📝 Paper Summary
Offline Reinforcement Learning
In-Context Learning
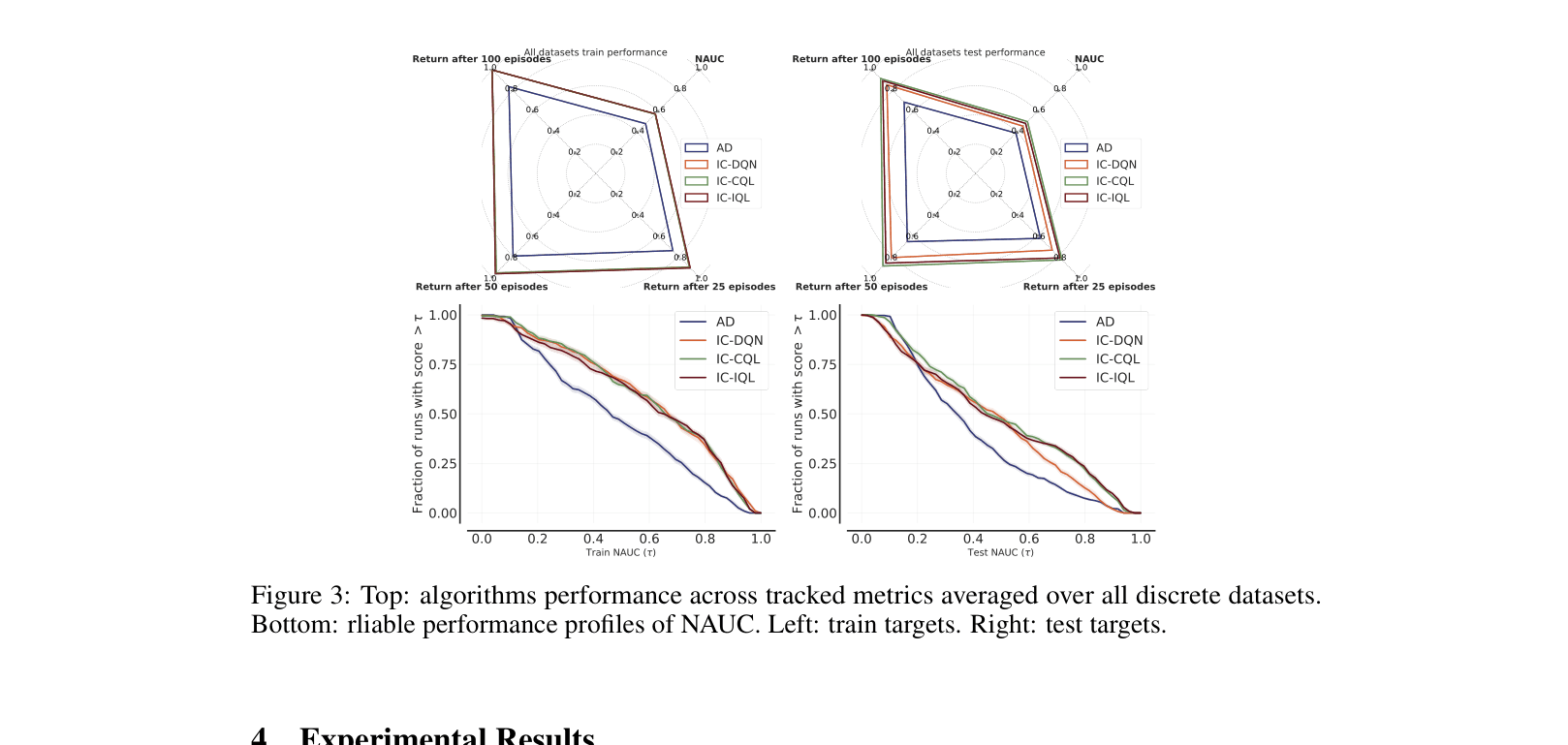
Replacing the supervised learning objective in Algorithm Distillation with explicit offline RL objectives (like CQL and IQL) significantly improves in-context learning performance, especially on suboptimal datasets.
