📝 Paper Summary
Reinforcement Learning for Robotics
Sim-to-Real Transfer
Automated Environment Design
Scaling robotic reinforcement learning requires automating the manual 'environment shaping' process (rewards, observations, dynamics) rather than just improving policy optimization algorithms.
Core Problem
Robotic RL successes currently rely on immense manual engineering of the environment (shaping rewards, observations, and dynamics) rather than the strength of the RL algorithms themselves.
Why it matters:
- Current benchmarks hide the true difficulty of tasks by pre-shaping environments, making RL algorithms appear more capable than they are in raw settings
- Manual shaping is a non-transferable human effort that scales linearly with the number of tasks, preventing the collection of large-scale robotic datasets needed for foundation models
Concrete Example:
In IsaacGymEnvs, tasks like 'AllegroHand' are solved not just by PPO, but by heavily engineering the reward functions and observation spaces. If we remove this shaping (unshaped environment), standard algorithms fail completely, showing they cannot solve the raw task.
Key Novelty
Formalizing 'Environment Shaping' as a Bi-level Optimization Problem
- Decompose behavior generation into an inner loop (RL agent optimizing policy on a shaped environment) and an outer loop (human or algorithm optimizing the shaping function based on true task performance)
- Redefine the goal of RL research to focus on automating this outer loop (finding optimal shaping functions f) rather than just the inner loop (finding optimal policies π)
Architecture
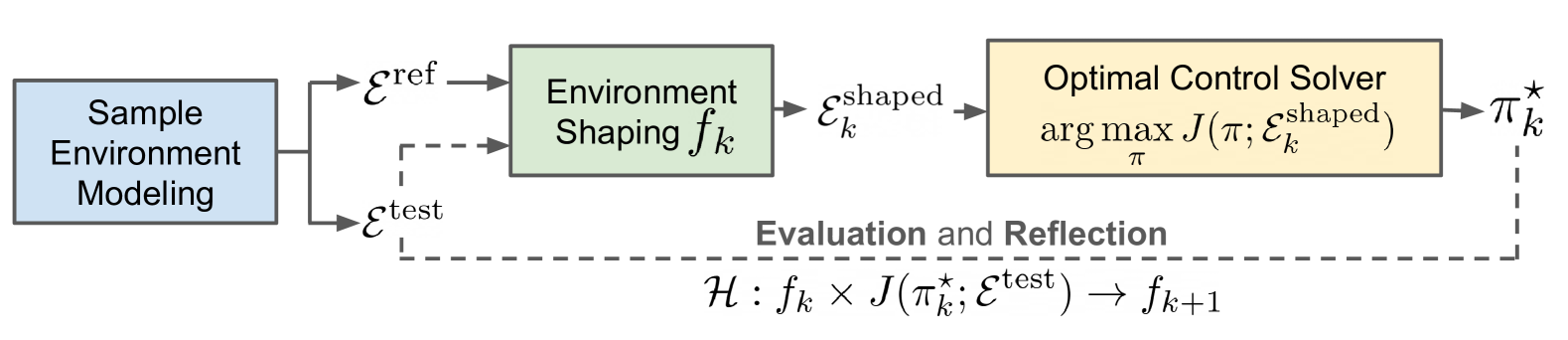
The iterative workflow of robotic behavior generation, distinguishing between sample environment generation, shaping, RL training, and evaluation.
Evaluation Highlights
- Standard PPO fails (0% success) on unshaped versions of IsaacGymEnvs tasks like AllegroHand, while achieving high performance on human-shaped versions
- Current 'AutoRL' methods like Eureka focus narrowly on reward shaping but fail when other environment parameters (like observation space or action scale) are unoptimized
- Demonstrates that shaping is a non-convex optimization problem where local improvements in one dimension (e.g., reward weight) do not guarantee global task success
Breakthrough Assessment
8/10
A strong position paper that critically re-evaluates the source of success in robotic RL. It exposes a hidden manual bottleneck and proposes a clear, actionable roadmap for the community.