📝 Paper Summary
Offline Reinforcement Learning
Teacher-Student Learning
Ludor is a teacher-student framework for offline RL that augments a student policy trained on limited labeled data with knowledge from a teacher policy trained on unlabeled data, using a policy similarity measure to mitigate extrapolation errors.
Core Problem
Offline RL methods often fail when encountering states or actions not present in the labeled dataset (Out-of-Distribution/OOD), and conservative approaches that stick strictly to the data perform poorly when crucial transitions are missing.
Why it matters:
- Collecting comprehensive labeled data with rewards for every transition is often prohibitively expensive or impossible in real-world scenarios like robotics or navigation.
- Existing conservative methods (like behavior regularization) assume the dataset covers all necessary actions, failing when the optimal path requires actions excluded from the labeled set.
- Ignoring unlabeled data wastes potentially valuable information about environment dynamics and valid behaviors that could bridge gaps in the labeled dataset.
Concrete Example:
In a navigation task, if labeled offline data only covers major city roads, a standard offline RL agent will never learn to use shorter side streets. Ludor allows the agent to learn these side streets from unlabeled driving logs (without rewards) to find better paths.
Key Novelty
Ludor (Teacher-Student Framework with Policy Discrepancy)
- Trains a 'Teacher' network via Behavior Cloning on a secondary unlabeled dataset (e.g., expert or medium quality data without rewards) to capture general domain knowledge.
- Trains a 'Student' network using standard offline RL on the labeled dataset, while simultaneously pulling its weights toward the Teacher's weights via Exponential Moving Average (EMA).
- Introduces a 'Policy Discrepancy Measure' (cosine similarity) to weight the critic's loss, reducing the influence of OOD actions where the student deviates significantly from the teacher's known valid behavior.
Architecture
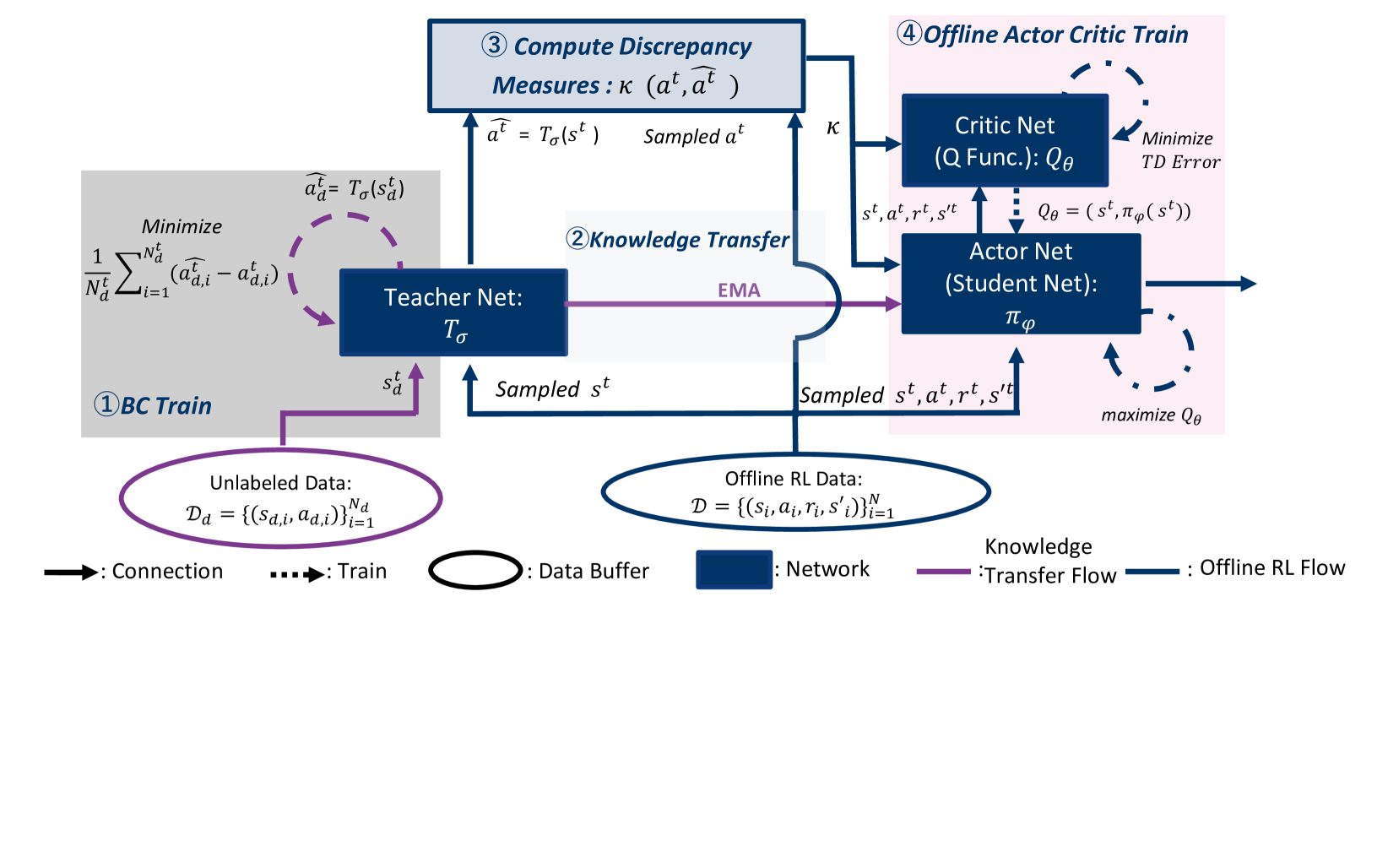
Overview of the Ludor framework showing the interaction between the Teacher network (trained on Unlabeled Data) and the Student network (trained on Offline RL Data).
Evaluation Highlights
- Restores performance in data-scarce scenarios: When 60% of data is removed from the Walker2d task, Ludor maintains high scores while standard TD3BC drops from 93.21 to 2.68.
- Outperforms baselines on D4RL benchmarks: Achieves higher normalized scores than TD3BC, IQL, and ORIL across various MuJoCo tasks (Hopper, Walker2d, HalfCheetah) in medium and expert settings.
- Successfully integrates with multiple backbones: Demonstrates improvements when applied on top of both TD3BC and IQL algorithms.
Breakthrough Assessment
7/10
Offers a practical solution for the realistic setting where labeled data is scarce but unlabeled data is abundant. The proposed discrepancy measure cleverly balances learning from data vs. teacher priors.