📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Theoretical Reinforcement Learning
Preference-based RL
The paper theoretically proves that preference-based RL can be efficiently reduced to standard reward-based RL with little to no sample complexity overhead, suggesting RLHF is not inherently harder than standard RL.
Core Problem
RLHF learns from comparative preferences (arguably less informative than scalar rewards), raising the question of whether it is fundamentally harder than standard reward-based RL.
Why it matters:
- RLHF is critical for aligning large language models and robotics where designing reward functions is difficult
- Current theoretical works often develop specialized white-box algorithms rather than leveraging existing, mature standard RL techniques
- It is unclear if preference feedback necessitates entirely new theoretical foundations parallel to standard RL
Concrete Example:
In standard RL, an agent receives a scalar reward (e.g., +10) for a trajectory. In RLHF, the agent only knows if trajectory A is better than trajectory B. A naive reduction might query humans for every trajectory, making the query cost prohibitive.
Key Novelty
Preference-to-Reward (P2R) Reduction Interface
- For utility-based preferences, the paper introduces a black-box interface (P2R) that converts preference feedback into approximate reward signals, allowing any robust standard RL algorithm to solve the problem directly.
- For general preferences (no underlying reward model), the problem of finding a von Neumann winner is reduced to finding a restricted Nash equilibrium in a two-player zero-sum Markov game.
- Crucially, the reduction incurs no sample complexity overhead (interactions with the environment) compared to standard RL, and the query complexity (human feedback) does not scale with the RL sample complexity.
Architecture
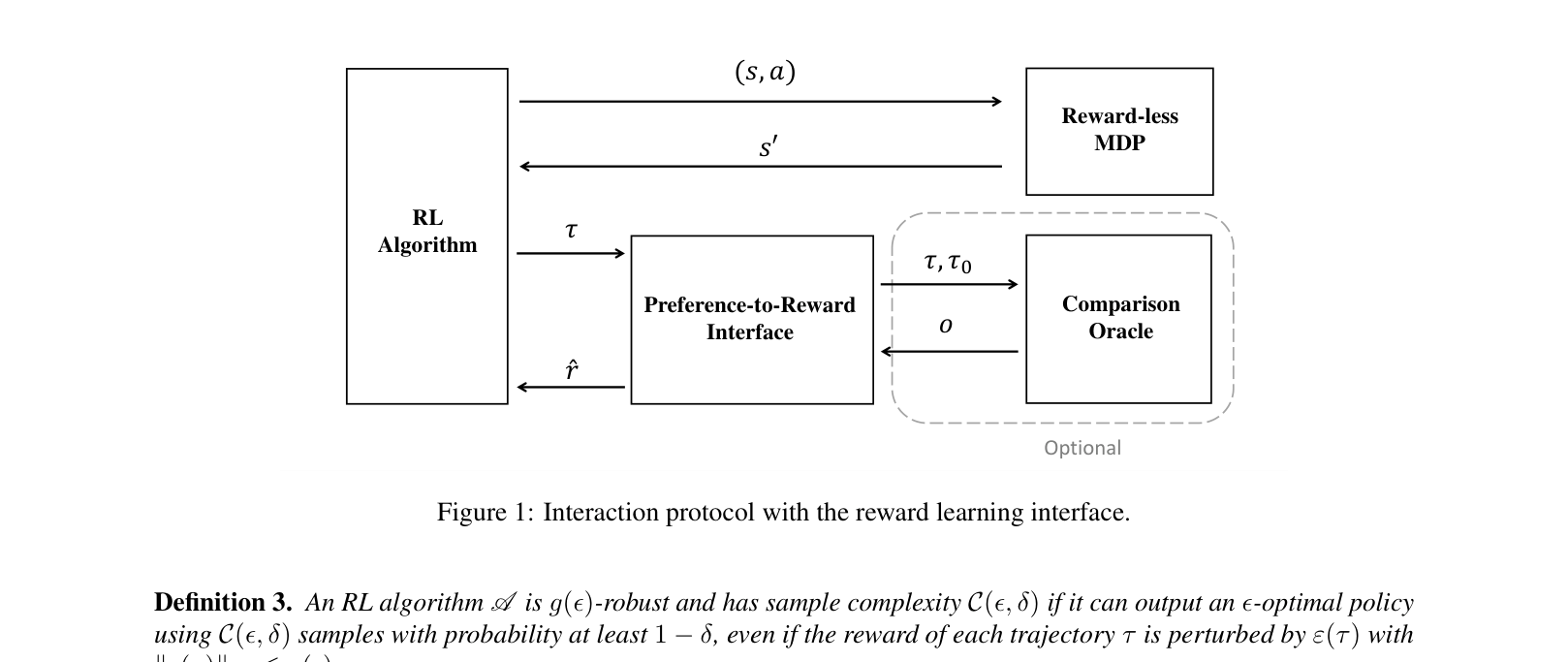
Interaction protocol between the Preference-to-Reward (P2R) Interface, the Reward-less MDP, the Comparison Oracle, and the RL Algorithm.
Evaluation Highlights
- Proves that for tabular MDPs, P2R with UCBVI-BF achieves optimal sample complexity O(H³/ε²) with query complexity O(H²/ε²)
- Proves that for general preferences depending only on final states, the problem reduces to Adversarial MDPs, achieving O(1/ε²) sample and query complexity for tabular settings
- Demonstrates that the query complexity for utility-based RL depends only on the complexity of the reward class (dR), not the complexity of the policy or transition dynamics
Breakthrough Assessment
9/10
A foundational theoretical result that unifies preference-based RL with standard RL. It provides a universal reduction recipe, proving that RLHF is not statistically harder than standard RL, which simplifies future algorithm design.