📝 Paper Summary
Legged Locomotion
Sim-to-Real Transfer
Robot Control
A model-free reinforcement learning torque controller enables a monoped robot to hop at variable heights using only proprioceptive data, eliminating the need for explicit state machines or height estimators.
Core Problem
Classical hopping controllers rely on complex finite state machines, manual tuning, and explicit estimation of jump phases (lift-off, touchdown), which are brittle and difficult to transfer to real hardware.
Why it matters:
- Hopping allows robots to clear obstacles that wheeled or walking robots cannot, but the flight phase significantly increases control complexity due to lack of actuation authority.
- Existing methods typically require heuristics for contact detection and height estimation, which fail if sensors are noisy or model dynamics are inaccurate.
- Using PD controllers in RL (common practice) limits the exploitation of full system dynamics compared to direct torque control.
Concrete Example:
A traditional hopping controller must detect 'touchdown' to switch from position control (flight) to force control (stance). If the height estimator drifts or contact sensors are noisy, the controller switches at the wrong time, causing the robot to crash or stumble.
Key Novelty
End-to-End Proprioceptive Torque Control for Hopping
- Replaces finite state machines and PD loops with a single neural network policy that maps history of joint states directly to motor torques.
- Achieves implicit phase detection (lift-off/touchdown) purely through proprioceptive history, removing the need for external contact sensors or explicit height estimators.
- Uses an energy-shaping inspired reward function to encourage periodic hopping behavior without strictly prescribing trajectories.
Architecture
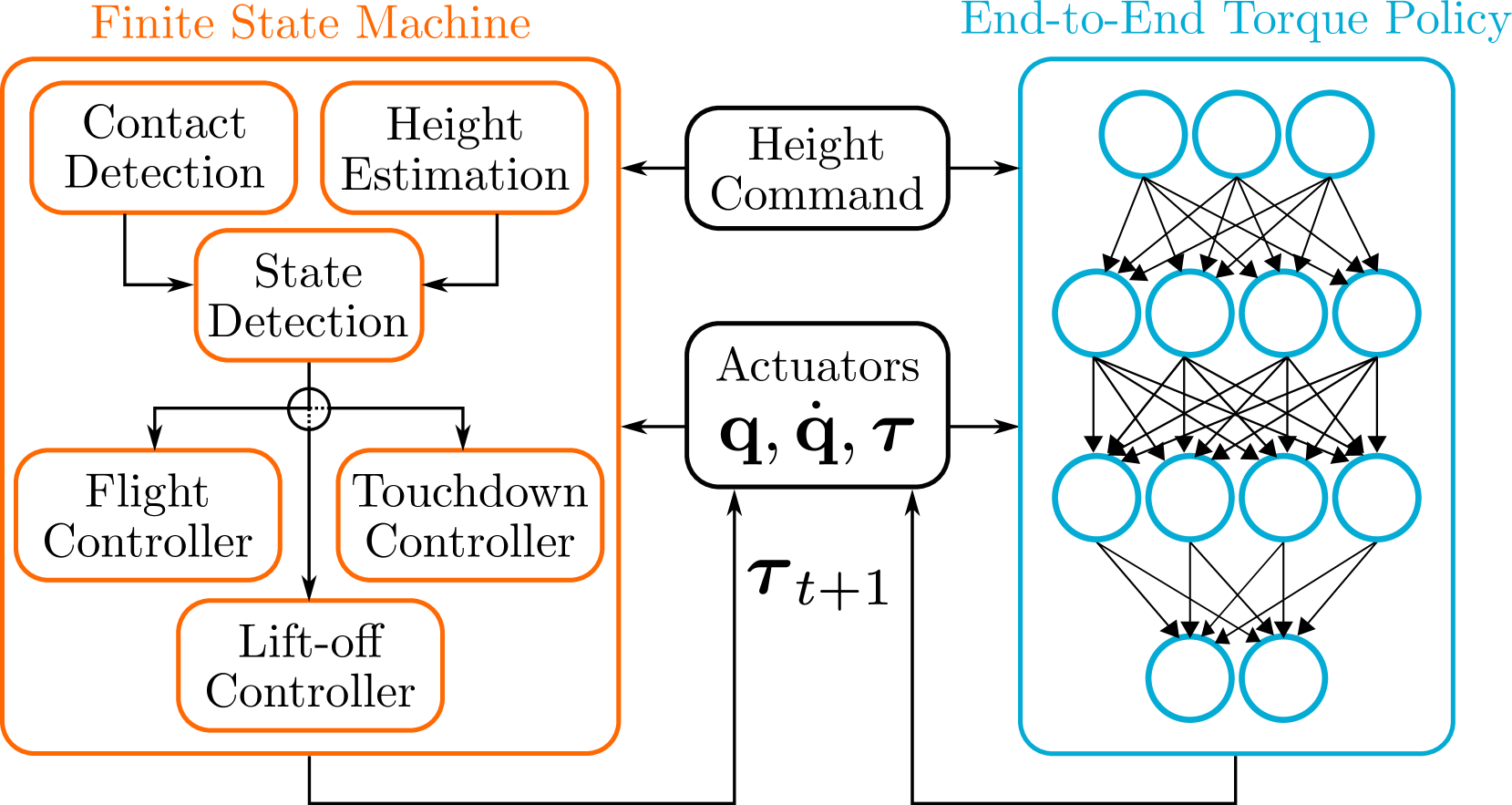
Comparison between the classical control loop and the proposed RL control loop.
Evaluation Highlights
- Successfully transferred to real hardware (200Hz control loop) without parameter tuning, achieving stable continuous hopping.
- Demonstrated variable height control by tracking desired jump height commands (e.g., oscillating between 0.3m and 0.45m).
- Learned to implicitly detect ground contact phases solely from joint positions and velocities, matching the behavior of state-machine baselines without explicit logic.
Breakthrough Assessment
7/10
Significant for demonstrating truly end-to-end torque control for a highly dynamic task (hopping) without state machines. The sim-to-real methodology is solid, though the task is limited to a 1D-constrained monoped.

