📝 Paper Summary
Offline Meta-Reinforcement Learning
Transformer-based RL
Meta-DT achieves efficient offline meta-RL generalization by conditioning a decision transformer on robust task representations from a context-aware world model and self-guided prompts that maximize prediction error.
Core Problem
Offline RL agents struggle to generalize to unseen tasks because training data is biased by behavior policies, and existing methods require expensive domain knowledge (like expert demos) at test time.
Why it matters:
- Current RL agents fail to generalize like Large Language Models (LLMs) due to distribution shifts and lack of effective self-supervised pretraining.
- Relying on expert demonstrations or hindsight statistics at test time is impractical for real-world unseen tasks where such data is unavailable.
- Behavior policies in offline datasets are often entangled with task information, causing agents to learn policy-specific biases rather than true task dynamics.
Concrete Example:
In 2D navigation, if training tasks always have agents moving directly to goals, an agent might learn 'move straight' (behavior policy feature) rather than 'move to the star' (task goal). At test time, if the behavior shifts or the goal location is new, the agent fails to extrapolate because it memorized the behavior policy instead of the task dynamics.
Key Novelty
Meta-DT (Meta Decision Transformer)
- Uses a 'Context-Aware World Model' to disentangle task dynamics from behavior policies, learning a compact task representation invariant to the data collection policy.
- Injects this task representation into a Causal Transformer to guide generation, enabling the model to distinguish between different environments.
- Constructs a 'Self-Guided Prompt' by selecting past trajectory segments with the highest prediction error, intentionally feeding the model the most informative/surprising context to refine its task belief.
Architecture
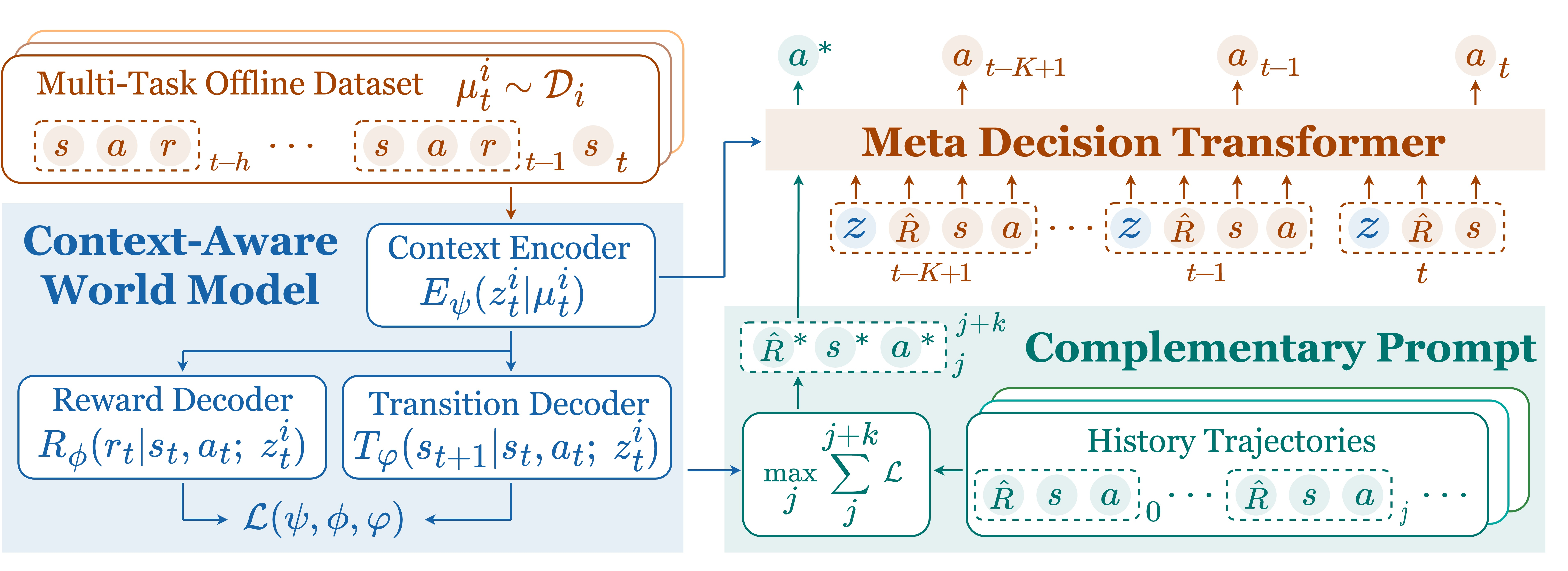
Overview of the Meta-DT framework, illustrating the two-stage process: World Model Pretraining and Meta-DT Training/Inference.
