📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
LLM Alignment
Reward-based vs. Reward-free optimization
PPO consistently outperforms DPO in challenging tasks like code generation when key implementation factors (advantage normalization, large batch size, EMA) are properly tuned, due to DPO's susceptibility to out-of-distribution shifts.
Core Problem
While DPO achieves state-of-the-art results on simple academic benchmarks, it often underperforms reward-based methods (PPO) in complex real-world applications and challenging tasks.
Why it matters:
- Top industry models (ChatGPT, Claude) rely on PPO, yet academic research is shifting toward DPO, creating a disconnect between theory and practice.
- Understanding the limitations of reward-free methods is crucial for aligning models on complex tasks where distribution shifts between preference data and model outputs are significant.
- Incorrectly assuming DPO is superior may lead to suboptimal alignment strategies for logic-heavy domains like coding.
Concrete Example:
In a synthetic experiment, when the preference dataset covers only a subset of responses (e.g., y1 vs y2), DPO can assign artificially high probability to an unseen, out-of-distribution response (y3) because it lacks the explicit KL regularization against a reference model that PPO enforces on generated data.
Key Novelty
Theoretical proof of DPO's OOD vulnerability + PPO implementation best practices
- Theoretically proves that the set of solutions found by PPO is a proper subset of DPO, meaning DPO can find 'optimal' solutions that exploit out-of-distribution data (biasing unseen responses) which PPO avoids via explicit regularization.
- Identifies critical implementation details for PPO (advantage normalization, large batch sizes, EMA) often missed in academic baselines, allowing it to surpass DPO.
Architecture
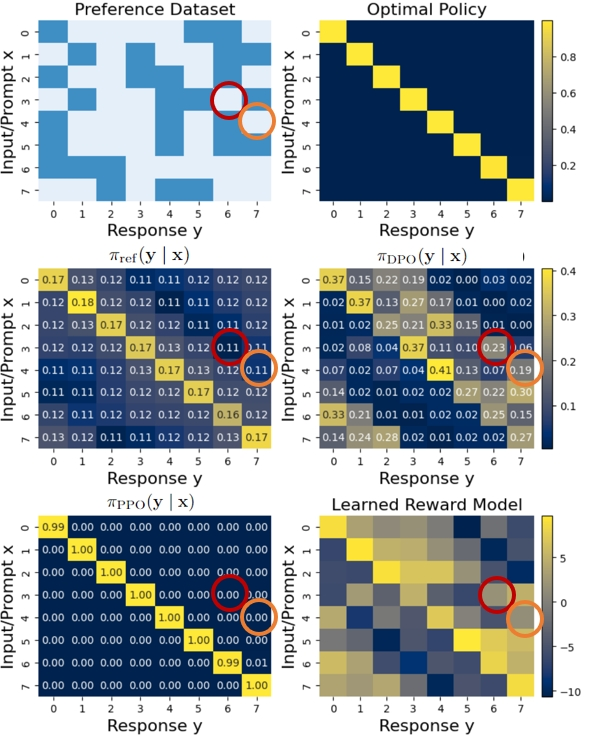
A synthetic experiment visualization showing probability distributions of responses.
Evaluation Highlights
- PPO achieves state-of-the-art results on the CodeContest dataset with a 34B model, improving pass@1k from 16.4% to 22.4%, outperforming AlphaCode-41B.
- On the SafeRLHF dataset, resolving distribution shift improves DPO safety rate by 16.4%, but PPO still outperforms DPO in helpfulness rewards.
- PPO consistently surpasses DPO across diverse testbeds ranging from dialogue to challenging code generation competitions.
Breakthrough Assessment
8/10
Provides a strong counter-narrative to the prevailing trend of preferring DPO, backed by theoretical proofs and SOTA empirical results on hard tasks (coding).