📝 Paper Summary
Offline Reinforcement Learning
Scalability Analysis
Goal-Conditioned RL
The authors identify effective horizon length as the primary bottleneck preventing offline RL from scaling to complex tasks and propose SHARSA, a minimal method combining n-step returns and hierarchical policies to unlock scalability.
Core Problem
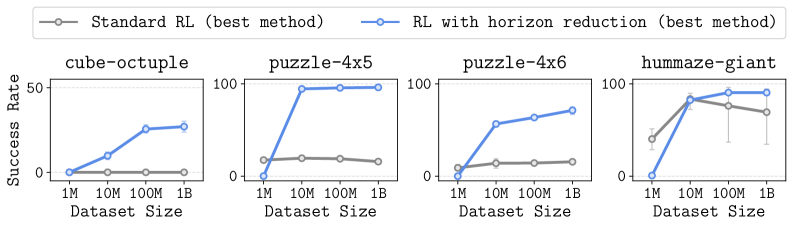
Standard offline RL algorithms (like IQL and SAC+BC) fail to solve complex, long-horizon tasks even when scaled to massive datasets (1 billion transitions) and larger models.
Why it matters:
- Current offline RL methods saturate well below optimal performance on hard tasks, contradicting the promise that more data/compute yields better results
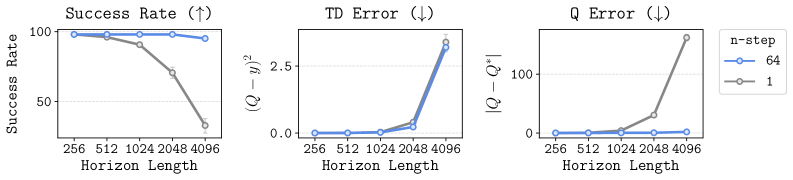
- The 'curse of horizon' causes bias accumulation in value learning (TD error compounding) and complexity in policy learning that simple scaling cannot fix
- Without solving this, offline RL cannot leverage large-scale unlabeled datasets effectively, unlike success stories in NLP and vision
Concrete Example:
In the 'cube-octuple' task (picking and placing 8 blocks), standard methods like IQL and SAC+BC achieve near 0% success even with 1 billion transitions, because the error in Q-value estimation accumulates over the long sequence of actions required.
Key Novelty
SHARSA (Scalable Horizon-Aware RL via SARSA)
- Identifies 'effective horizon' as the key scaling bottleneck: long horizons cause compounding errors in Q-values and complex policy mappings
- Proposes a minimal algorithm combining n-step returns (reducing value horizon) and hierarchical policies (reducing policy horizon) to mitigate these issues
- Demonstrates that explicitly reducing the horizon allows offline RL to scale effectively with data, achieving asymptotic performance where standard methods fail
Architecture

Conceptual diagram of SHARSA's horizon reduction strategy vs. standard methods
Evaluation Highlights
- Standard methods (IQL, SAC+BC, CRL) achieve ~0% success on the hardest task (cube-octuple) even with 1 billion transitions
- SHARSA achieves near 100% success on cube-octuple with the same 1B dataset, drastically outperforming baselines
- Increasing model size to 591M parameters for SAC+BC fails to solve hard tasks, while horizon reduction works with standard 1M parameter models
Breakthrough Assessment
9/10
Provides a crucial negative result (standard RL doesn't scale just with data) and a strong positive solution (horizon reduction unlocks scaling), backed by massive 1B-scale experiments.