📝 Paper Summary
Synthetic Data Generation for RL
Reinforcement Learning for LLMs
Webscale-RL is an automated pipeline that converts massive pretraining corpora into verifiable question-answer pairs, enabling reinforcement learning at the scale and diversity of pretraining.
Core Problem
Adoption of RL for LLMs is bottlenecked by the scarcity and lack of diversity in high-quality, verifiable RL datasets, which are orders of magnitude smaller than pretraining corpora (<10B vs >1T tokens).
Why it matters:
- Current RL datasets focus narrowly on math/code, missing the general knowledge and diversity of web-scale text
- Training on static datasets (imitation learning) creates a training-inference gap and vulnerability to distribution shifts
- Scaling RL is proven to enhance reasoning, but cannot reach full potential without data commensurate with pretraining scales
Concrete Example:
A standard RL dataset might contain 40K math problems (DeepScaler), whereas pretraining uses trillions of tokens across diverse topics like lifestyle and commerce. Training only on the math subset limits the model's ability to generalize RL benefits to broader domains.
Key Novelty
Webscale-RL Data Pipeline
- Systematically converts narrative pretraining documents into verifiable question-answer pairs using persona-driven generation
- Uses domain classification to retrieve relevant few-shot exemplars, ensuring generated questions match the source document's context
- Assigns multiple distinct 'personas' (e.g., medical expert vs. patient) to the same document to generate diverse questions from different perspectives
Architecture
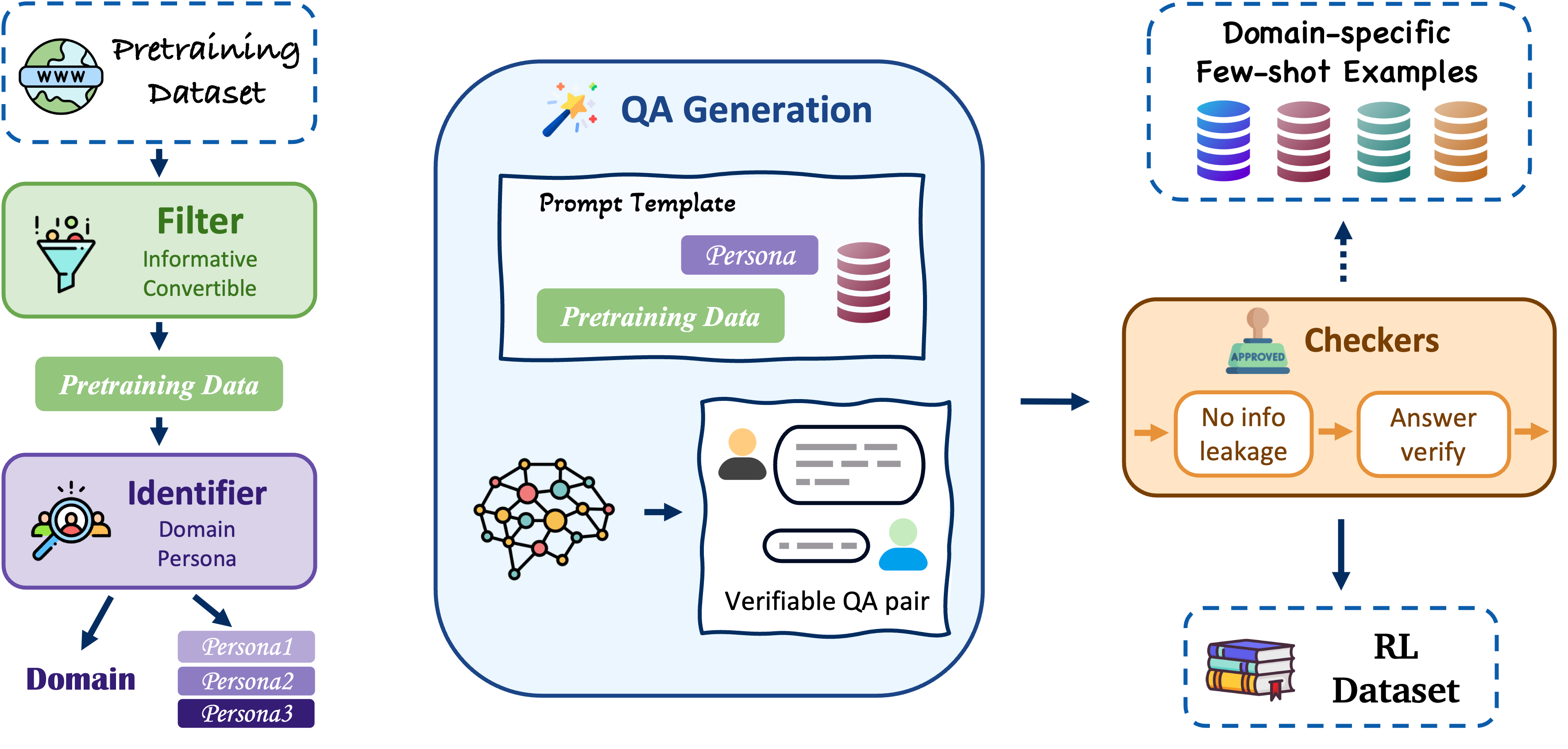
The 4-stage Webscale-RL data pipeline: Data Filtering, Domain/Persona Classification, QA Generation, and Quality Verification.
