📝 Paper Summary
Post-Fine-tuning (Alignment)
On-policy optimization
Evolution Strategy Optimization (ESO) treats language model tuning as an evolutionary process, using gradients from online-generated outputs as directed mutations to align models with reward signals.
Core Problem
Supervised Fine-tuning suffers from exposure bias, while existing post-fine-tuning methods like PPO can be unstable and off-policy methods like DPO are prone to overfitting.
Why it matters:
- Standard fine-tuning creates a mismatch between training (teacher forcing) and inference (autoregressive generation), degrading performance
- Off-policy methods (DPO) can overfit to fixed preference datasets, reducing generalization to new prompts
- Existing on-policy methods (PPO) are computationally expensive and complex to tune due to multiple auxiliary models (critic, reference)
Concrete Example:
In human alignment tasks, a model trained with DPO might produce long, redundant responses to 'hack' the preference data, whereas on-policy methods are needed to explore and penalize such behaviors dynamically.
Key Novelty
Evolution Strategy Optimization (ESO)
- Views parameter updates as evolutionary mutations: instead of random noise, it uses the gradient of generated sentences as 'biased' perturbations
- Quantifies fitness by comparing a sample's reward to the average reward of a population of samples generated online
- Updates model parameters to increase the probability of high-fitness samples relative to the population average
Architecture
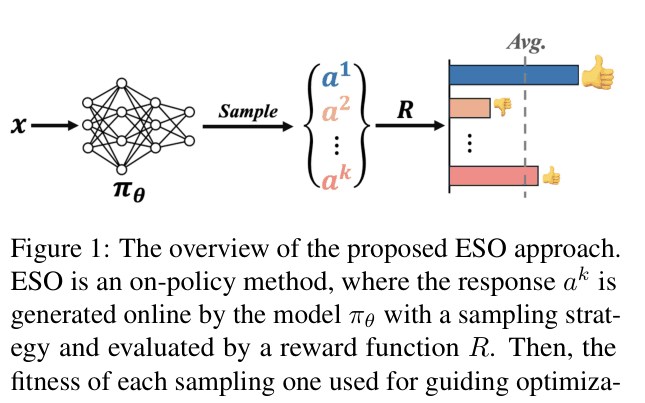
Overview of the Evolution Strategy Optimization (ESO) approach
Evaluation Highlights
- Outperforms standard SFT and on-policy baselines (RRHF, Unlike) on Dolly and Xsum datasets across GPT-2 and OPT architectures
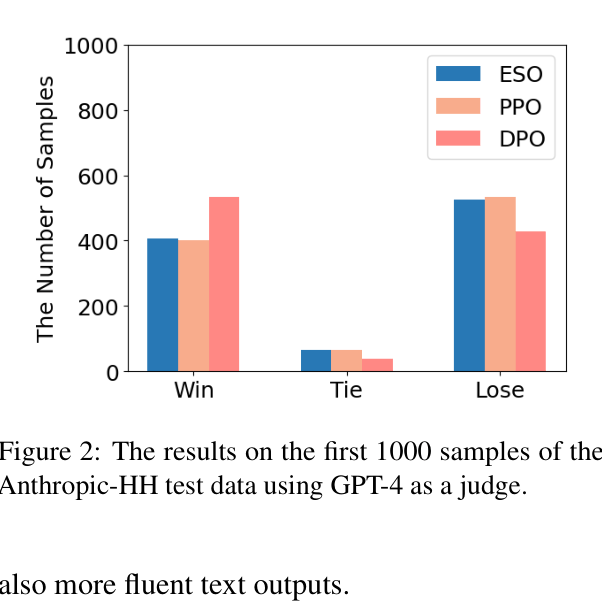
- Achieves comparable win-rate to PPO (40.7% vs 40.2%) on Anthropic-HH human alignment using Pythia-2.8B
- Demonstrates superior cross-dataset generalization: models trained on Dolly generalize better to Self-Instruct and Vicuna benchmarks compared to baselines
Breakthrough Assessment
6/10
Offers a simpler, heuristic-free alternative to PPO for on-policy learning with good results. However, it still lags behind off-policy DPO in human alignment tasks due to reward model limitations.