📝 Paper Summary
Goal-Conditioned Reinforcement Learning
Offline Reinforcement Learning
QRL learns optimal goal-reaching value functions by constraining the search to quasimetric models and optimizing a novel objective that locally enforces transition costs while globally maximizing state separation.
Core Problem
Standard RL algorithms like Q-learning struggle to learn optimal value functions in goal-reaching settings because they do not exploit the inherent quasimetric geometry (triangle inequality and asymmetry) of the optimal value function.
Why it matters:
- Goal-reaching is a fundamental problem in robotics and planning, requiring accurate cost-to-go estimates for arbitrary start-goal pairs.
- Existing methods either fail to capture the optimal value (learning on-policy values instead) or suffer from slow convergence and instability when simply plugging quasimetric models into traditional Bellman updates.
- Symmetric metric approaches fail in environments with irreversible dynamics (e.g., gravity, cliffs), while standard Q-learning is inefficient in multi-goal settings.
Concrete Example:
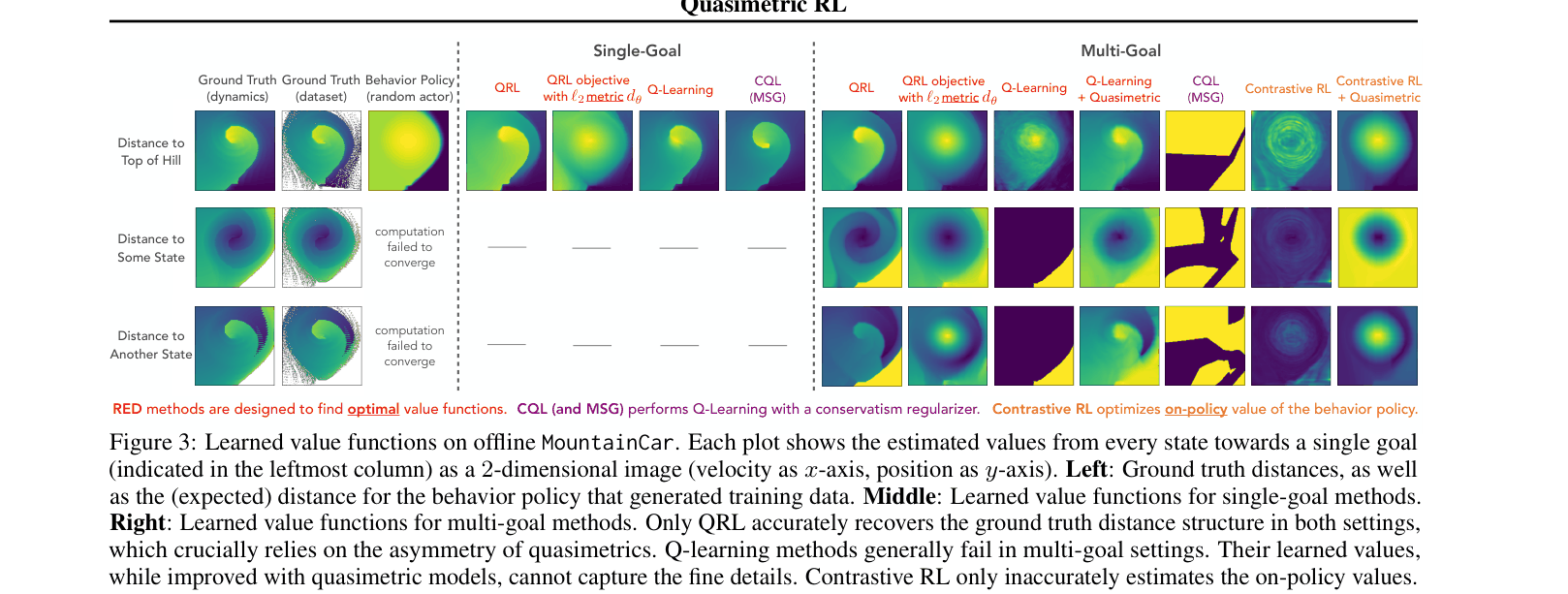
In a discretized MountainCar environment, standard Q-learning fails to learn the correct distance structure for reaching the hilltop from various states. Contrastive RL learns a symmetric or on-policy value that doesn't reflect optimal behavior. QRL accurately recovers the 'kidney bean' shape of the true optimal value function, reflecting that gaining momentum is necessary.
Key Novelty
Quasimetric Reinforcement Learning (QRL)
- Models the value function as a quasimetric (a distance metric allowing asymmetry), which is the mathematically exact structure of optimal goal-conditioned value functions.
- Uses a 'rubber band' intuition: enforces local consistency with transition costs (don't overestimate local steps) while pushing all other state pairs as far apart as possible (maximizing the metric).
- Provably recovers the optimal value function because the 'tightest' quasimetric that satisfies local transition constraints corresponds exactly to the shortest path costs.
