📝 Paper Summary
Offline Reinforcement Learning
Off-Dynamics Reinforcement Learning
Sim-to-Real Transfer
REAG enables Decision Transformers to learn optimal target policies from source domain data with mismatched dynamics by augmenting the source returns to match the target return distribution.
Core Problem
Training policies in a source environment with different dynamics (e.g., simulation) often fails in the target environment (e.g., real world) due to dynamics shifts, and existing reward augmentation methods for dynamic programming do not work for return-conditioned supervised learning.
Why it matters:
- Collecting data in target environments (e.g., medical treatment, autonomous driving) is often costly, unethical, or dangerous, necessitating training on safer source domains
- Previous augmentation methods (DARA) rely on trajectory matching that is incompatible with the return-conditioned nature of Decision Transformers, which generate a family of policies rather than a single optimal one
- Directly applying source-trained policies to target environments leads to catastrophic failures due to the simulation-to-reality gap
Concrete Example:
In a Hopper task where the source agent has a crippled leg (modified dynamics) but the target agent is healthy, a standard Decision Transformer trained on source data learns to compensate for the limp. When deployed on the healthy target agent, this compensation results in suboptimal, erratic movement because the expected return-to-go no longer aligns with the actual dynamics.
Key Novelty
Return Augmented Decision Transformer (REAG)
- Augments the return-to-go labels in the abundant source dataset to align with the return distribution of the scarce target dataset, bridging the dynamics gap
- Proposes two variants: REAG-DARA (derived from probabilistic trajectory matching) and REAG-MV (directly matching the mean and variance of return distributions via Laplace approximation)
- Unlike reward augmentation which modifies immediate rewards, this modifies the *conditioning* variable (return-to-go), allowing the DT to learn a policy that generalizes across desired returns in the target environment
Architecture
Conceptual flow of the REAG framework: Source data returns are transformed via ψ(g) before training the DT.
Evaluation Highlights
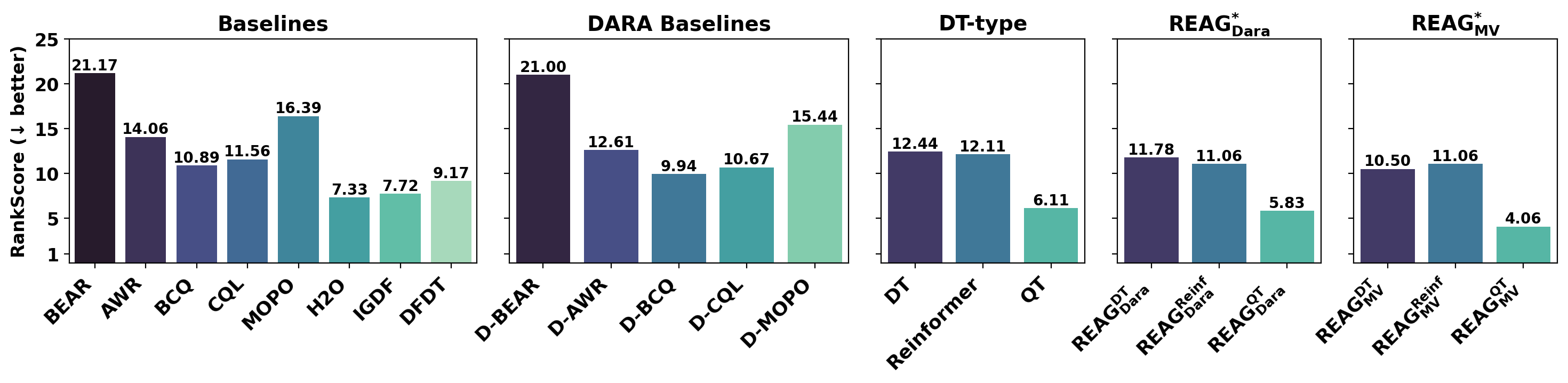
- REAG-MV improves Decision Transformer performance by ~15-30% over standard DT on D4RL MuJoCo tasks with mismatched dynamics (e.g., gravity changes, crippled joints)
- Achieves comparable suboptimality to training directly on target data, despite using primarily source data with modified dynamics
- REAG-MV consistently outperforms the REAG-DARA variant, showing that direct return distribution matching is more effective for RCSL than trajectory-likelihood matching
Breakthrough Assessment
7/10
First method to adapt Decision Transformers to off-dynamics settings via return augmentation. Theoretically grounded and empirically effective, though primarily evaluated on standard MuJoCo modifications.
