📝 Paper Summary
Text-to-3D Generation
Reinforcement Learning for Generative Models
This paper introduces Hi-GRPO, a hierarchical reinforcement learning framework for text-to-3D generation that optimizes global geometry and local textures sequentially using ensemble rewards, alongside a new reasoning-focused benchmark.
Core Problem
Applying reinforcement learning to 3D generation is difficult because 3D assets have high spatial complexity, require global geometric consistency, and lack canonical viewpoints for reward evaluation.
Why it matters:
- Current text-to-3D models struggle with complex prompts involving spatial relations or specific mechanical functions, relying on memorization rather than reasoning
- Directly applying 2D RL techniques (like DPO or standard GRPO) to 3D fails because single-step optimization cannot handle the coupled nature of 3D geometry and texture
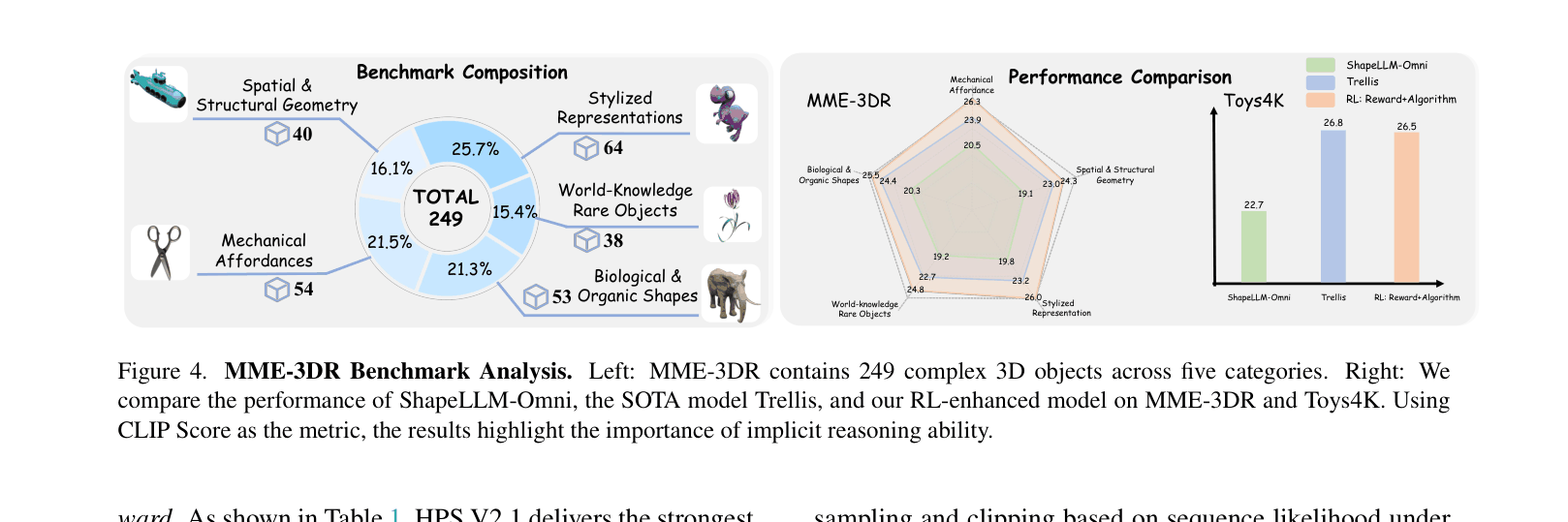
- Existing benchmarks focus on object diversity but fail to measure implicit reasoning capabilities like understanding 'mechanical affordances' or 'spatial geometry'
Concrete Example:
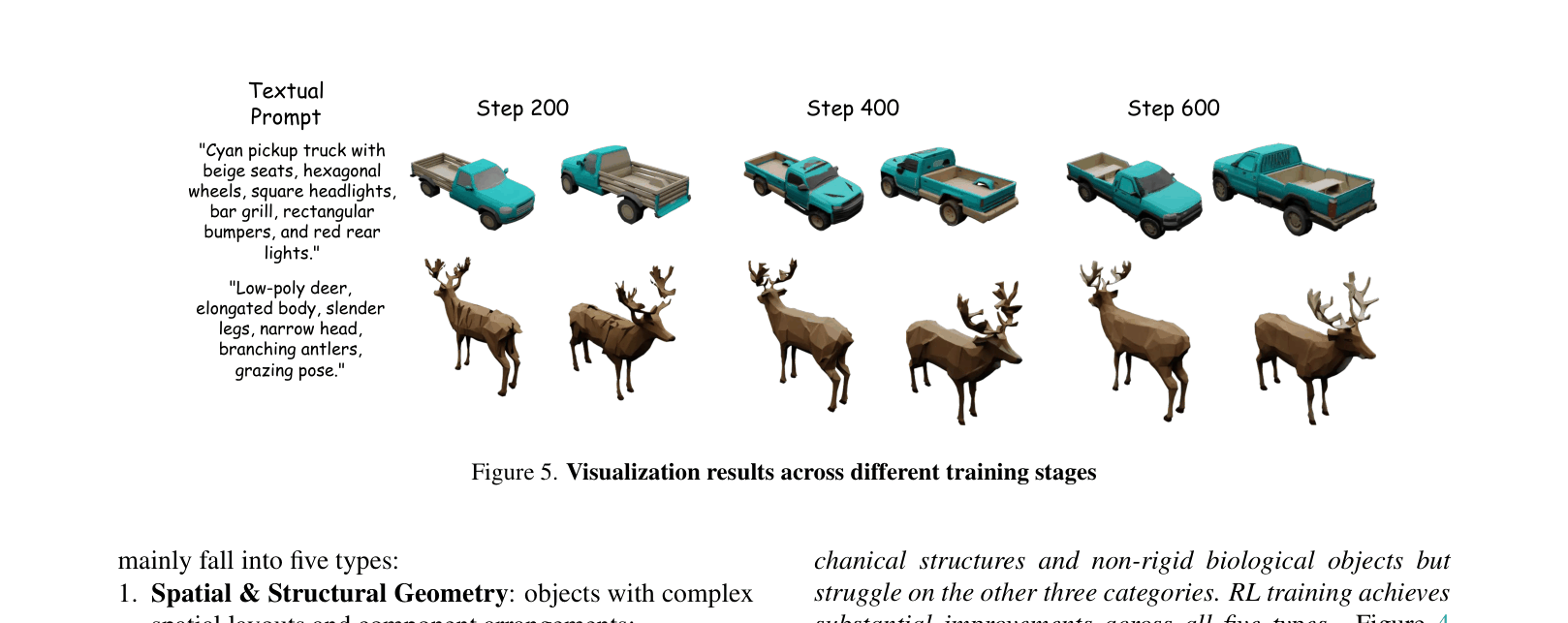
For a prompt like 'Stylized flower with gradient pink petals,' standard models might generate a generic flower shape. Without hierarchical planning, they fail to align the specific gradient texture with the petal geometry, or miss structural details like the stamen placement, as seen in early training stages where only rough blobs appear.