Architecture
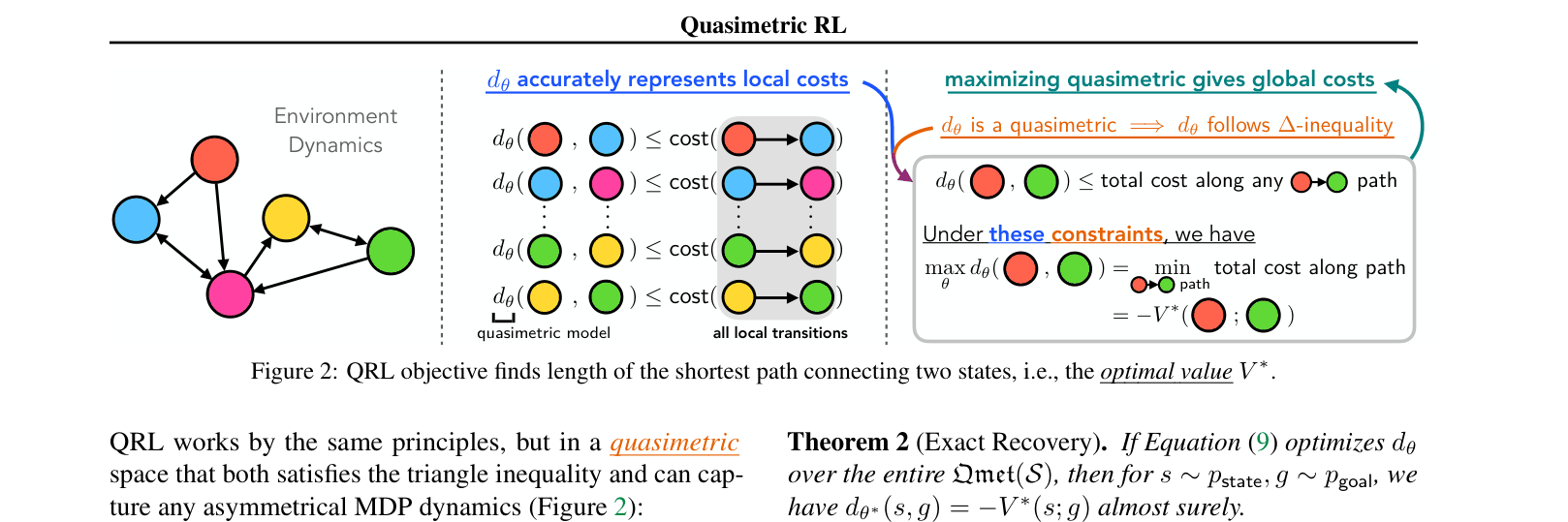
Conceptual illustration of the QRL objective using a 'rubber band' analogy.
Evaluation Highlights
- Outperforms Contrastive RL and standard Q-learning by large margins on discretized MountainCar, achieving >95% success vs <20% for Diffuser in multi-goal settings.
- +37% improvement over the best baseline (CQL) and +46% over handcoded controllers on offline Maze2D tasks.
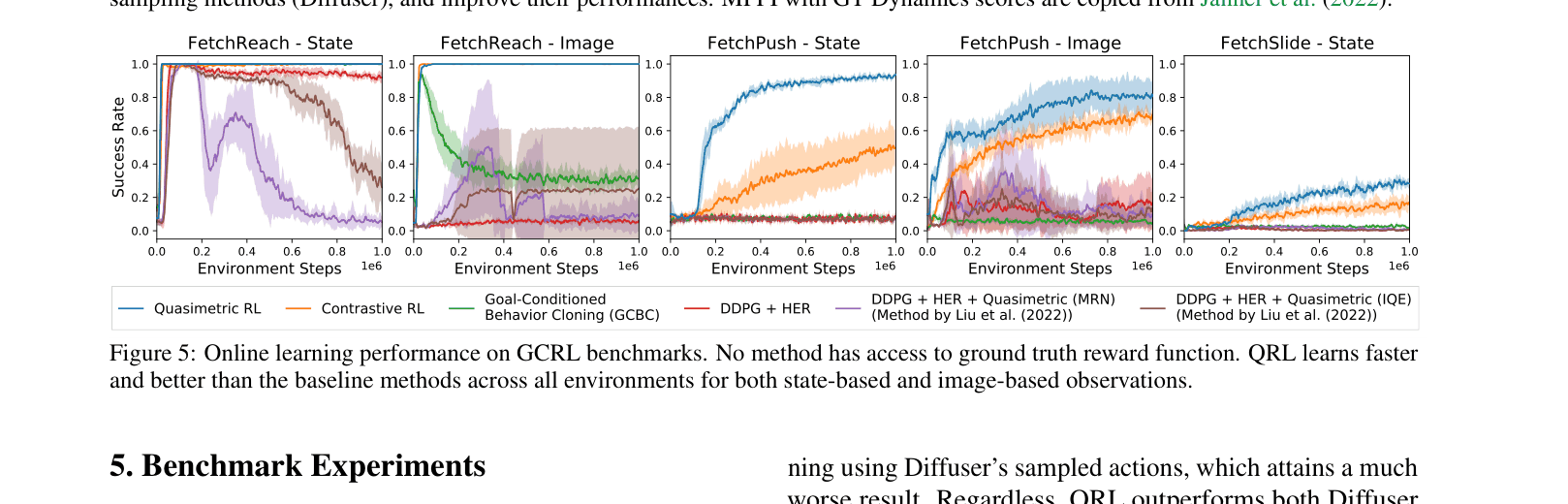
- Up to 4.9x improved sample efficiency in online goal-reaching benchmarks (state-based and image-based) compared to baselines like standard Q-learning with quasimetric models.
Breakthrough Assessment
8/10
Strong theoretical grounding linking value functions to quasimetrics, combined with a novel objective that departs from standard Bellman updates. empirical results show significant gains in sample efficiency and optimality.