📝 Paper Summary
Grounded Language Learning
Goal-conditioned Reinforcement Learning
GLIDE-RL trains a student agent to follow natural language instructions in sparse-reward environments using multiple teacher agents that demonstrate reachable goals and an instructor agent that generates synonymous language descriptions.
Core Problem
Training RL agents to follow natural language instructions is difficult due to language ambiguity, complexity, and the sparsity of rewards in complex environments.
Why it matters:
- Natural language goals are expressive and context-sensitive but introduce significant ambiguity (e.g., 'grab the red ball' vs. 'fetch that maroon sphere').
- Standard RL agents struggle with credit assignment and sample efficiency when rewards are sparse and goals require long sequences of actions.
- Existing methods often rely on pre-defined goal representations or lack a mechanism to ensure generated goals are actually reachable by the agent.
Concrete Example:
An agent needs to 'go to the red ball'. In a sparse reward setting, it receives no feedback until it succeeds. Without a curriculum or demonstrations, the agent flails randomly. Furthermore, if it learns 'red ball', it might fail to generalize to 'maroon sphere' without diverse language exposure.
Key Novelty
Teacher-Instructor-Student Curriculum Framework
- Teachers act in the environment to generate reachable goals (events) for the student, ensuring tasks are within the student's potential capabilities.
- An Instructor agent observes the teacher, describes the events in natural language, and uses an LLM to generate diverse synonymous instructions to improve student generalization.
- The Student learns through a mix of intrinsic rewards for reaching goals and behavioral cloning of teacher trajectories when it fails.
Architecture
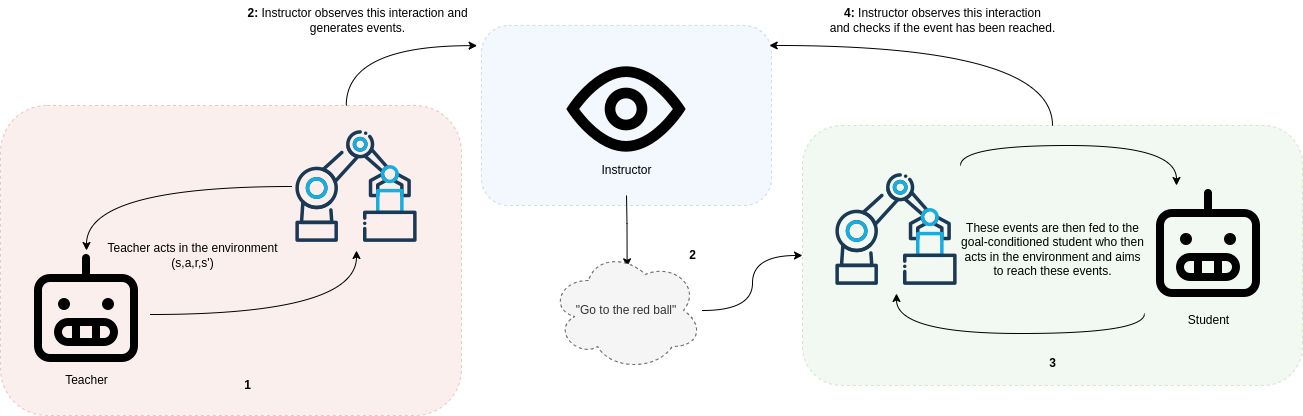
Interaction diagram between Teacher, Instructor, and Student agents.
Evaluation Highlights
- The method successfully trains a student agent to follow natural language instructions in a complex sparse reward environment where baselines typically fail.
- Demonstrates that using multiple teacher agents leads to better generalization compared to a single teacher by providing diverse goal proposals.
- Augmenting instructions with synonyms generated by ChatGPT-3.5 improves the agent's ability to handle unseen and ambiguous language instructions.
Breakthrough Assessment
6/10
Proposes a solid framework combining curriculum learning, multiple teachers, and LLM-based data augmentation for grounded language RL. While the components are known, the specific Teacher-Instructor-Student integration for reachable goal generation is a valuable contribution.