📝 Paper Summary
Offline Reinforcement Learning
Offline Imitation Learning
Convex Optimization in RL
This paper unifies multiple existing offline reinforcement and imitation learning algorithms under a single dual linear programming framework, revealing their limitations and leading to two new methods: a discriminator-free imitation learner (ReCOIL) and a more stable implicit value learner (f-DVL).
Core Problem
Prior off-policy algorithms often suffer from training instability, value overestimation, or restrictive assumptions (like requiring suboptimal data to cover expert visitations) due to unprincipled handling of distribution mismatch.
Why it matters:
- Imitation learning methods relying on adversarial discriminators struggle when expert data is sparse or disjoint from offline data, leading to compounding errors.
- Implicit policy improvement methods like XQL (Extreme Q-Learning) use unstable loss functions (Gumbel regression) that cause training divergence.
- A lack of theoretical unification obscures the root causes of these failures, preventing the design of principled fixes.
Concrete Example:
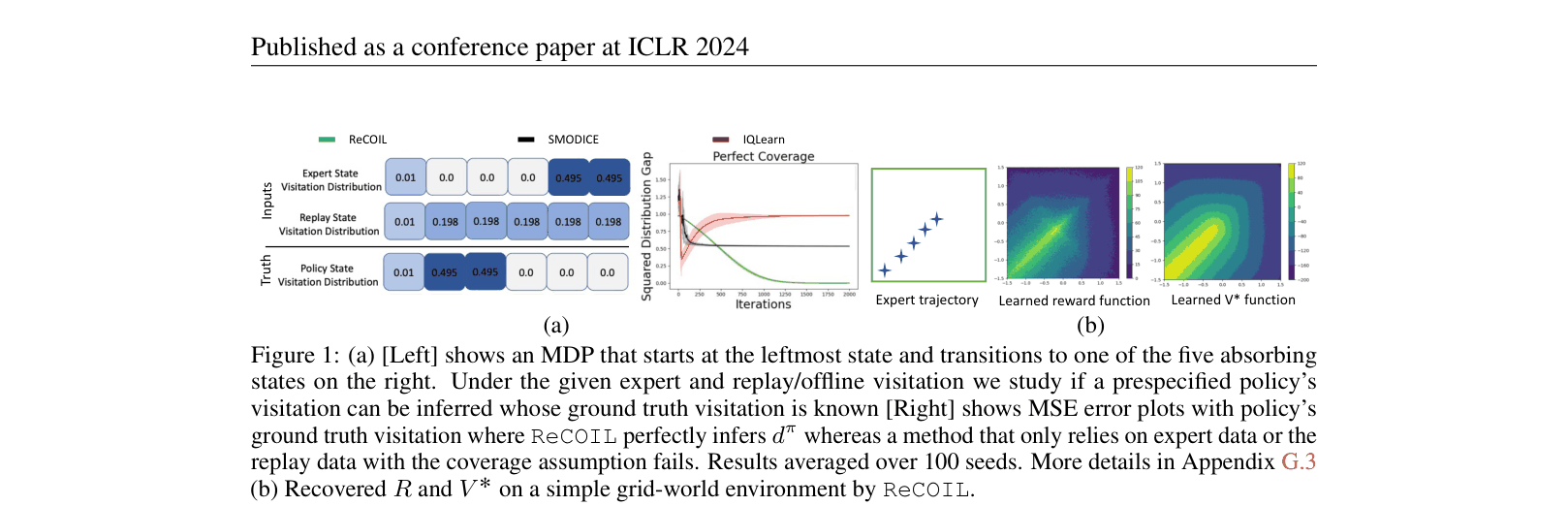
In an offline imitation task where the dataset contains 'medium' quality data plus very few expert trajectories, methods like SMODICE fail (negative returns) because they require learning a density ratio discriminator, which overfits. ReCOIL succeeds by matching a mixture distribution instead.
Key Novelty
Dual RL Framework + ReCOIL & f-DVL
- Demonstrates that diverse algorithms (CQL, IQLearn, XQL) are all instances of the dual formulation of regularized policy optimization with specific choices of f-divergence and constraints.
- Proposes ReCOIL: An imitation learning method that matches a mixture of expert and suboptimal distributions, eliminating the need for a discriminator or coverage assumptions.
- Proposes f-DVL: A family of value-learning algorithms that replaces the unstable exponential loss of XQL with stable surrogates (like Chi-squared or Total Variation) derived from the dual objective.
Architecture
The logic flow for ReCOIL (Algorithm 1) and f-DVL (Algorithm 2). Both follow an iterative update: train Critic (Q/V) using dual objectives, then update Policy (pi) using implicit maximization.
Evaluation Highlights
- ReCOIL achieves 108.18 normalized return on Hopper-random+expert, significantly outperforming SMODICE (101.61) and IQLearn (1.85) in low-coverage settings.
- f-DVL (using Total Variation) reaches 98.0 normalized return on Hopper-medium-replay-v2, surpassing XQL (94.0) and CQL (95.0) while exhibiting stable training curves.
- ReCOIL successfully recovers reward functions with 0.98 Pearson correlation to ground truth on Hopper, proving it captures expert intent better than discriminator-based methods.
Breakthrough Assessment
8/10
Provides a strong theoretical unification that cleans up the landscape of offline RL/IL. The resulting methods (ReCOIL, f-DVL) offer practical, principled improvements over strong baselines like XQL and SMODICE.