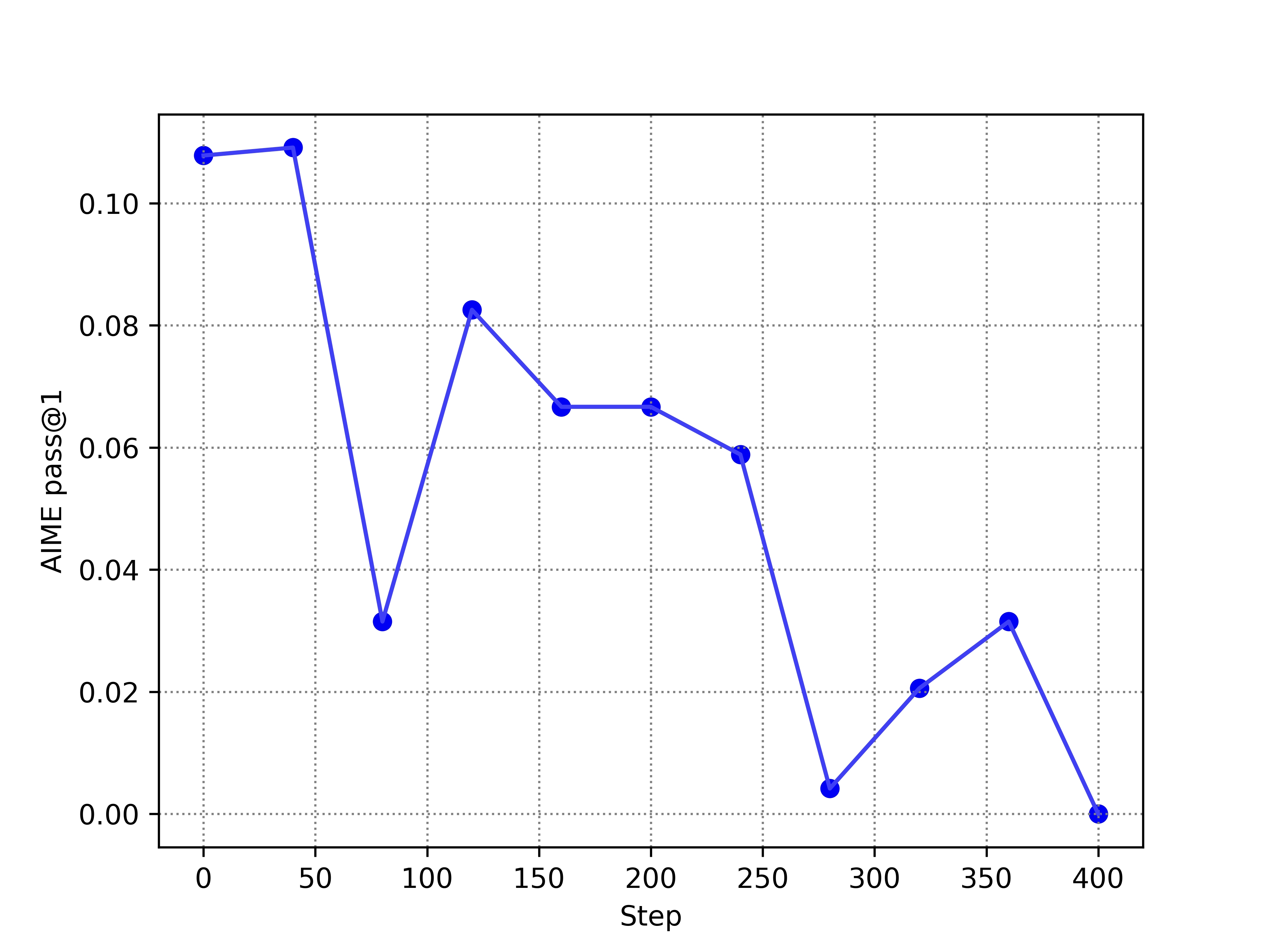
- Achieves 49.0% accuracy on the AIME benchmark, significantly outperforming standard PPO which collapses to 5.6%
- Surpasses the DeepSeek-R1-Zero reproduction result of 39.0% on AIME reported in previous literature
- Maintains stable output lengths (reasoning chains) throughout training, avoiding the length collapse observed in baseline PPO
Breakthrough Assessment
8/10
Identifies and fixes a critical, specific failure mode of PPO in the high-impact area of Long-CoT reasoning. The solution is theoretically grounded and yields massive empirical gains.