📊 Experiments & Results
Evaluation Setup
Mathematical and logical reasoning tasks evaluated via pass@1 accuracy
Benchmarks:
- MATH (Hard Mathematical Reasoning)
- GSM8K (Grade School Math)
- HeadQA (Healthcare/Medical QA)
- DeepScaler (Math reasoning (iterative))
Metrics:
- Oracle Performance Gap (OPG)
- pass@1 Accuracy
- Average Cross-Difficulty Generalization
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Oracle Performance Gap (OPG) analysis showing the collapse of generalization in RL compared to SFT. | ||||
| MATH | OPG | 0.197 | 0.015 | -0.182 |
| GSM8K | OPG | 0.038 | 0.002 | -0.036 |
| Counterfactual Robustness tests measuring reliance on memorized rules vs. deductive reasoning. | ||||
| MATH (Modified) | Accuracy | 74.8 | 41.2 | -33.6 |
| MATH (Modified) | Accuracy | 64.2 | 36.0 | -28.2 |
| Distributional shift analysis showing specialized models fail on OOD data. | ||||
| MATH (OOD Partition) | Accuracy | 57.5 | 51.2 | -6.3 |
Experiment Figures
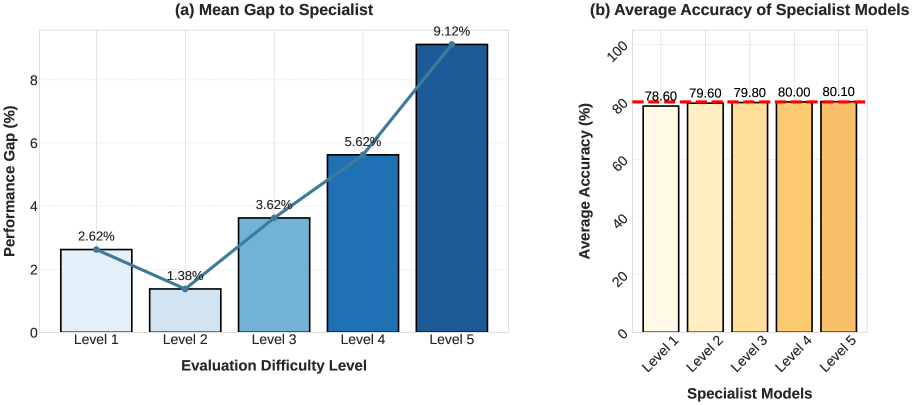
Comparison of specialist models trained on specific difficulty levels (L1-L5) evaluated on Difficulty-Stratified vs. Average metrics
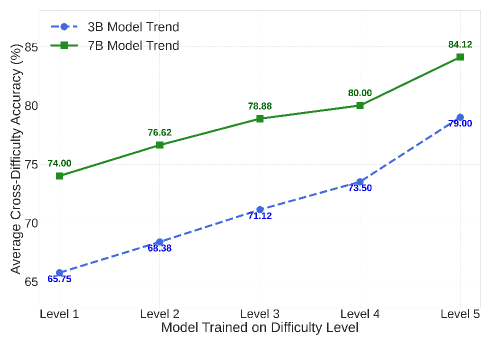
Average Cross-Difficulty Generalization scores plotted against training difficulty level
Main Takeaways
- The 'Unseen' Assumption Fails for RL: Unlike SFT, RL models optimize the metric so aggressively that 'unseen' test data offers no greater challenge than training data, rendering standard train/test splits insufficient for measuring progress.
- Difficulty Asymmetry: Models trained on hard problems generalize to easy ones, but models trained on easy problems fail on hard ones. Yet, average benchmark scores mask this distinction.
- Fragile Reasoning: High benchmark scores in RL often reflect overfitting to the distribution; when semantic distance increases (OOD) or premises change (Counterfactual), performance collapses, sometimes below the base model.