📝 Paper Summary
Offline Reinforcement Learning
Deep Reinforcement Learning Theory
VIPeR achieves provably efficient offline RL with neural networks by replacing computationally expensive explicit confidence bounds with an ensemble of value functions trained on randomly perturbed rewards.
Core Problem
Existing provably efficient offline RL algorithms rely on Lower Confidence Bounds (LCB), which require inverting large covariance matrices scaling with neural network width, making them computationally prohibitive for deep learning.
Why it matters:
- Explicitly constructing confidence regions for overparameterized neural networks is computationally infeasible (requires O(K^2) or worse complexity)
- Current practical deep offline RL methods often lack theoretical guarantees for general function approximation
- Bridging the gap between theory (provable efficiency) and practice (deep neural networks) is a major open problem
Concrete Example:
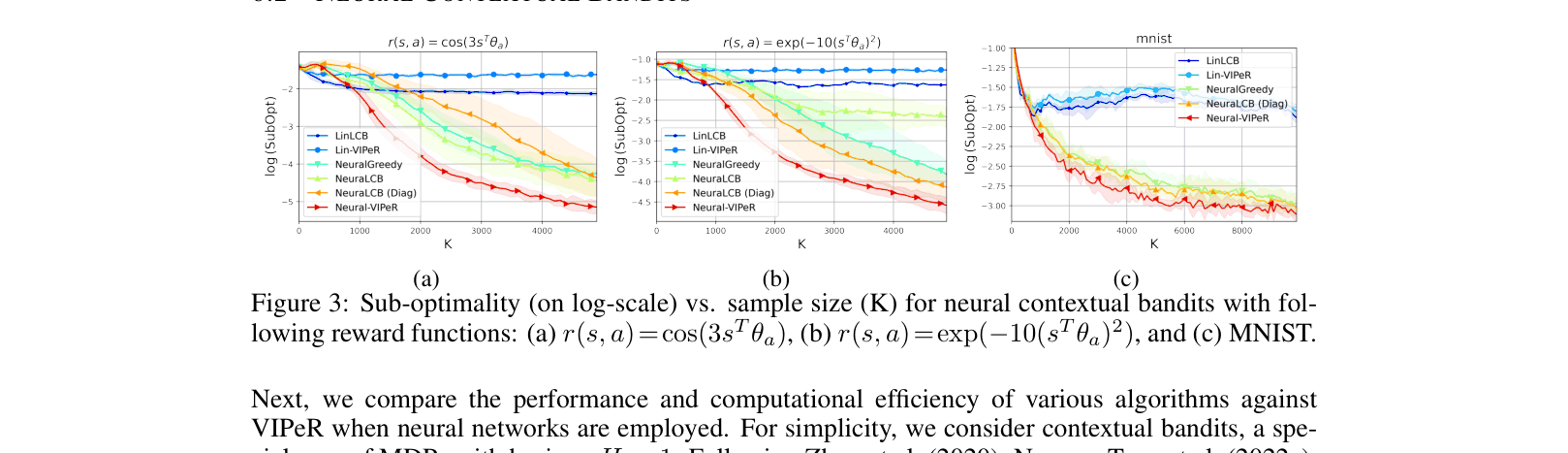
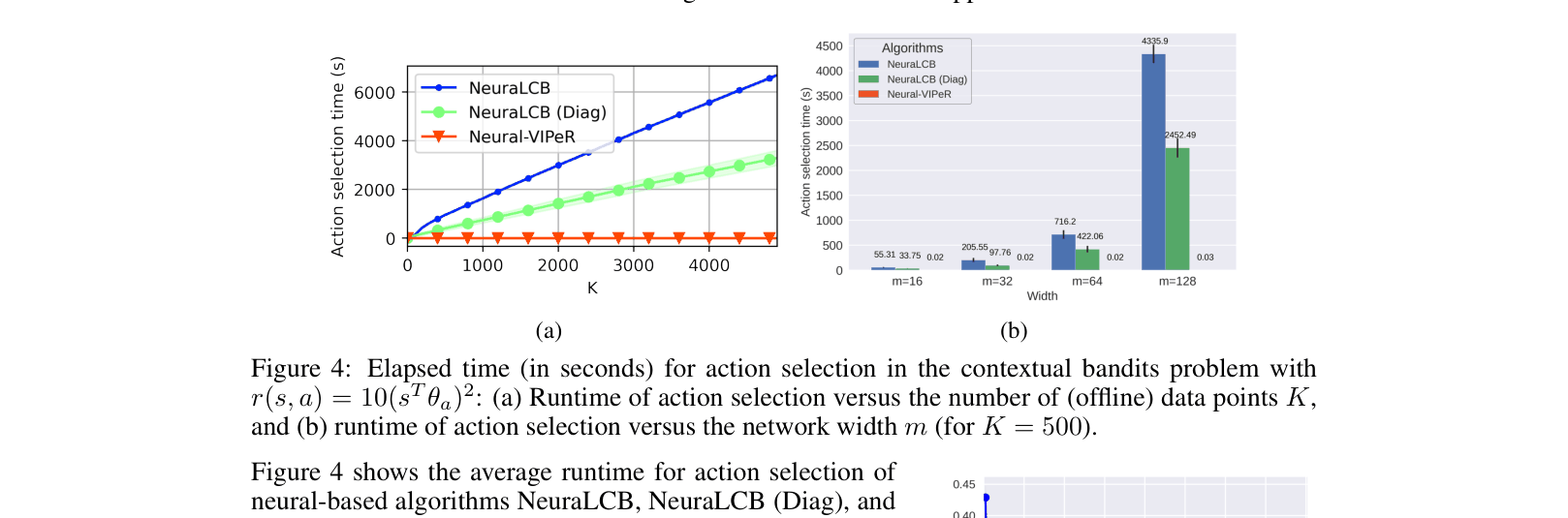
In neural offline contextual bandits, LCB-based methods like NeuraLCB must compute the inverse of a large covariance matrix for every action selection, causing runtime to explode as network width increases. VIPeR selects actions in O(1) time using a forward pass on an ensemble.
Key Novelty
Implicit Pessimism via Perturbed Rewards (VIPeR)
- Instead of calculating explicit uncertainty penalties, the method adds random Gaussian noise to the offline dataset's rewards multiple times to create perturbed datasets
- It trains an ensemble of neural networks on these perturbed datasets and acts greedily with respect to the minimum value across the ensemble (implicit lower confidence bound)
- A novel data-splitting technique divides trajectories into disjoint buckets to remove dependencies on covering numbers in the theoretical analysis
Architecture

The pseudocode and data-splitting strategy. Shows how the offline dataset is partitioned into H buckets, and how for each step h, M perturbed datasets are created by adding Gaussian noise to rewards.
Evaluation Highlights
- Outperforms LCB-based baselines (NeuraLCB) on neural contextual bandits while requiring only O(1) inference time vs. O(K^2)
- Matches asymptotic sample complexity of state-of-the-art linear methods (PEVI) when reduced to linear settings, improving by a factor of sqrt(d)
- Demonstrates consistent sub-optimality reduction on D4RL benchmarks compared to standard baselines
Breakthrough Assessment
8/10
First algorithm to be both provably efficient and computationally efficient for general MDPs with neural function approximation, solving a major bottleneck in theoretical offline RL.