📝 Paper Summary
Offline Reinforcement Learning
Robot Learning
PA-RL decouples reinforcement learning into action optimization via a critic and supervised policy training, enabling a single algorithm to effectively fine-tune diverse architectures like diffusion models and transformers.
Core Problem
Standard deep RL algorithms are often hard-coded for specific policy classes (e.g., Gaussian), making them unstable or mathematically incompatible with modern, expressive architectures like diffusion models or autoregressive transformers.
Why it matters:
- Expressive policies like diffusion models are necessary for multimodal tasks but are notoriously difficult to fine-tune with standard RL due to gradient instability
- Practitioners currently must use weaker algorithms (like simple re-ranking) or heavily modify loss functions to accommodate new policy architectures
- Robotic foundation models (like OpenVLA) cannot easily be fine-tuned with autonomous trial-and-error data using off-the-shelf methods
Concrete Example:
SAC (Soft Actor-Critic) relies on a reparameterization trick stable for Gaussian policies. When applied to a diffusion policy, this gradient propagation becomes unstable or intractable, causing training failure.
Key Novelty
Policy-Agnostic RL (PA-RL)
- Treats the policy update as a supervised learning problem by training on 'optimized' actions rather than raw policy gradients
- Generates training targets by sampling actions from the current policy, re-ranking them using a learned critic (global optimization), and refining them via gradient ascent (local optimization)
- Decouples the choice of policy architecture from the RL optimization logic, allowing the same method to train Diffusion, Transformers, and Gaussians
Architecture
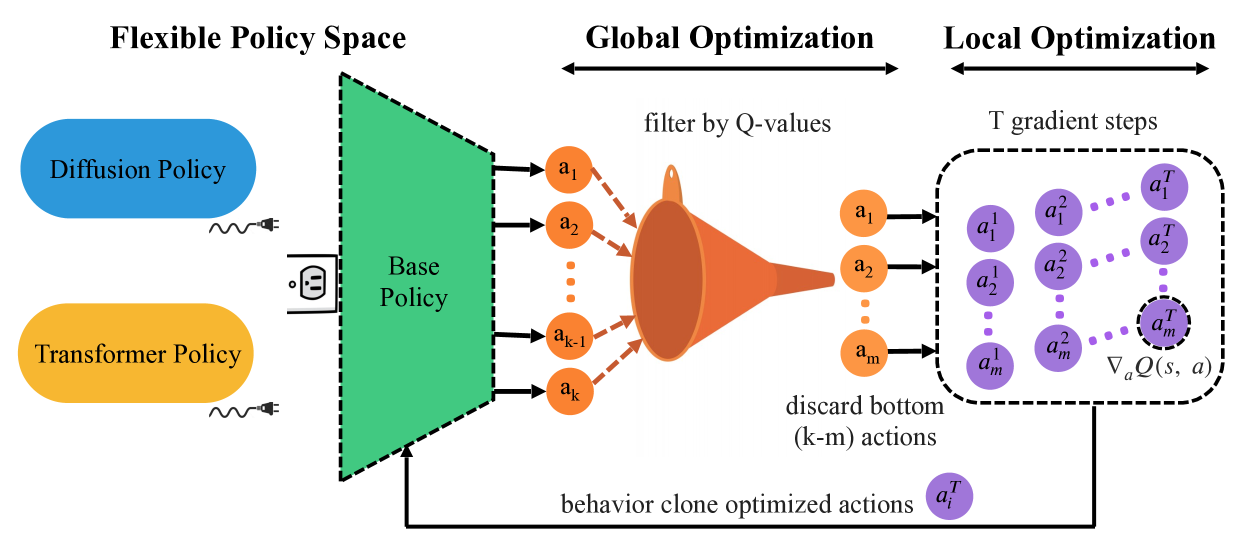
The PA-RL training loop illustrating the separation of action optimization from policy training.
