📝 Paper Summary
Reinforcement Learning for LLMs
Data Efficiency
Reasoning
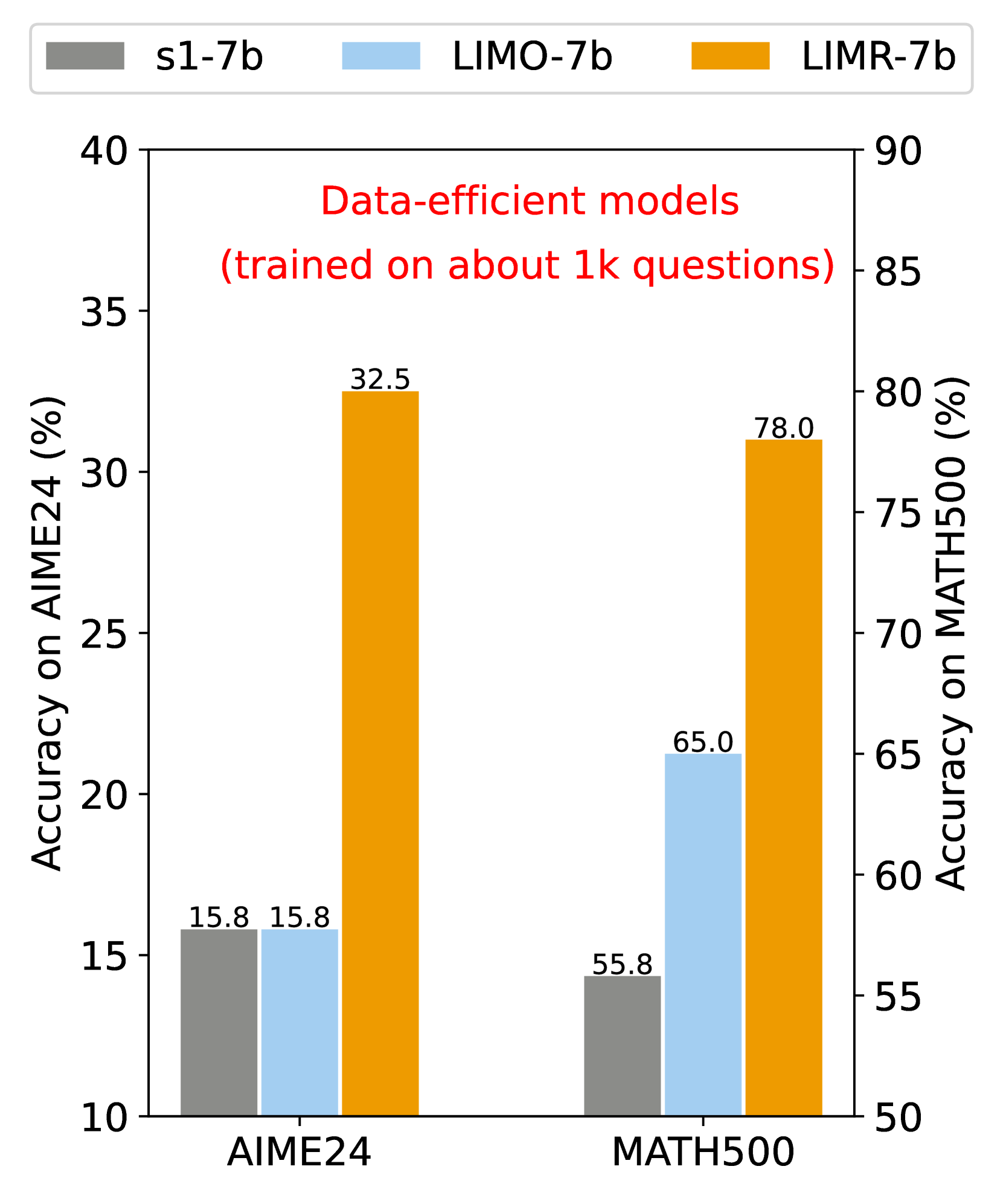
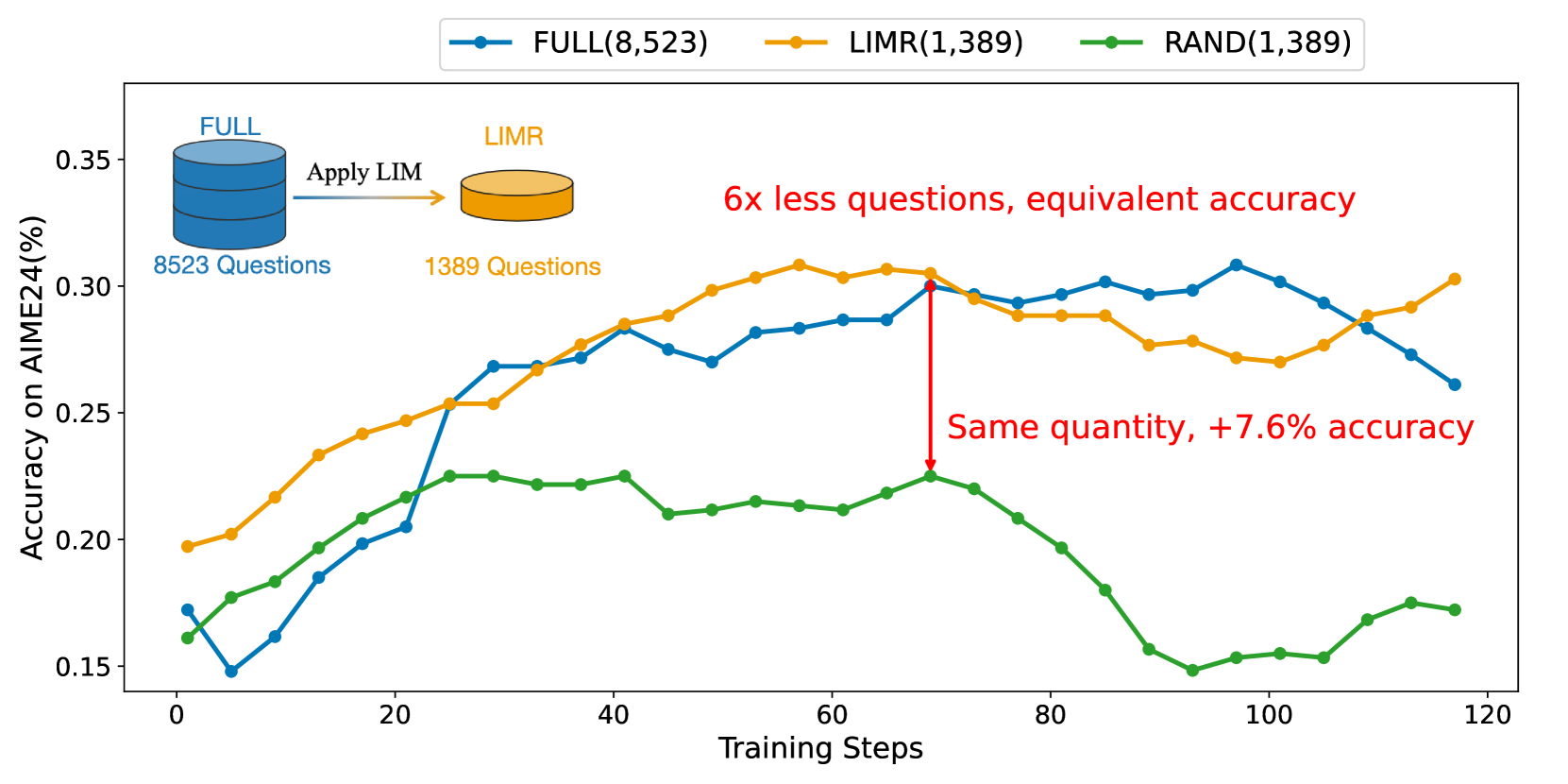
LIMR demonstrates that a small, strategically selected subset of RL training samples (1,389) aligned with model learning trajectories can outperform full datasets (8,523) in enhancing LLM reasoning.
Core Problem
Current RL training for reasoning relies on opaque, large-scale data requirements, leading to inefficient resource use and a lack of understanding about what data actually drives improvement.
Why it matters:
- Scaling up RL training data is computationally expensive and may not yield proportional gains
- Lack of transparency in pioneering works (o1, Deepseek R1) forces researchers to rely on trial-and-error for data scale
- Trial-and-error approaches often miss the critical role of sample quality versus quantity
Concrete Example:
Training a 7B model with the full 8,523-sample MATH dataset uses significant compute, but many samples exhibit flat learning curves or instability. LIMR identifies that only 1,389 of these samples actively drive learning, achieving equal or better performance with 80% less data.
Key Novelty
Learning Impact Measurement (LIM)
- Analyzes individual sample learning trajectories during RL training to identify which samples align with the model's overall improvement curve
- Selects a small subset of 'high-impact' samples based on a computed alignment score, discarding samples that show flat or erratic learning patterns
Architecture
Conceptual diagram of the Learning Impact Measurement (LIM) process and sample selection logic.
Evaluation Highlights
- Achieves 32.5% accuracy on AIME24 with only 1,389 samples, outperforming the full dataset baseline (8,523 samples) and distilled baselines like LIMO (15.8%)
- Matches or exceeds the performance of training on the full MATH dataset (78.0% vs 78.4% on MATH500) despite using ~83% less data
- Surpasses random data selection (MATH-RAND) by ~13-16 percentage points across MATH500, AIME24, and AMC23
Breakthrough Assessment
8/10
Strongly challenges the 'scale is all you need' assumption for RL data. The proposed metric (LIM) is automated and effective, significantly boosting efficiency for 7B-scale models.