Core Problem
Existing offline In-Context RL methods like Algorithm Distillation (AD) rely on supervised learning, which mimics behavior rather than maximizing reward, failing when datasets are suboptimal or unstructured.
Why it matters:
- Offline datasets often contain suboptimal or unstructured trajectories, making pure imitation (supervised learning) ineffective for deriving optimal policies
- Real-world applications (robotics, healthcare) require offline pre-training for safety but need agents that can improve over the data, not just copy it
- Current methods struggle without 'learning histories' (sequences of improving policies), which are rarely available in practice
Concrete Example:
When trained on 'early' (low-quality) datasets where an agent has not yet learned to solve the task, standard Algorithm Distillation (AD) achieves a normalized score of < 0.4 because it clones the bad behavior. In contrast, the proposed RL-based method (IC-DQN) extracts better policies from the same data, achieving significantly higher scores.
Key Novelty
Offline In-Context RL with Explicit Value Optimization
- Replace the next-token prediction head of a Transformer with value function heads (Q-values) to explicitly maximize expected return rather than just predicting the next action
- Incorporate offline RL regularizations (like conservatism in CQL) directly into the in-context learning framework to handle out-of-distribution actions and suboptimal data
Architecture
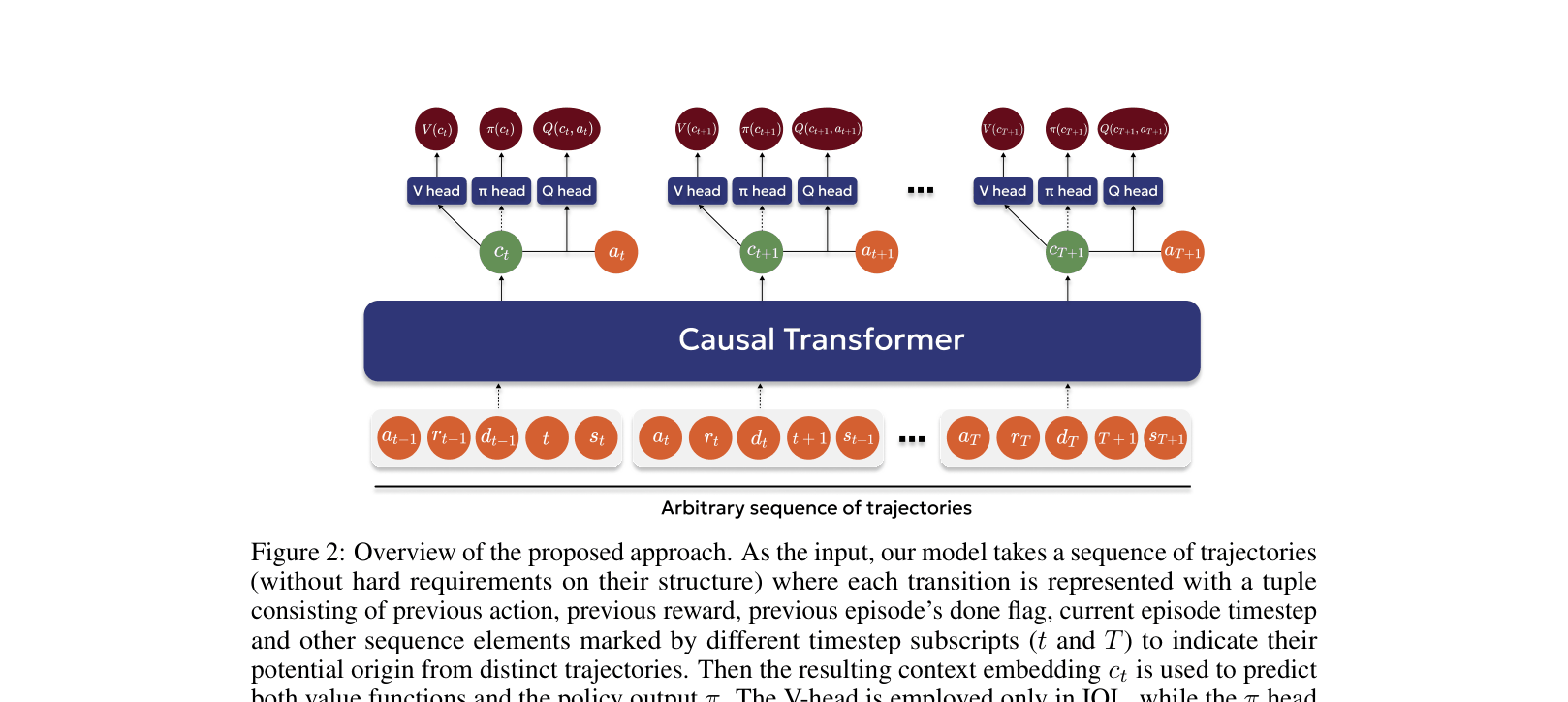
The proposed architecture for RL-based Offline ICRL.
