📝 Paper Summary
Offline Reinforcement Learning
Non-stationary Environments
Representation Learning for RL
COSPA handles slowly evolving non-stationarity in offline RL by using contrastive predictive coding to infer hidden environment parameters from trajectory histories and conditioning the policy on predictions.
Core Problem
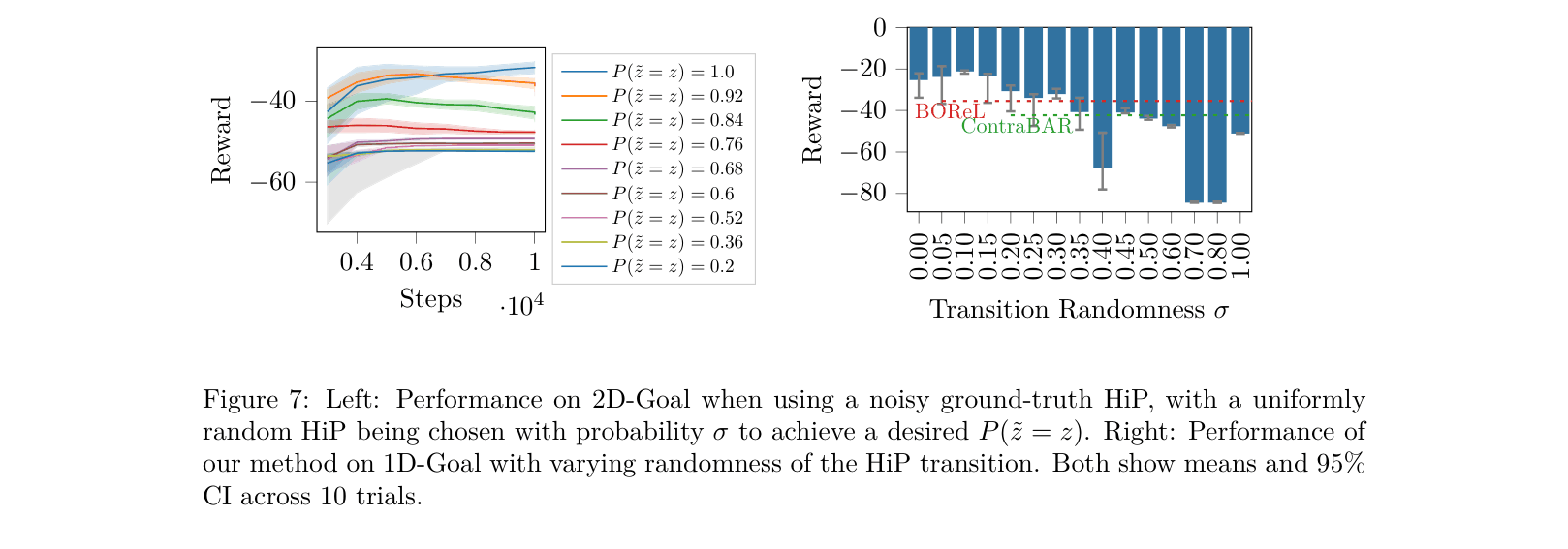
Standard Offline RL fails when deployed in environments with non-stationary transition or reward functions caused by factors like wear-and-tear over long data collection periods.
Why it matters:
- Real-world robots suffer from physical degradation (wear and tear) over time, invalidating the stationarity assumption of standard RL
- Existing Bayes-Adaptive methods (like BOReL) rely on techniques like reward relabeling or simulators that are often unavailable in offline settings
- Generative approaches (VAEs) struggle to model complex high-dimensional transition shifts compared to discriminative approaches
Concrete Example:
Consider a robot collecting data over months where joint friction gradually increases. A standard offline policy treats all data as coming from one physics model, leading to failure when deployed. COSPA infers the specific friction level from recent trajectories to adjust the policy.
Key Novelty
Contrastive Predictive Non-Stationarity Adaptation (COSPA)
