📝 Paper Summary
Explainable Reinforcement Learning (XRL)
Counterfactual Explanations
COUNTERPOL generates explanatory policies by finding the minimal change to an existing RL policy required to achieve a specific target return, revealing how behavior must shift to improve or deteriorate.
Core Problem
Existing RL explainability methods identify important input features or trajectories but fail to explain what minimal changes to the policy itself would lead to a desired improvement or deterioration in performance.
Why it matters:
- Trust in autonomous agents requires understanding not just what decision was made, but how the policy could be modified to achieve better results
- Current methods attribute actions to observations but cannot systematically answer 'what if' questions about the policy's overall performance target
- Unlearning specific skills or debugging agent failure modes requires knowing exactly which policy behaviors lead to lower returns
Concrete Example:
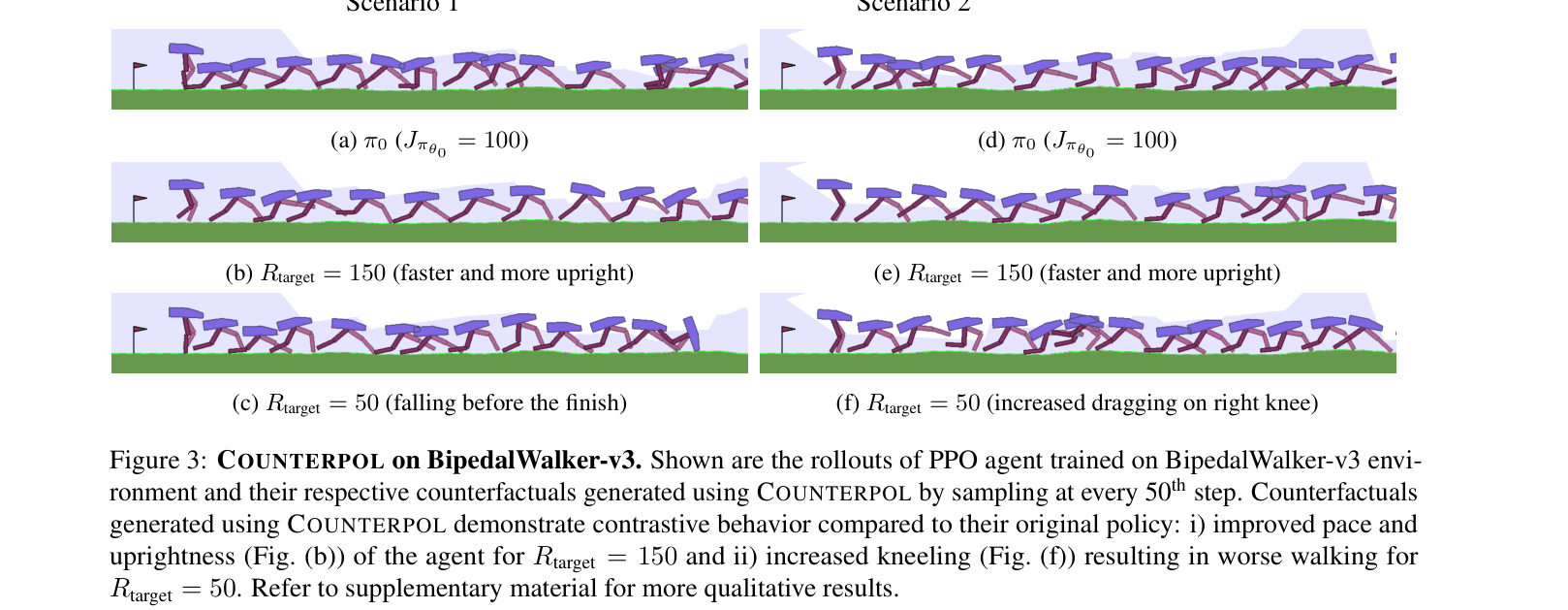
In a BipedalWalker environment, a standard policy might have a peculiar walk. Current tools highlight state features, but cannot explain that to achieve a higher return (e.g., 150), the policy specifically needs to adopt a more upright posture, whereas to degrade to a return of 50, it must intensify kneeling.