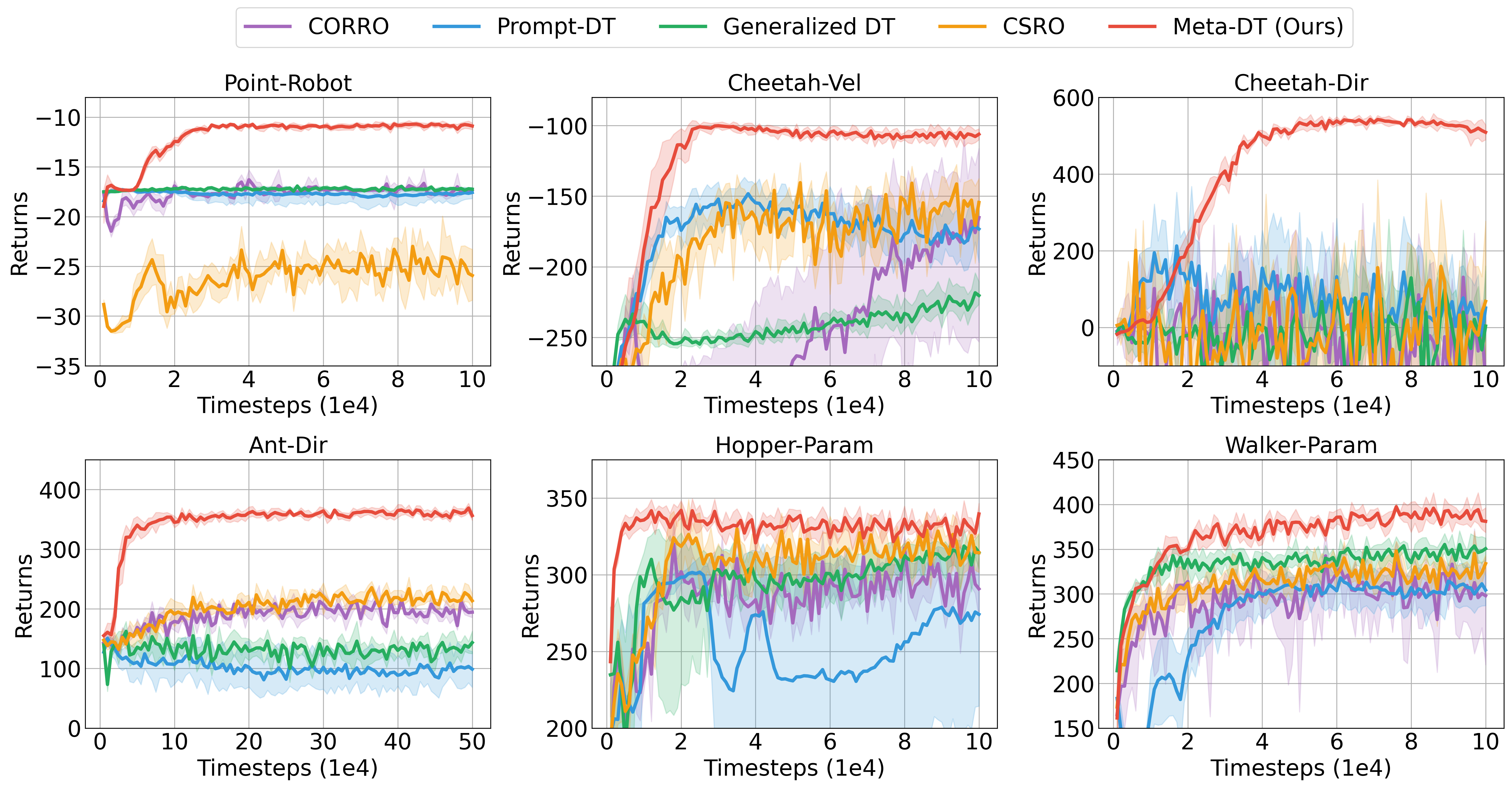
Evaluation Highlights
- Achieves superior zero-shot and few-shot generalization on MuJoCo and Meta-World benchmarks compared to strong baselines like Prompt-DT and MACAW.
- Outperforms Prompt-DT by significant margins in sparse-reward settings where context is scarce, without requiring expert demonstrations.
- Demonstrates robustness to data quality, maintaining high performance even when trained on medium or mixed-quality datasets where other methods degrade.
Breakthrough Assessment
8/10
Significantly advances offline meta-RL by removing the need for expert demos at test time while improving generalization. The 'error-maximizing' prompt selection is a clever, counter-intuitive mechanism for active task identification.