- Treats the problem as a Dynamic-Parameter MDP where a hidden parameter (HiP) evolves between episodes but stays fixed within them
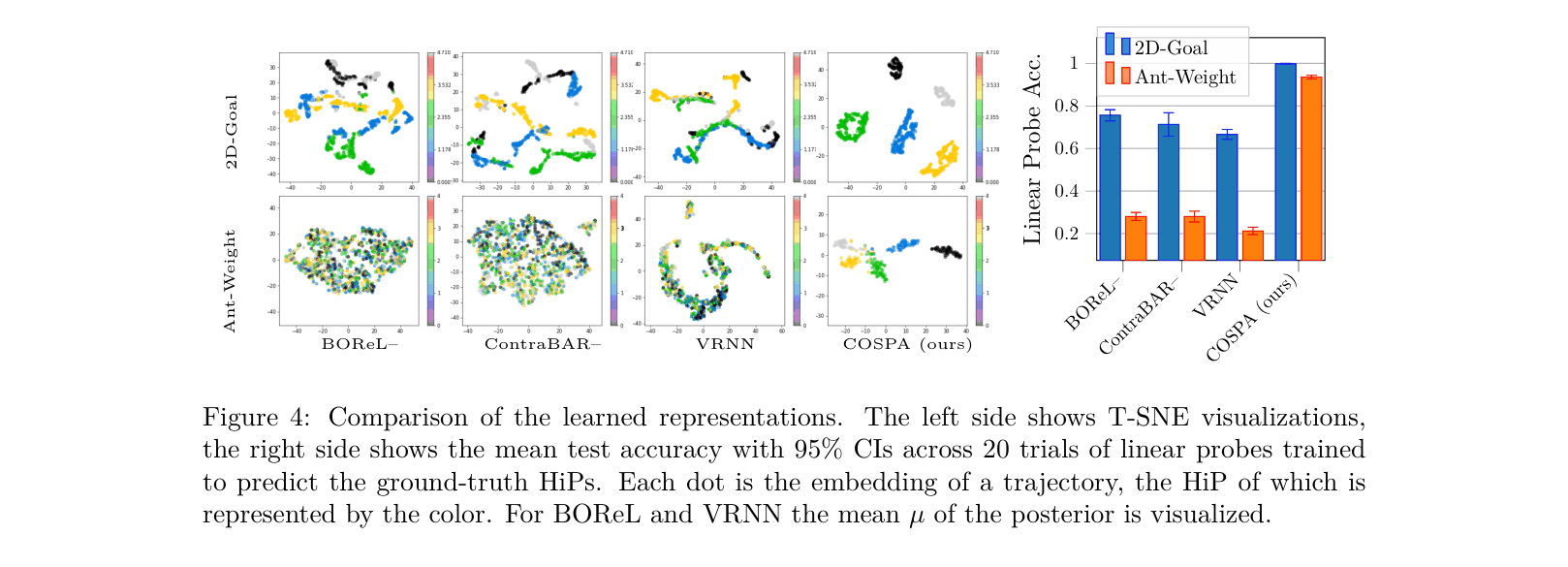
- Uses Contrastive Predictive Coding (CPC) to learn a discriminative representation of the HiP by distinguishing future trajectories from random ones
- Decouples inference and control: learns the HiP representation first, then trains a predictor for evaluation, and finally conditions a TD3+BC policy on the inferred HiP
Architecture
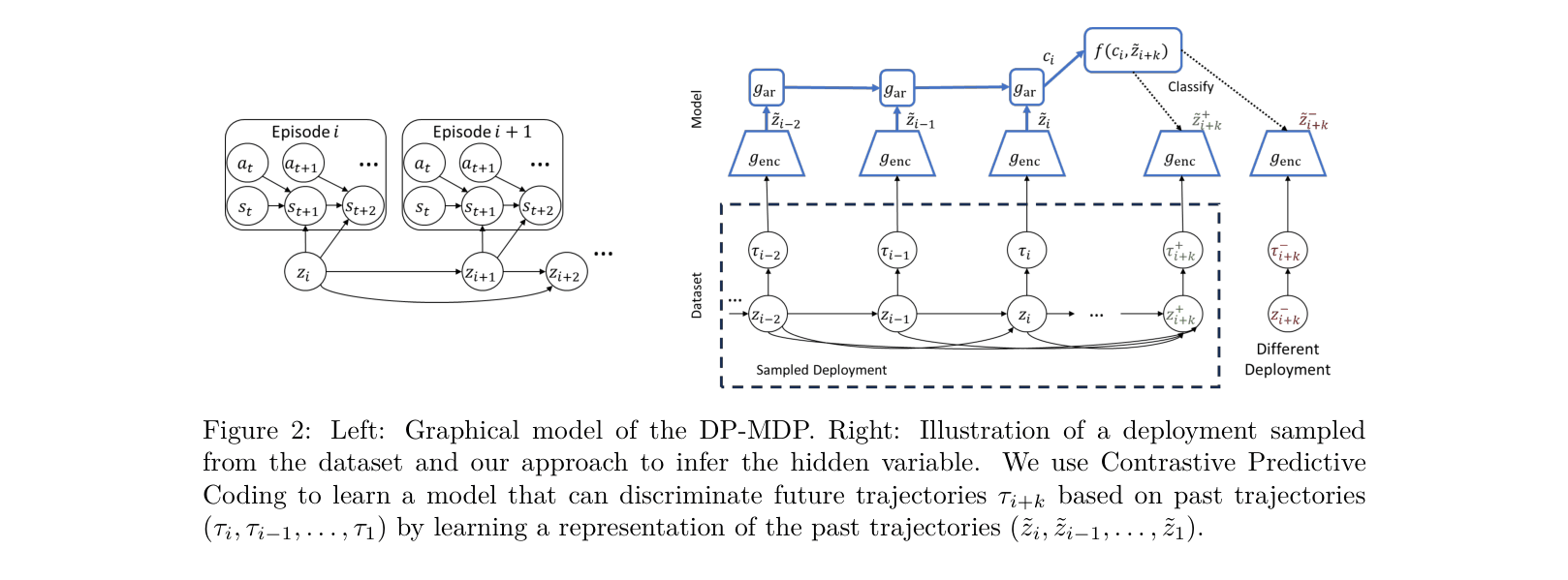
Conceptual diagram of the inference pipeline. It illustrates how trajectories from a deployment are encoded and used to predict future trajectories.
Evaluation Highlights
- Outperforms the Oracle (which has access to ground truth parameters) on the high-dimensional Ant-Weight task (3104 vs 2750 return)
- Achieves superior performance over Bayes-Adaptive baselines (BOReL, ContraBAR) in complex locomotion tasks like Barkour-Weight (+3.23 reward vs BOReL)
- Demonstrates robust generalization in 1D-Goal task, exceeding Oracle performance (-18.59 vs -20.79 return)
Breakthrough Assessment
7/10
Identifies a realistic, under-explored problem setting (structured non-stationarity in offline RL) and provides a solid, pragmatic solution that outperforms relevant baselines, though the method is a combination of existing components (CPC + TD3).