📝 Paper Summary
Instruction Tuning (IT)
Supervised Fine-Tuning (SFT)
Dataset Construction
This survey systematizes the field of Instruction Tuning, categorizing methodologies into human-crafted, distillation, and self-improvement strategies, with a specific focus on constructing high-quality datasets for general and reasoning capabilities.
Core Problem
Pre-trained Large Language Models (LLMs) are optimized for next-word prediction, which mismatches the user objective of following instructions helpfully and safely.
Why it matters:
- LLMs trained only on raw corpora often fail to adhere to human constraints or specific formats
- Crafting high-quality instruction datasets is non-trivial due to limitations in quantity, diversity, and creativity of manually annotated data
- Standard LLMs lack controllability and predictability compared to models fine-tuned on explicit (instruction, output) pairs
Concrete Example:
A user might ask an LLM to 'Write a thank-you letter'. A raw pre-trained model might continue the text with similar prompts like 'Write a resignation letter' (next-token prediction behavior) rather than actually writing the letter (instruction-following behavior).
Key Novelty
Comprehensive Taxonomy of Instruction Tuning Data
- Classifies dataset construction into three distinct pillars: Human-crafted (manual/integrated), Synthetic via Distillation (teacher-student), and Synthetic via Self-improvement (bootstrapping)
- incorporates the latest reasoning-focused datasets (e.g., DeepSeekMath, PRM800K) that utilize iterative loops and process supervision
- Reviews self-play and back-translation mechanisms that allow models to improve without stronger external teacher models
Architecture
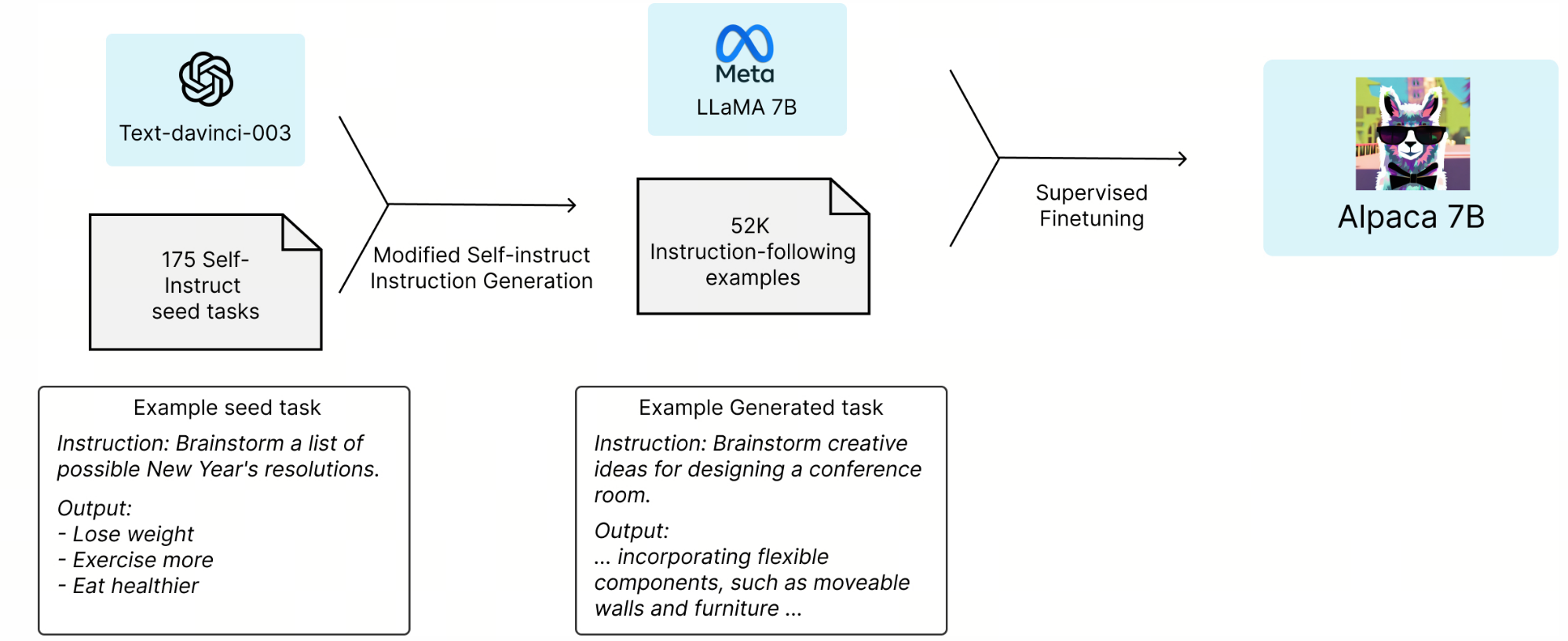
The Self-Instruct pipeline illustrating how a model generates its own training data
Evaluation Highlights
- WizardLM achieves >90% of ChatGPT's capacity on 17 out of 29 skills using complex evolved instructions
- Self-Instruct method allows a vanilla GPT-3 model to perform within a 5% gap of InstructGPT
- LLaMA fine-tuned on instruction back-translated data (502K pairs) surpasses all other LLaMA-based models on the Alpaca leaderboard
Breakthrough Assessment
9/10
An extensive and up-to-date survey (updated through 2025) that captures the rapid evolution from basic SFT to advanced reasoning and self-improvement techniques.