📝 Paper Summary
Offline Reinforcement Learning
Task-Oriented Dialogue Systems
Offline reinforcement learning methods significantly improve dialogue generation over teacher forcing by optimizing sequence-level semantic rewards using static datasets, avoiding the instability and cost of online RL.
Core Problem
Standard Teacher Forcing (TF) trains models to match human tokens exactly, punishing valid paraphrases and failing to optimize for sequence-level meaning.
Why it matters:
- Humans express the same meaning in diverse ways; enforcing exact matches is an unnecessarily hard and misaligned objective
- Online RL alternatives are expensive, sample-inefficient, and suffer from training instability in sparse reward landscapes like text generation
- Current dialogue systems struggle to generate responses that are semantically close to human intent while remaining diverse
Concrete Example:
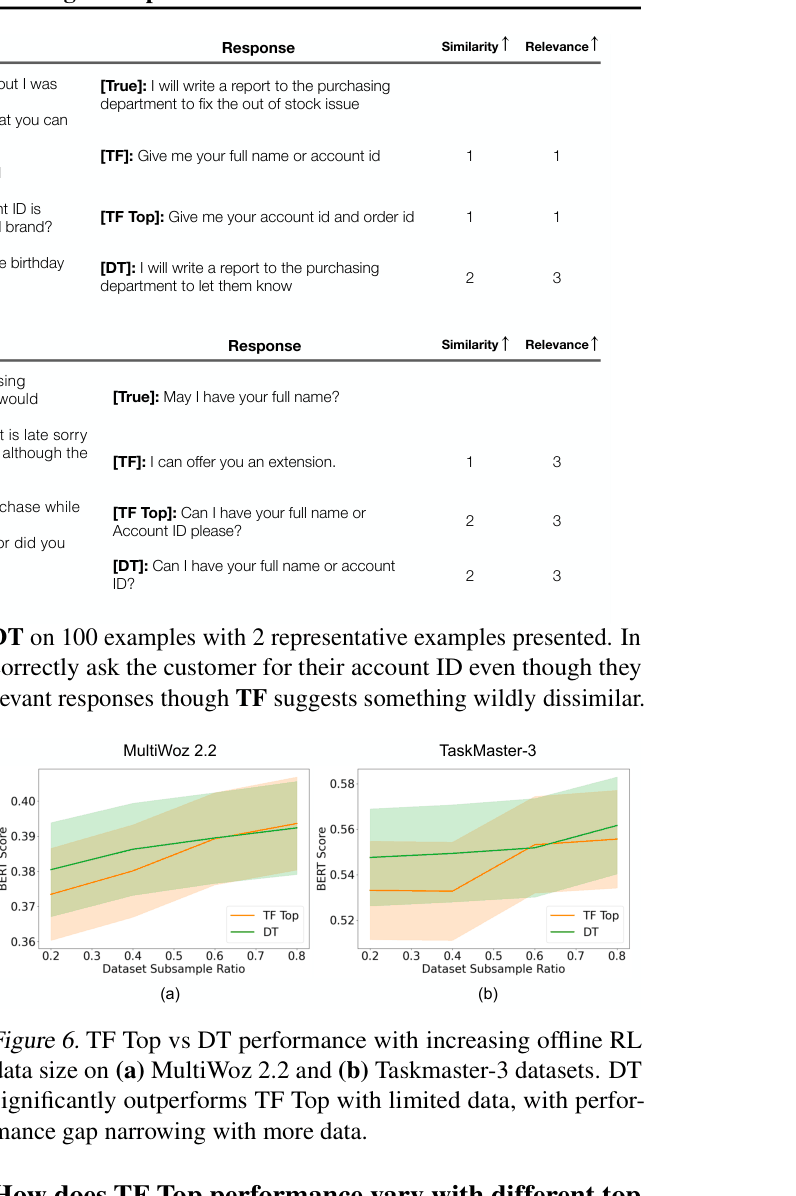
In a customer service chat, if the ground truth is 'The flight is confirmed', TF penalizes 'Your flight has been booked'. Offline RL rewards both equally if they share semantic meaning.
