📝 Paper Summary
Safe Reinforcement Learning
Robotic Locomotion
CBF-RL trains policies to be inherently safe by applying active CBF safety filtering only during training and reinforcing safe behavior through barrier-based rewards, eliminating the need for runtime filters.
Core Problem
RL policies often prioritize performance over safety, leading to catastrophic failures, while traditional safety filters (CBFs) prune exploration too aggressively and require expensive optimization at runtime.
Why it matters:
- Humanoid robots are expensive and operate in complex environments; unsafe actions cause physical damage.
- Existing methods either rely on runtime filters (computationally heavy, conservative) or reward shaping alone (insufficient for strict safety).
- Policies trained with runtime filters often fail to internalize safety constraints, remaining dependent on the filter.
Concrete Example:
A humanoid robot navigating stairs might propose an unstable footstep. A standard RL policy would execute it and fall. A runtime filter would correct it but burden the onboard computer. CBF-RL trains the policy to never propose the unstable step in the first place.
Key Novelty
Dual Approach: Training-Time Filtering + Barrier-Based Reward Shaping
- Apply a closed-form Control Barrier Function (CBF) filter only during training to actively correct unsafe actions before execution.
- Simultaneously punish the agent based on the filter's activation and distance to safety boundaries using a barrier-inspired reward.
- The policy receives 'corrective supervision'—learning from the filtered action and the penalty—so it internalizes safety and acts safely at deployment without a filter.
Architecture
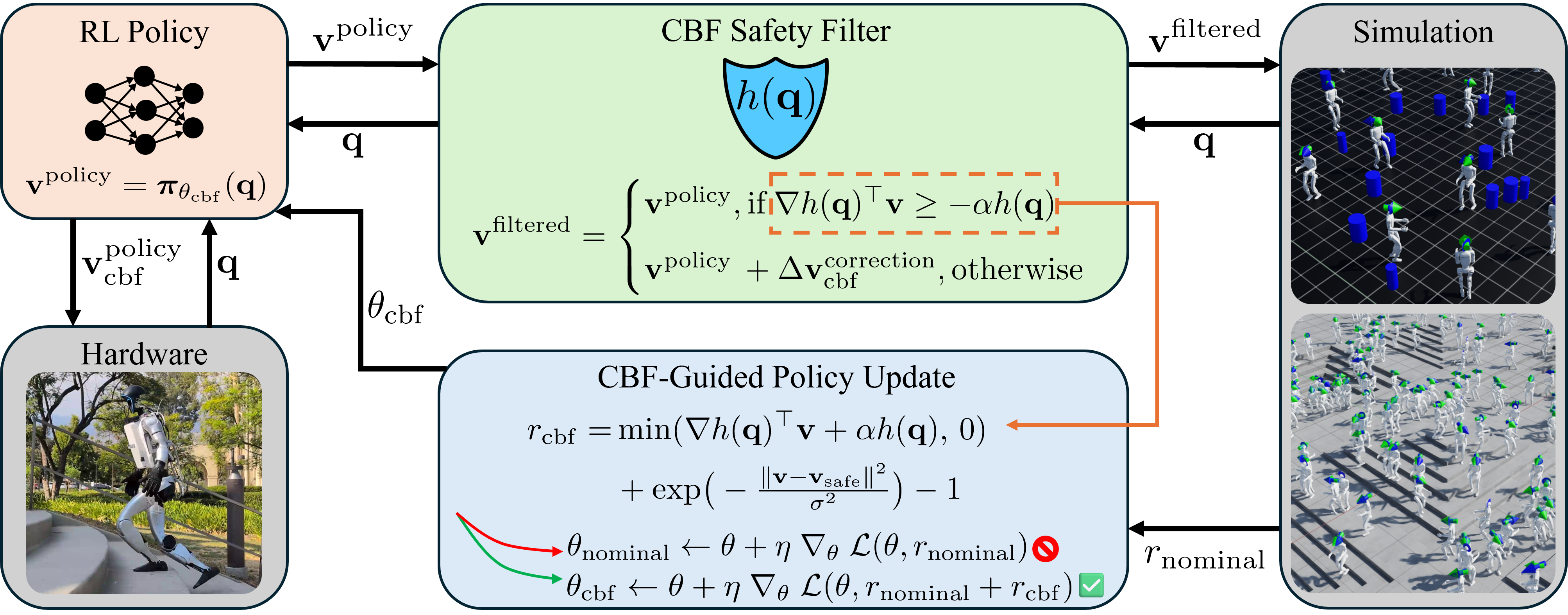
The CBF-RL training loop and deployment pipeline.
Evaluation Highlights
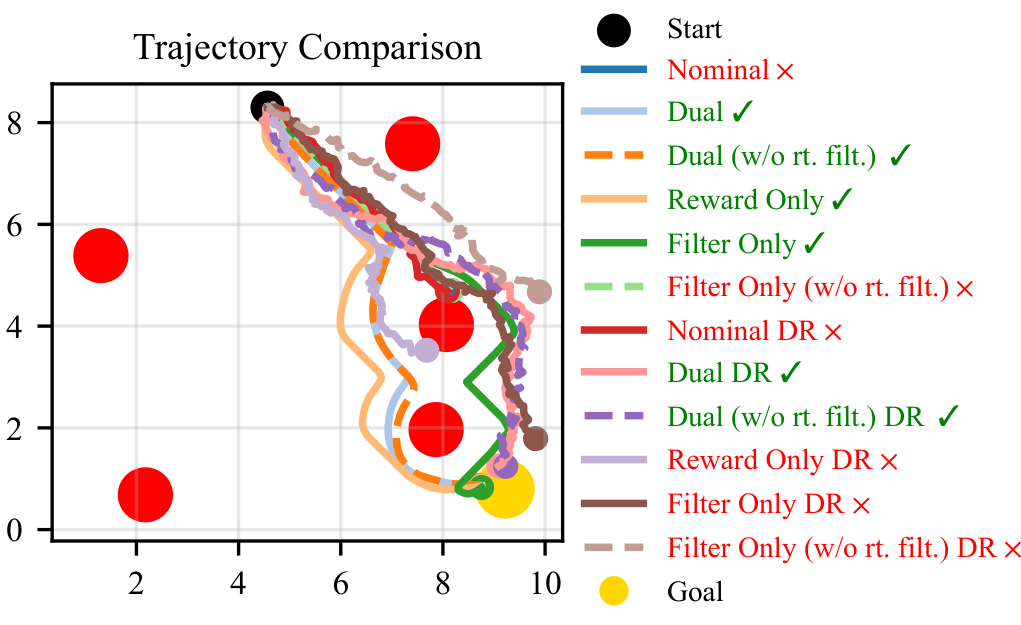
- 100% success rate in 2D navigation tasks with randomized dynamics, compared to 0% for nominal PPO and 55% for filter-only training.
- Zero-shot transfer to a physical Unitree G1 humanoid robot, successfully navigating obstacles and climbing stairs where nominal policies failed.
- Achieved robustness to 20% dynamics noise in navigation tasks without explicit robust training, outperforming baselines.
Breakthrough Assessment
8/10
Strong theoretical grounding (continuous-to-discrete proof) enabling a practical solution for high-dimensional robots. successfully demonstrates filter-free safety on hardware, addressing a major bottleneck in safe RL.