📝 Paper Summary
Meta-Reinforcement Learning
Hybrid RL Architectures
RL3 augments black-box Meta-RL agents by injecting task-specific action-value estimates and visitation counts, computed by an inner standard RL algorithm, directly into the meta-policy's input stream.
Core Problem
Black-box Meta-RL methods (like RL2) rely on sequence models to infer strategies from raw history, which is data-inefficient during meta-training and struggles with long horizons or out-of-distribution tasks compared to traditional value-based RL.
Why it matters:
- Meta-RL often exhibits poor asymptotic performance because sequence models (RNNs/Transformers) struggle to process arbitrary amounts of experience data effectively over long episodes.
- Traditional RL algorithms are asymptotically optimal but slow; Meta-RL is fast but suboptimal. Current methods fail to bridge this gap effectively.
- Generalization to tasks not seen during meta-training (OOD) is critical for real-world deployment (e.g., robotics) but remains a weakness for pure sequence-based meta-learners.
Concrete Example:
In a robotic manipulation task with varying object shapes, a standard Meta-RL agent might fail to handle a new, unseen shape (OOD) because its sequence model hasn't learned that specific pattern. In contrast, a traditional Q-learning agent would eventually learn to manipulate the new shape given enough interaction, but it starts from scratch.
Key Novelty
Hybrid Meta-RL with Auxiliary Q-Values (RL inside RL2)
- Runs a standard, off-policy RL algorithm (like Q-learning) 'inside' the meta-learning loop to compute task-specific value estimates in real-time.
- Feeds these Q-values and state-action counts into the Meta-RL policy (e.g., Transformer) as additional observations alongside the standard state-action-reward history.
- Allows the meta-learner to learn how to fuse raw history (for fast adaptation) with explicit value estimates (for asymptotic optimality and stability).
Architecture
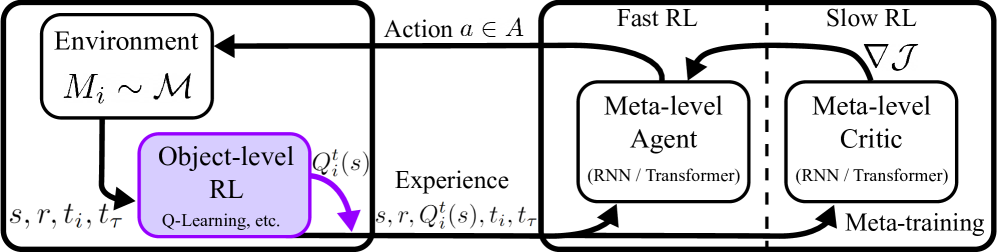
The RL3 architecture layout involving the Meta-RL agent and the Object-level RL module.
Breakthrough Assessment
7/10
Offers a principled method to combine the speed of Meta-RL with the optimality of standard RL. The theoretical grounding (linking Q-values to meta-values) is strong, though it relies on existing architectures (RL2/PPO).