📝 Paper Summary
Catastrophic forgetting
Post-training optimization
Reinforcement learning inherently forgets less than supervised fine-tuning because its on-policy nature biases updates toward solutions with minimal KL divergence from the original model.
Core Problem
Fine-tuning foundation models on new tasks causes catastrophic forgetting, where performance on previously learned capabilities degrades significantly.
Why it matters:
- Models deployed as long-term agents must continually adapt to new needs without losing prior knowledge
- Current mitigation strategies address symptoms (e.g., weight constraints) rather than the underlying cause of forgetting
- SFT is shown to erase prior knowledge even when achieving similar new-task performance to RL
Concrete Example:
When fine-tuning a Qwen 2.5 3B model on math reasoning, SFT improvements on the new task cause a sharp reduction in prior-task performance (e.g., MMLU, HumanEval), whereas RL improves the new task while keeping prior benchmarks nearly unchanged.
Key Novelty
RL's Razor / Empirical Forgetting Law
- Identifies that the degree of forgetting is accurately predicted by the KL divergence between the fine-tuned and base policy on the new task alone
- Explains RL's advantage as an implicit bias: on-policy sampling restricts updates to high-probability regions of the base model, naturally finding KL-minimal solutions among equally valid ones
- Proposes that forgetting is governed by the solution distribution found, not the optimization algorithm itself—demonstrated by an 'oracle SFT' that minimizes KL and outperforms RL
Architecture
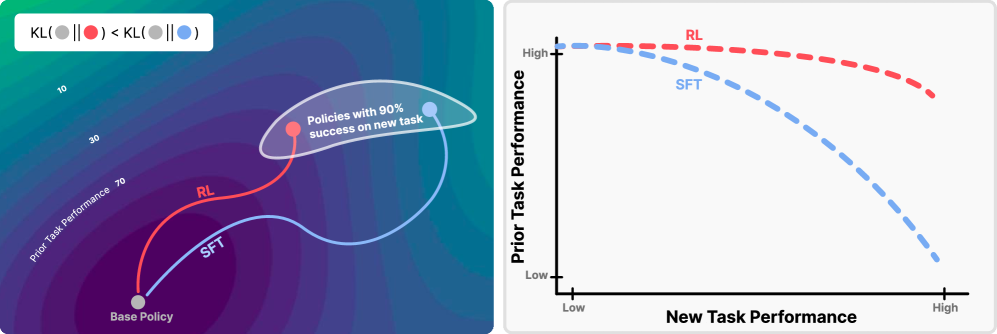
Conceptual illustration of 'RL's Razor' and the performance trade-off. Left: Solution space showing RL finding a solution closer to the initialization (Base Policy) compared to SFT. Right: Pareto frontiers showing RL maintaining higher Previous Task Performance for a given New Task Performance.
Evaluation Highlights
- On Math reasoning tasks with Qwen 2.5 3B, RL achieves high new-task accuracy with minimal degradation on prior tasks, while SFT shows a steep drop in prior performance for the same gains
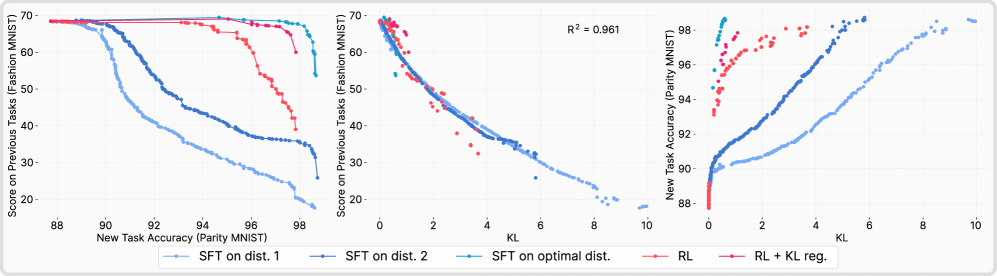
- In a controlled ParityMNIST setting, KL divergence predicts forgetting with R²=0.96 across both RL and SFT methods
- Oracle SFT (trained on analytically KL-minimal labels) retains more prior knowledge than standard RL, confirming KL minimization is the mechanism behind reduced forgetting
Breakthrough Assessment
9/10
Establishes a fundamental empirical law connecting forgetting to KL divergence on the new task, offering a unifying explanation for why RL outperforms SFT in continual learning.