Key Novelty
Hierarchical Group Relative Policy Optimization (Hi-GRPO)
- Decomposes 3D generation into two RL steps within a single iteration: (1) global semantic planning for coarse shape, and (2) local visual reasoning for texture refinement
- Uses a specialized ensemble of reward models (Human Preference, Unified Aesthetic, 2D/3D LMMs) tailored to each step to guide geometry and appearance separately
Architecture
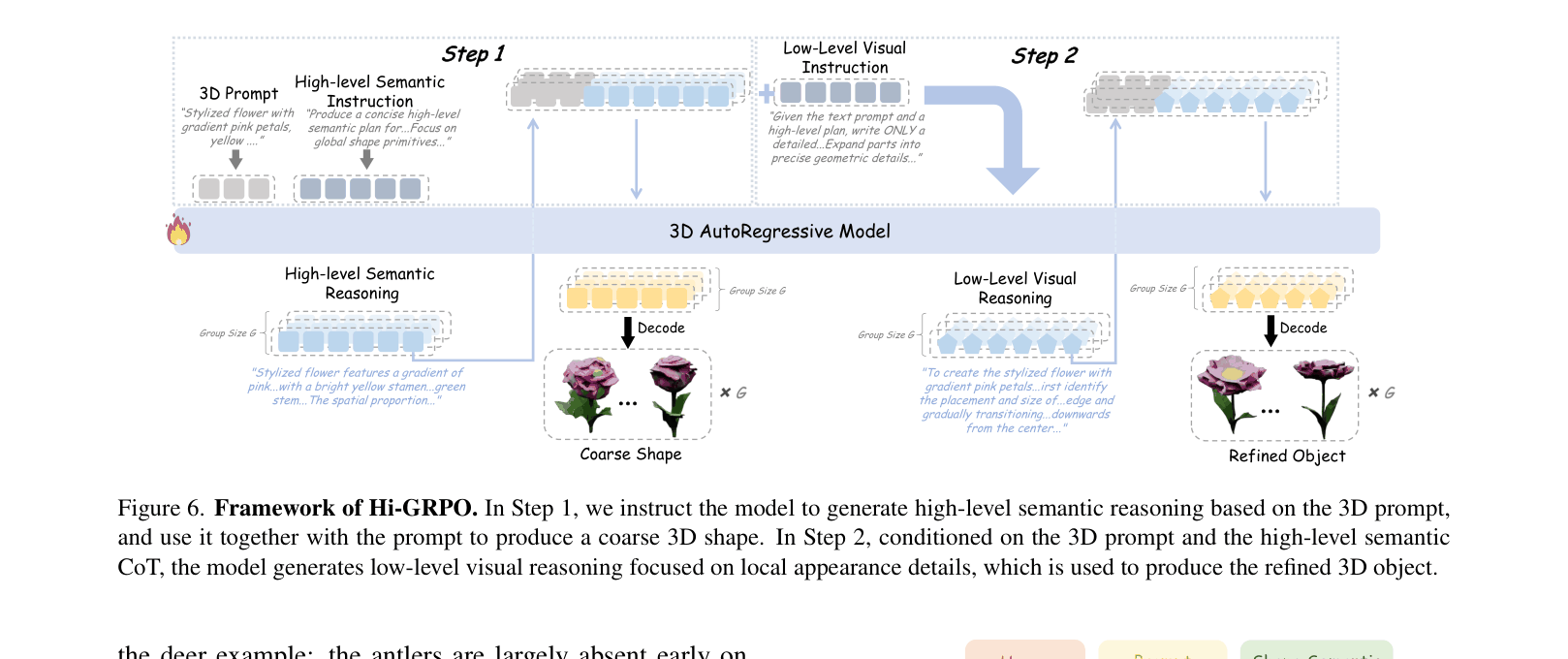
The Hi-GRPO framework illustrating the two-step generation process: (1) Text -> Semantic Reasoning -> Coarse 3D, followed by (2) Text + Semantic -> Visual Reasoning -> Refined 3D.
Evaluation Highlights
- AR3D-R1 achieves 28.5 CLIP Score on the new MME-3DR benchmark, outperforming the state-of-the-art Trellis model (23.4) and base ShapeLLM-Omni (19.8)
- On the standard Toys4K dataset, AR3D-R1 improves CLIP Score to 29.3 compared to ShapeLLM-Omni's 22.7 (+6.6 points)
- RL training specifically improves performance on 'Stylized Representation' objects by ~6 points, demonstrating enhanced abstract reasoning capabilities
Breakthrough Assessment
8/10
First systematic study and successful application of RL to autoregressive text-to-3D generation. The hierarchical approach and new benchmark address fundamental reasoning gaps in 3D generation.