📝 Paper Summary
LLM Post-training
Offline Reinforcement Learning
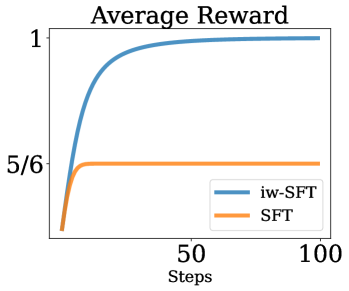
SFT on filtered data mathematically optimizes a lower bound on the sparse-reward RL objective, and a simple importance-weighting modification (iw-SFT) tightens this bound to improve performance.
Core Problem
SFT on curated data is effective but theoretically viewed as distinct from RL, and it optimizes a lower bound on the RL objective that loosens as the model drifts from the reference distribution.
Why it matters:
- RL is notoriously difficult to tune and computationally expensive compared to SFT
- Understanding SFT as a specific case of RL allows for theoretical improvements that bridge the gap between simple SFT stability and RL performance
- Standard SFT cannot effectively incorporate information from failures or learn optimal policies when the reference data is suboptimal (e.g., multimodal distributions with bad modes)
Concrete Example:
In a toy bandit problem where an optimal action is 'pull-right' but the reference data is 50/50 'pull-left'/'pull-right', standard SFT on successful trials results in a suboptimal policy (33% left / 66% right). iw-SFT, by reweighting successful trajectories, recovers the optimal policy (100% right).
Key Novelty
Importance Weighted Supervised Fine-Tuning (iw-SFT)
- Reframes SFT on filtered data as maximizing a lower bound on the RL objective in sparse reward settings
- Introduces an importance-weighting term to the SFT loss that tightens the lower bound as the model trains, effectively 'adaptive-filtering' data based on the model's current probability
- Demonstrates that this simple modification allows SFT to approach RL performance without complex RL machinery (like value functions or PPO clipping)
Architecture
The iterative training process of iw-SFT.
Evaluation Highlights
- Achieves 66.7% accuracy on AIME 2024 (reasoning benchmark) using iw-SFT, outperforming standard SFT on the same curated data
- Achieves 64.1% on GPQA, surpassing standard SFT baselines
- Outperforms state-of-the-art offline RL baselines (IQL, AWAC) on D4RL continuous control tasks (MuJoCo) using the same importance-weighted logic
Breakthrough Assessment
8/10
Provides a strong theoretical unification of SFT and RL for LLMs. The method is extremely simple to implement (just reweighting loss) yet yields significant gains on difficult reasoning benchmarks.