📝 Paper Summary
Reinforcement Learning Theory
Sample Complexity Bounds
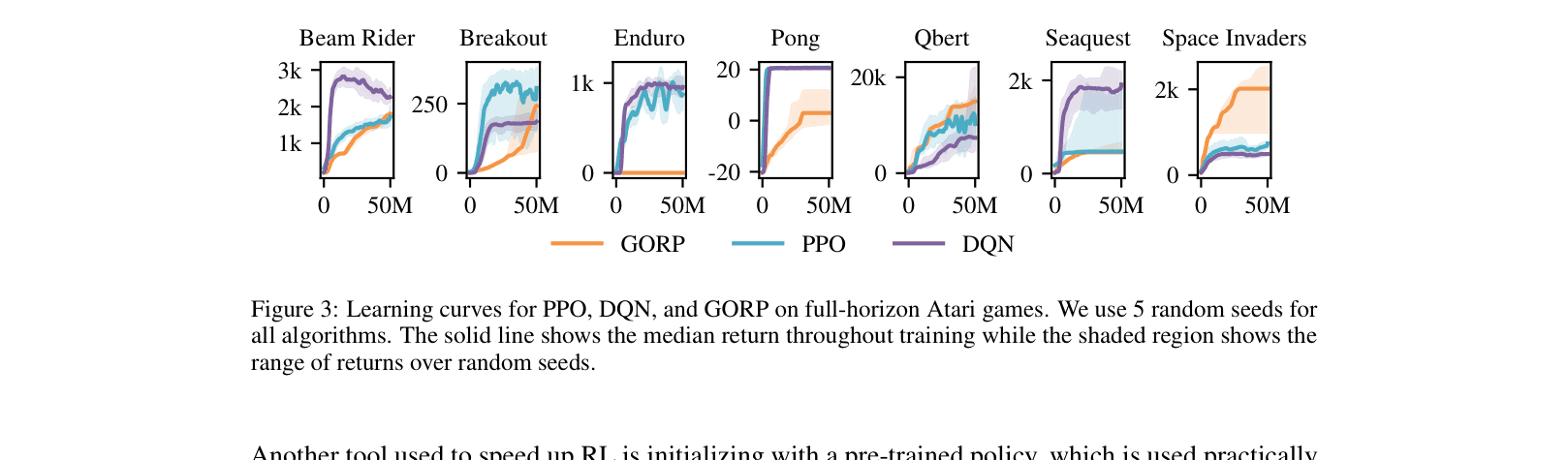
Deep RL Benchmarking
The paper introduces the 'effective horizon', a complexity measure for MDPs that better predicts the empirical success of deep RL algorithms than existing theoretical bounds by modeling greedy planning over random rollouts.
Core Problem
Existing RL theory (worst-case or covering-length bounds) fails to explain why random-exploration Deep RL algorithms succeed in some environments but fail in others.
Why it matters:
- Deep RL is widely used but lacks theoretical guarantees predictive of practical performance
- Current bounds are often vacuous (exponential in horizon T) for environments that are empirically solvable
- Practitioners need to understand when and why tools like reward shaping or pre-training actually help
Concrete Example:
In a dense-reward environment where every optimal action gives reward 1, worst-case theory predicts exponential difficulty (needs to visit all states). In practice, Deep RL solves this easily. The proposed theory explains this discrepancy where prior bounds like covering length do not.
Key Novelty
The Effective Horizon & BRIDGE Dataset
- Identify a property holding in ~2/3 of benchmark MDPs: acting greedily with respect to the random policy's Q-function yields optimal behavior
- Define 'effective horizon' (H) based on a theoretical algorithm (GORP) that estimates this random Q-function using k lookahead steps and m rollouts
- Introduce BRIDGE, a dataset of 155 tabularized deterministic MDPs (Atari, Procgen, MiniGrid), enabling exact calculation of theoretical bounds to compare against empirical Deep RL performance
Architecture
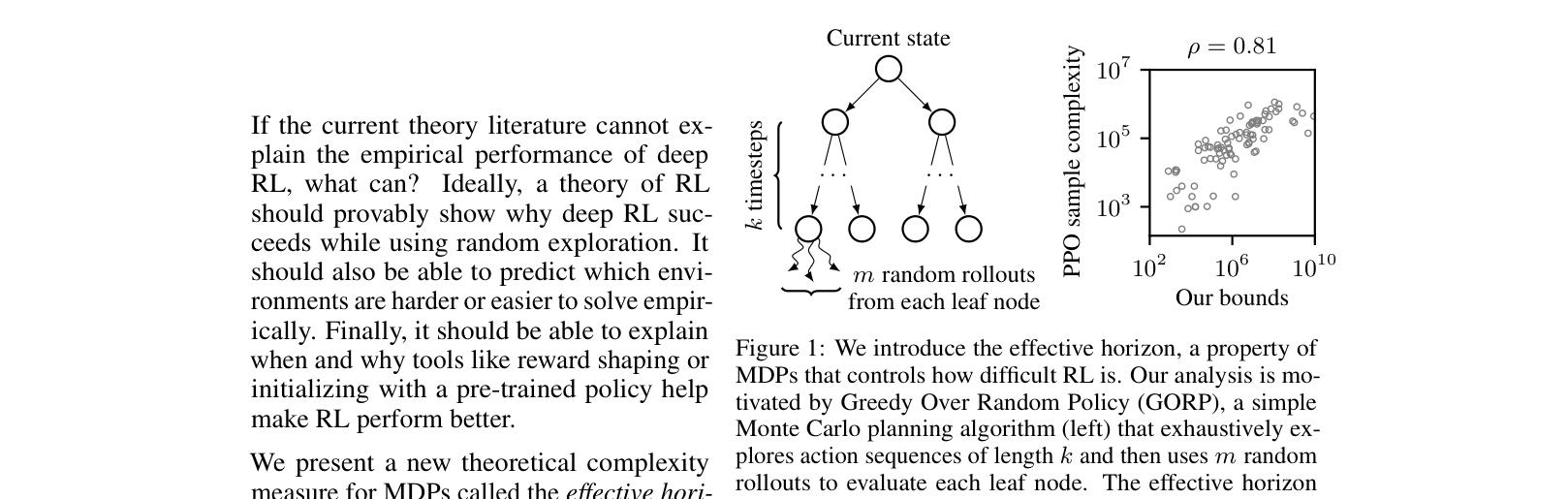
Conceptual illustration of the Effective Horizon via the GORP algorithm compared to PPO performance.
Evaluation Highlights
- Effective horizon bounds achieve 0.81 Spearman correlation with PPO's empirical sample complexity, significantly outperforming covering length (0.35) and worst-case bounds (0.24)
- Effective horizon bounds predict whether PPO will solve an environment with 86% accuracy, compared to 72% for covering length bounds
- Accurately predicts the reduction in sample complexity from reward shaping (0.48 correlation) and pre-training (0.57 correlation), whereas other bounds show near-zero or negative correlation
Breakthrough Assessment
8/10
Significantly narrows the theory-practice gap by validating bounds on real large-scale benchmarks rather than toy problems. The BRIDGE dataset is a major contribution for future theoretical grounding.