📝 Paper Summary
Offline Reinforcement Learning
Policy Extraction
Generalization in RL
Contrary to the belief that value estimation is the primary bottleneck in offline RL, policy extraction choice and test-time generalization often limit performance more significantly.
Core Problem
Offline RL often underperforms imitation learning despite using value functions, and the community traditionally attributes this to poor value estimation, overlooking other potential failures.
Why it matters:
- Practitioners may waste effort improving value functions when the actual bottleneck lies in how the policy is extracted or how it generalizes.
- Current offline RL algorithms (like AWR) may not fully leverage the information contained in learned value functions.
- Standard benchmarks on in-distribution states mask the critical failure mode of poor generalization to out-of-distribution test states.
Concrete Example:
In the 'exorl-walker' task, a weighted behavioral cloning method (AWR) fails to improve even with infinite data because it is policy-bounded, whereas a gradient-based method (DDPG+BC) successfully hill-climbs the value function to find better actions.
Key Novelty
Systematic Data-Scaling Analysis of Offline RL Components
- Deconstructs offline RL into value learning, policy extraction, and generalization, analyzing how performance scales with data quantity for each component independently.
- Identifies that policy extraction methods (specifically weighted behavioral cloning) are often the bottleneck, not the value function itself.
- Proposes test-time policy improvement (on-the-fly updates during evaluation) to address the generalization bottleneck.
Architecture
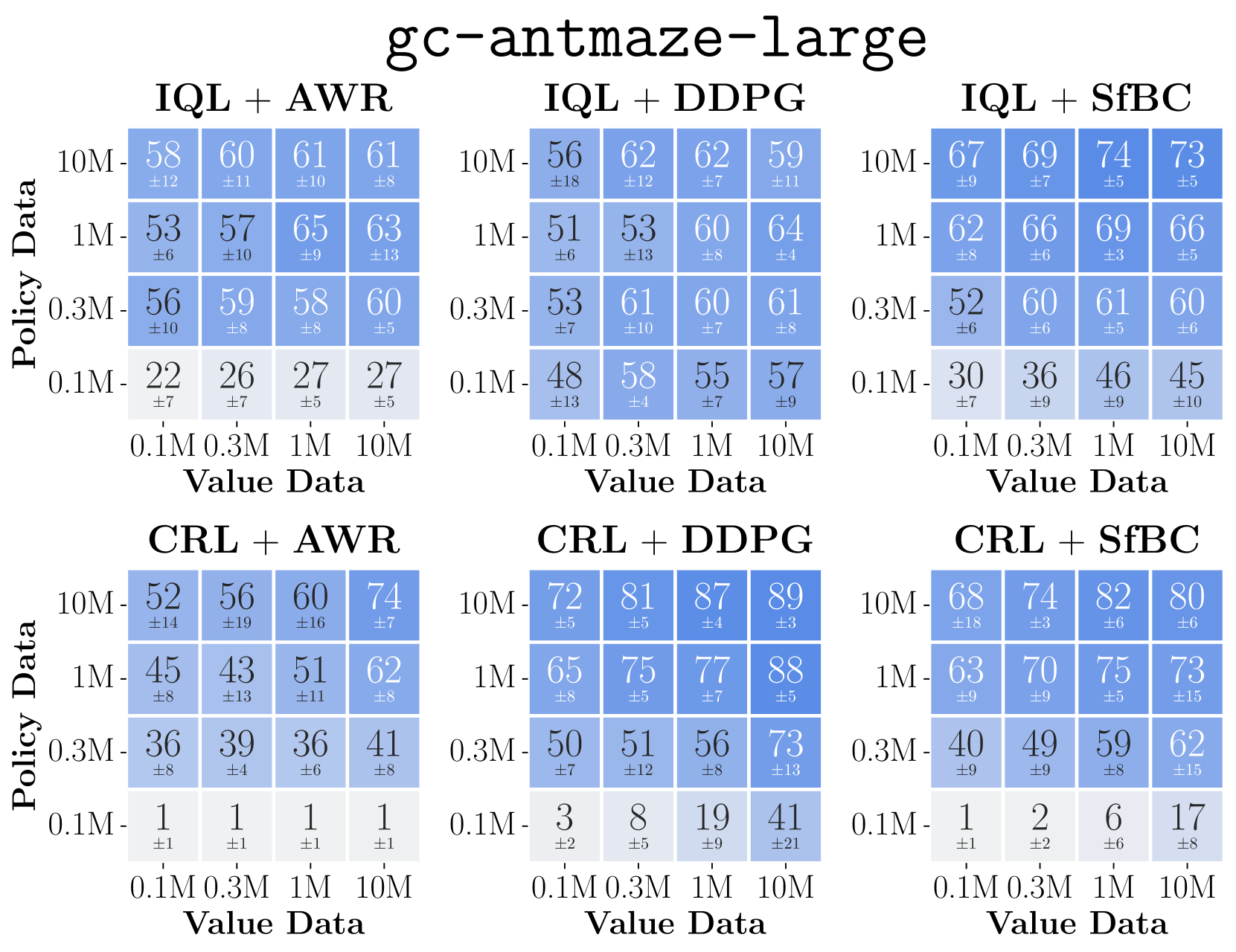
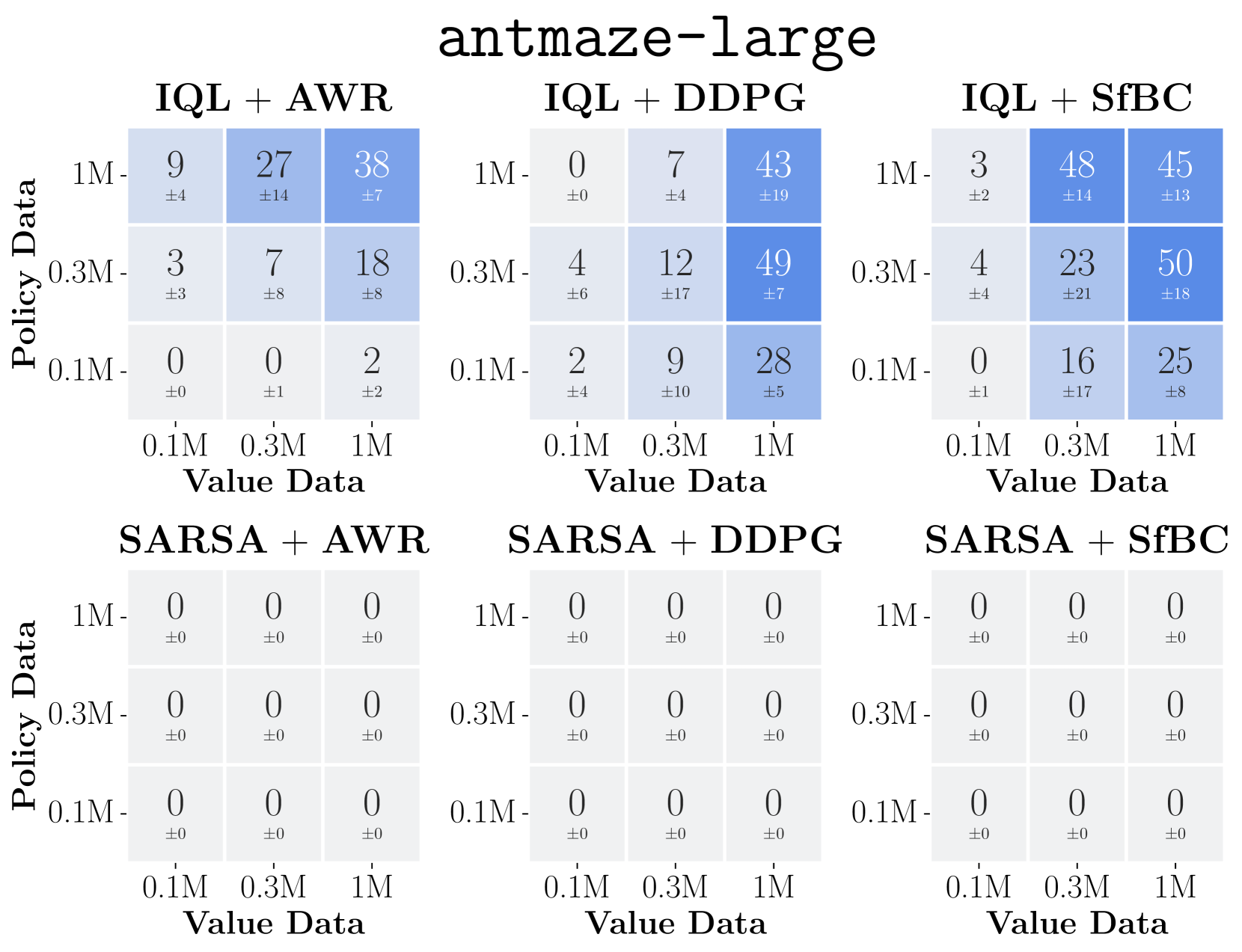