Evaluation Highlights
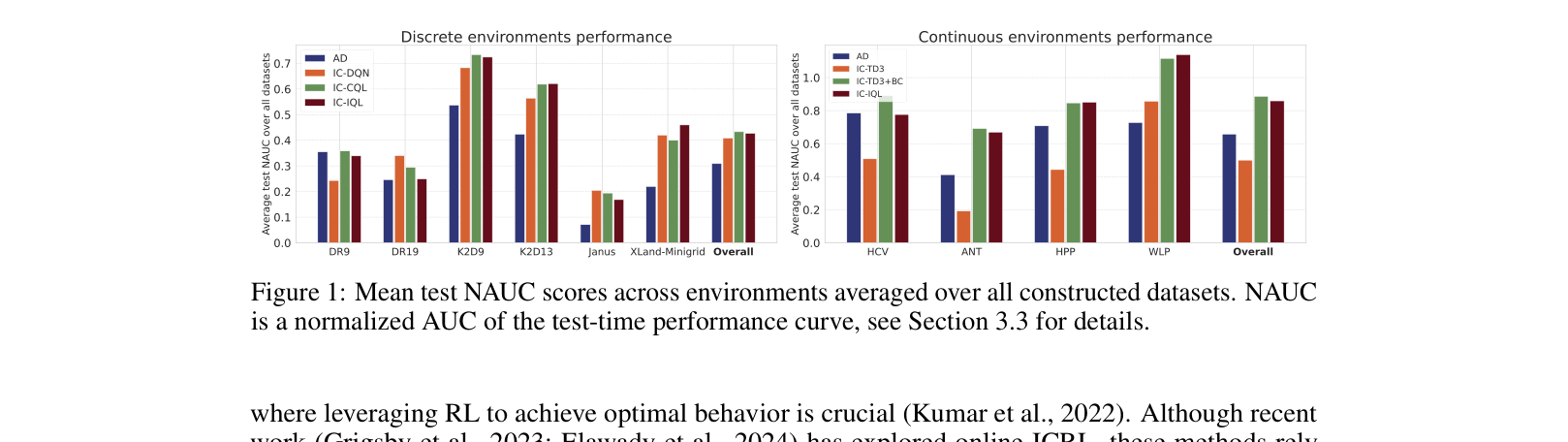
- +28.8% average improvement on test targets in discrete environments compared to Algorithm Distillation (AD) using Conservative Q-Learning (IC-CQL)
- Doubled performance (0.22 → 0.46 NAUC) on the challenging XLand-MiniGrid environment compared to AD when using Implicit Q-Learning (IC-IQL)
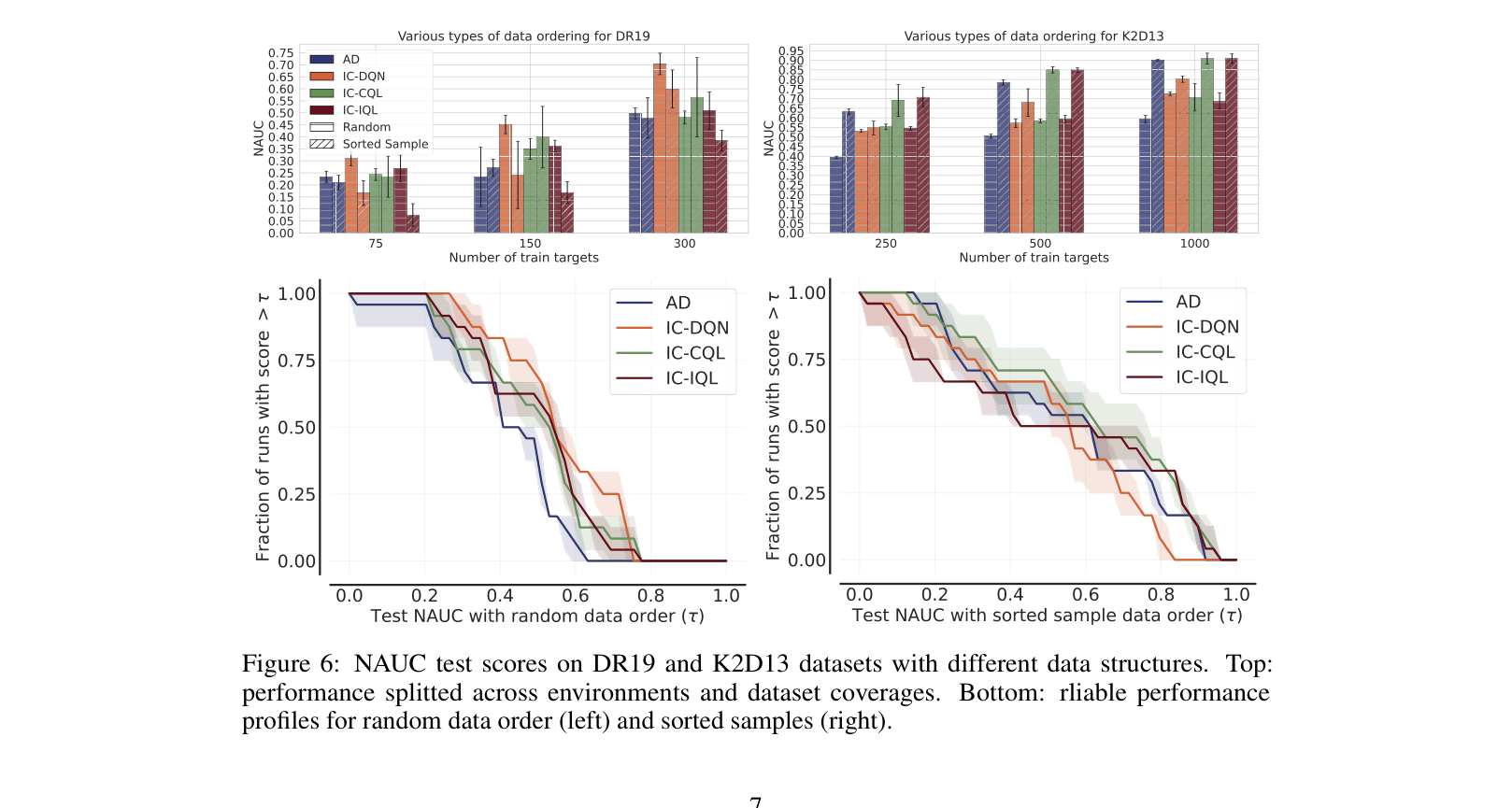
- Strong robustness to random data ordering: RL methods outperform AD when 'learning histories' (sequential improvements) are shuffled or unavailable
Breakthrough Assessment
7/10
Strong empirical evidence across 150+ datasets that explicit RL objectives are superior to supervised learning for offline ICRL. While the architecture is standard, the finding challenges the dominance of decision-transformer-style supervision in this niche.