Key Novelty
Counterfactual Explanation Policy (COUNTERPOL)
- Formulates explanations as an optimization problem: find a new policy that achieves a specific target return (better or worse) while remaining as close as possible to the original policy
- Uses an iterative 'KL-pivoting' strategy where the reference policy is updated periodically to allow the agent to reach distant target returns while maintaining stability
- Establishes a theoretical equivalence showing that optimizing for a 'best possible' counterfactual return is mathematically identical to standard Trust Region Policy Optimization (TRPO)
Architecture
Pseudocode for the Counterfactual Explanation Policy Optimization loop
Evaluation Highlights
- Faithfully generates counterfactual policies matching target returns (e.g., achieving -996.9 for target -1000 in Pendulum-v1) across 5 OpenAI Gym environments
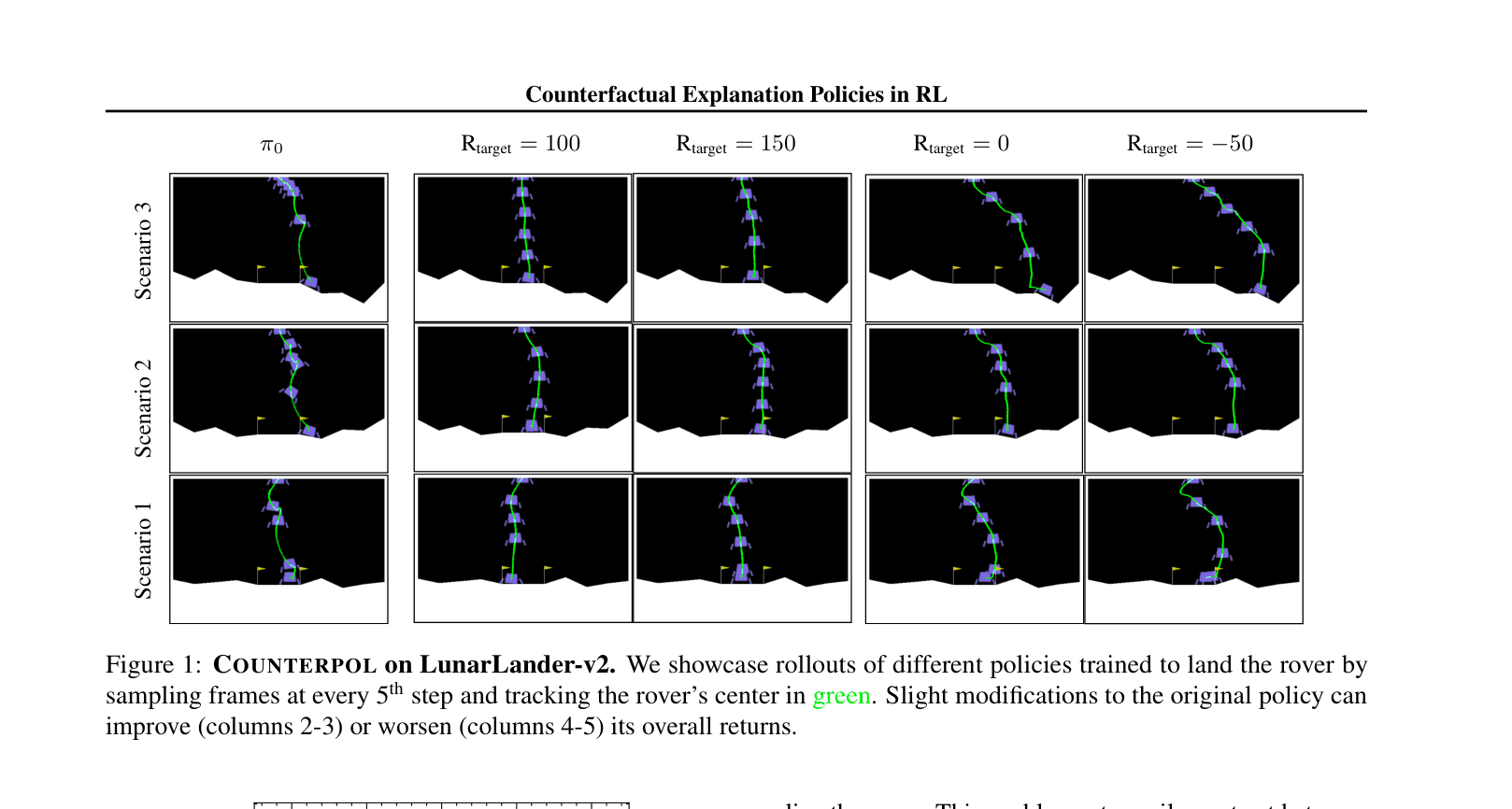
- Demonstrates 'unlearning' capabilities: generated policies for LunarLander show exactly how to fail (e.g., free fall, missing flags) to reach specific negative return targets
- Qualitative analysis reveals distinct behavioral modes: BipedalWalker counterfactuals explicitly show 'upright walking' for high returns vs 'dragging/kneeling' for low returns
Breakthrough Assessment
7/10
Novel formulation of RL explanations as policy optimization problems with strong theoretical links to TRPO. While tested on standard control tasks, it opens a new direction for contrastive policy analysis.