Evaluation Highlights
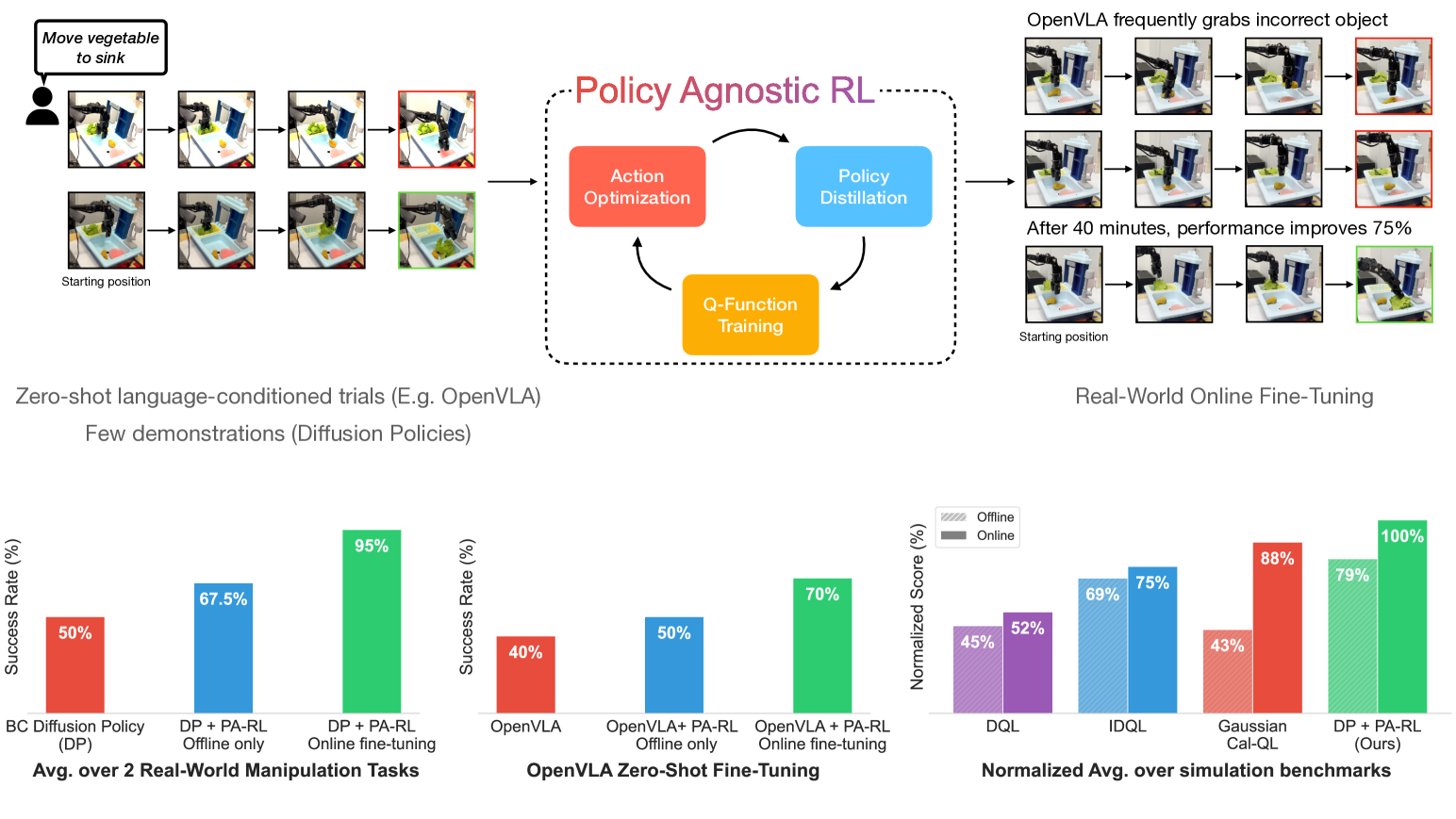
- Successfully fine-tunes OpenVLA (7B parameter robot policy) on a real robot, improving success rates from 40% to 70% in 40 minutes
- Improves diffusion policies on real-world WidowX manipulation tasks by 80-100% within 1-2 hours of online fine-tuning
- Outperforms the next-best offline RL baselines by 13% in aggregate across various simulated domains (CALVIN, LIBERO)
Breakthrough Assessment
9/10
Significantly simplifies the landscape of RL fine-tuning by providing a universal method for modern architectures. The demonstration of autonomously fine-tuning a 7B foundation model (OpenVLA) on physical hardware is a major practical milestone.