Key Novelty
Offline RL for Semantic Dialogue Optimization
- Treats dialogue generation as an offline RL problem where the goal is to maximize a semantic similarity reward (e.g., BERTScore) rather than next-token likelihood
- Uses static datasets generated by a base model to learn policies that capture the 'spirit' of human responses without needing live exploration
- Adapts Implicit Q-Learning (ILQL) to regularize against the base policy's logits (rather than the dataset) for better performance in low-data regimes
Architecture
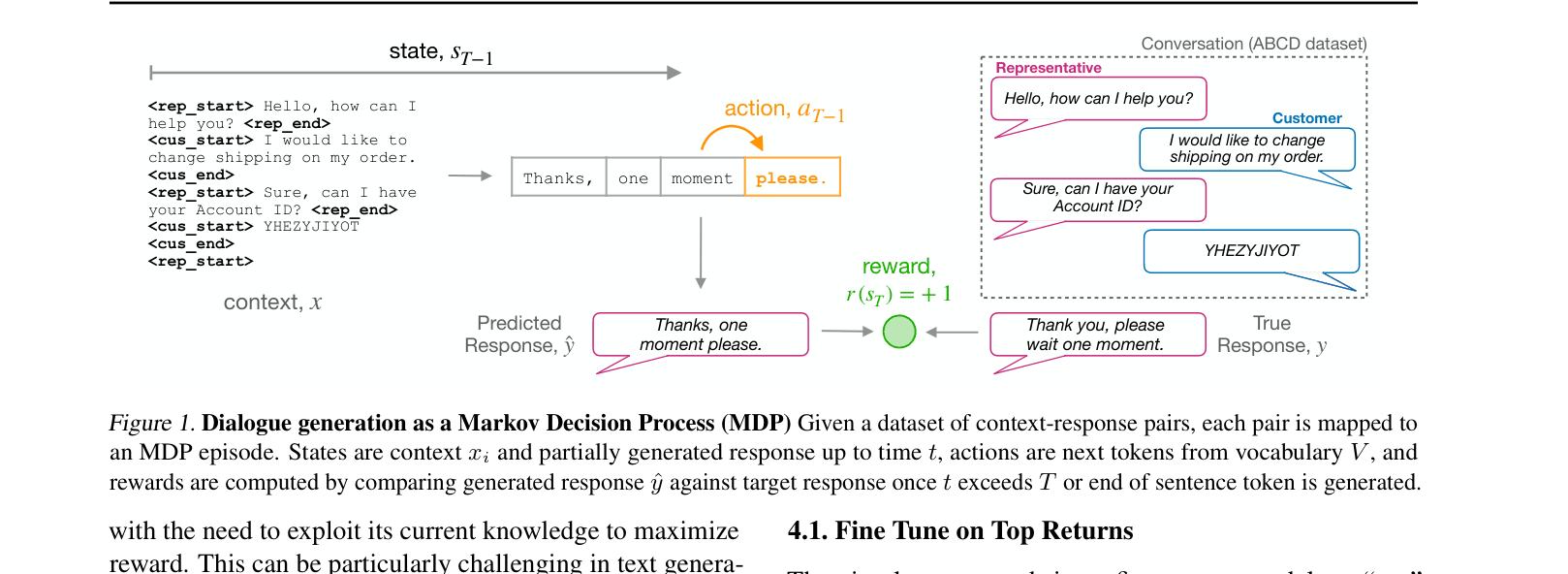
Conceptual MDP formulation for Dialogue Generation.
Evaluation Highlights
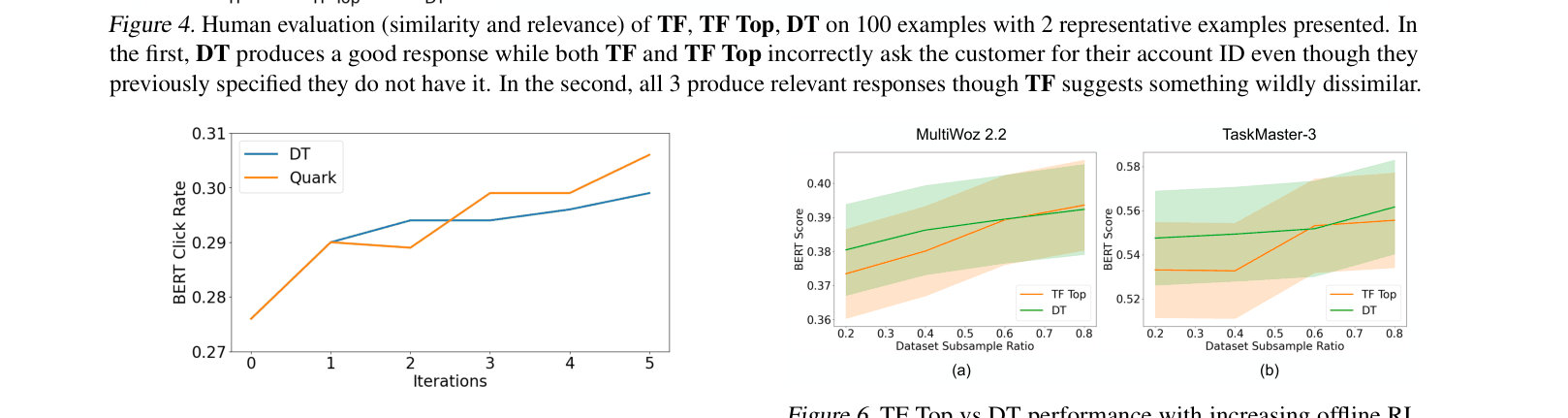
- Decision Transformer (DT) outperforms Teacher Forcing by ~5% in BERTScore on ABCD and MultiWoz datasets
- Human evaluators rated DT responses significantly higher in similarity (2.36 vs 1.98) and relevance (2.85 vs 2.62) compared to Teacher Forcing
- Offline RL methods achieve these gains while training 2.5x to 4x faster than online PPO (Proximal Policy Optimization)
Breakthrough Assessment
7/10
Solid empirical work demonstrating that Offline RL is a practical, superior alternative to Teacher Forcing and Online RL for dialogue. While the methods (DT, ILQL) are existing, the application and rigorous benchmarking in this domain are valuable.