Evaluation Highlights
- Model trained on Webscale-RL achieves comparable performance to continual pretraining while using 100x fewer tokens (efficiency gain)
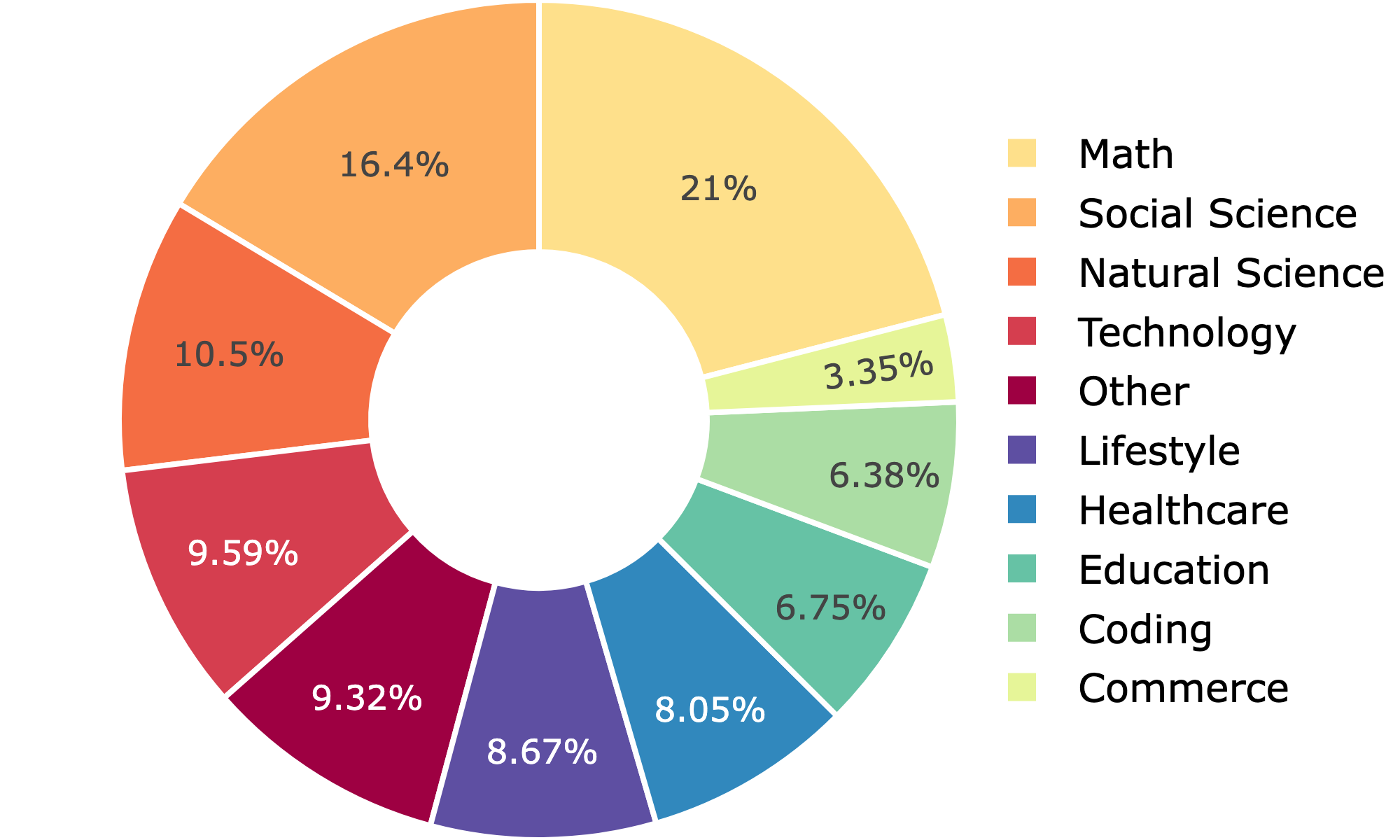
- Webscale-RL dataset spans 9+ domains including underrepresented areas like Lifestyle (>8.6%) and Commerce (>3.3%)
- Constructed 1.2 million verifiable QA pairs from a 1M document subset, scalable to full pretraining corpus size
Breakthrough Assessment
8/10
Significant step in closing the data gap between pretraining and RL. The pipeline approach addresses the critical bottleneck of data diversity and scale for RL, enabling 'post-training' techniques to be applied at 'pre-training' scale.