📝 Paper Summary
Reinforcement Learning
Heuristic-Guided RL
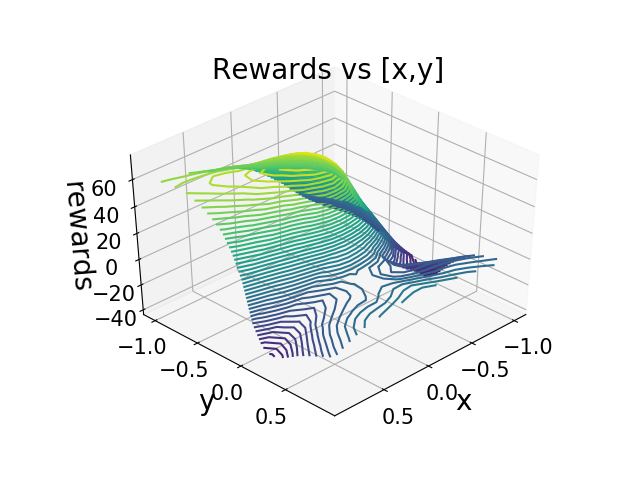
A reinforcement learning framework that accelerates early training using heuristic guidance (distance and angle to goal) which decays over time to prevent permanent human bias.
Core Problem
Reinforcement learning agents struggle with sparse rewards during early training because random exploration rarely discovers positive states, while permanent heuristics introduce suboptimal human bias.
Why it matters:
- Robots learning from scratch (tabula rasa) waste significant time in 'zigzag' learning before finding any positive signal
- Environments like Lunar Lander only provide substantial rewards upon successful termination, making early random exploration inefficient
- Existing heuristic methods often introduce permanent bias, preventing the agent from learning the true optimal policy once it has collected enough data
Concrete Example:
In the Lunar Lander game, a randomly acting agent will almost never land safely on the pad, receiving mostly crash penalties (-100). If a fixed heuristic reward is added for staying upright, the agent might learn to just hover indefinitely to maximize that heuristic rather than actually landing.
Key Novelty
Vanishing Bias Heuristic RL
- Introduces a 'vanishing bias' mechanism where heuristic rewards (e.g., distance to goal) are added to the objective only during the early stages of training to guide exploration
- Applies a geometric decay factor to the heuristic weight over time, ensuring that human-defined bias gradually disappears and the agent eventually optimizes the true environmental reward
Architecture
The logic flow for Heuristic DQN, showing how the heuristic term is integrated into the target calculation