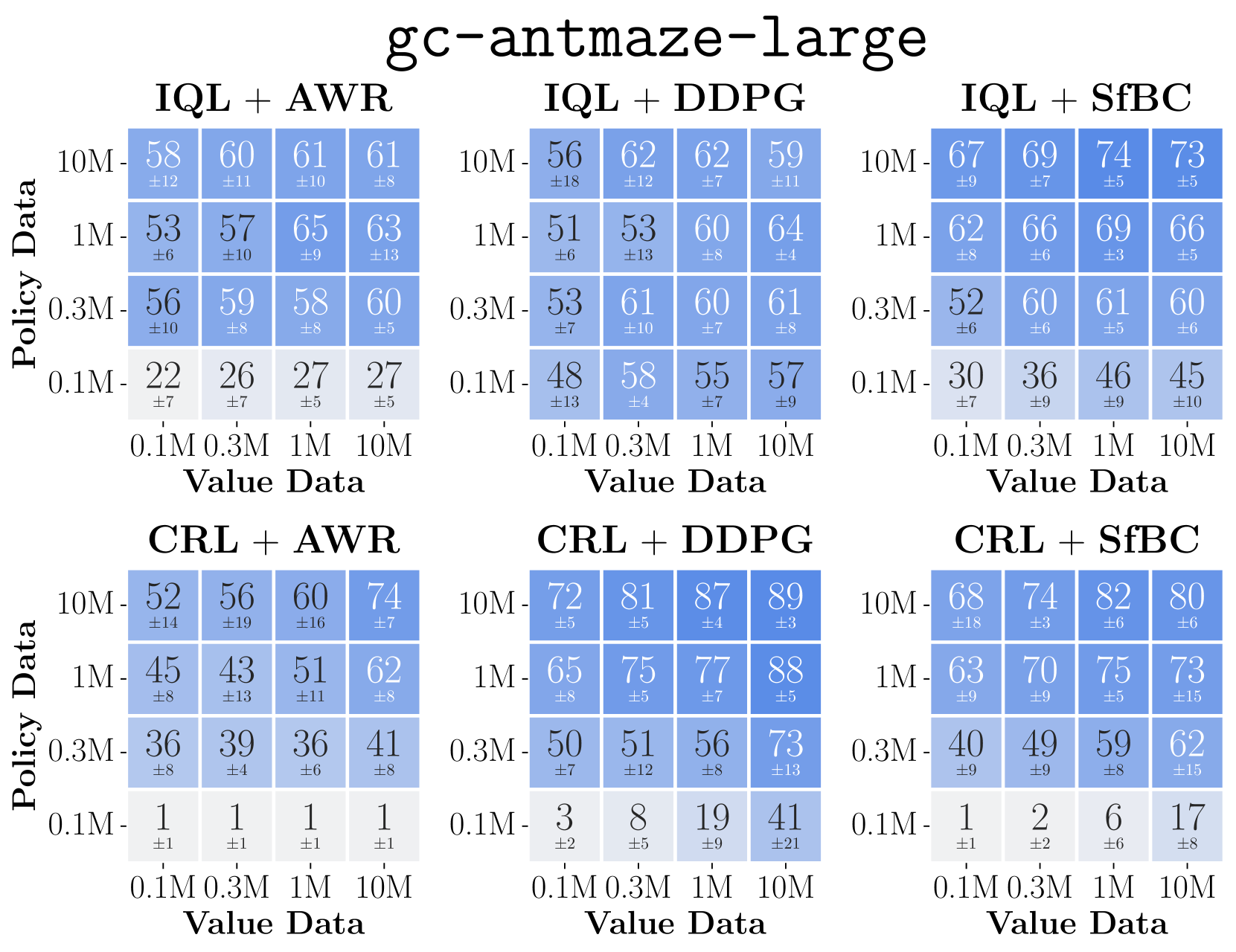
Data-scaling matrices (heatmaps) showing performance as a function of value-data size (x-axis) and policy-data size (y-axis) for different algorithms.
Evaluation Highlights
- DDPG+BC consistently outperforms AWR across 8 diverse environments, often showing favorable data scaling where AWR saturates.
- In 'gc-antmaze-large', switching from AWR to DDPG+BC moves the system from being policy-bounded to value-bounded, enabling better utilization of data.
- Proposed test-time training methods (TTA) improve success rates by correcting policy errors on out-of-distribution states encountered during deployment.
Breakthrough Assessment
8/10
Provides a crucial pivot in understanding offline RL bottlenecks, shifting focus from value estimation to policy extraction and generalization. The large-scale empirical analysis (15k+ runs) is robust.