📝 Paper Summary
Cross-lingual alignment
In-context learning / Prompt engineering
The paper introduces 'Pretty,' a training-free method that aligns foundation models to cross-lingual tasks by injecting just one or two task-related prior tokens during decoding, rivaling supervised fine-tuning performance.
Core Problem
Foundation LLMs struggle to follow cross-lingual instructions (e.g., often replying in English instead of the target language) despite having the latent knowledge, and Supervised Fine-Tuning (SFT) is costly and potentially degrades pre-training knowledge.
Why it matters:
- SFT requires expensive, high-quality non-English instruction data which is scarce for many languages
- SFT carries risks of 'catastrophic forgetting' where the model loses general pre-training capabilities
- Current cross-lingual alignment methods rely heavily on training, creating a barrier for democratizing multilingual LLMs
Concrete Example:
When prompted with 'Translate this to Chinese: [English text]', a foundation model like Llama-2 often continues generating text in English or repeating the input, failing to switch languages. SFT fixes this, but the paper shows this 'alignment' is superficial and can be mimicked by simply forcing the foundation model to start its output with a specific target-language token.
Key Novelty
Prefix Text as a Yarn (Pretty)
- Demonstrates that SFT's primary contribution in cross-lingual tasks is steering the first few tokens; once steered, the foundation model's 'silent majority' of probabilities aligns with the SFT model
- Proposes a training-free inference strategy that appends 1-2 task-specific tokens (e.g., the first token of a translation) to the input prompt
- Forces the foundation model to resume decoding from these 'prior tokens,' effectively unlocking its latent cross-lingual capabilities without parameter updates
Architecture
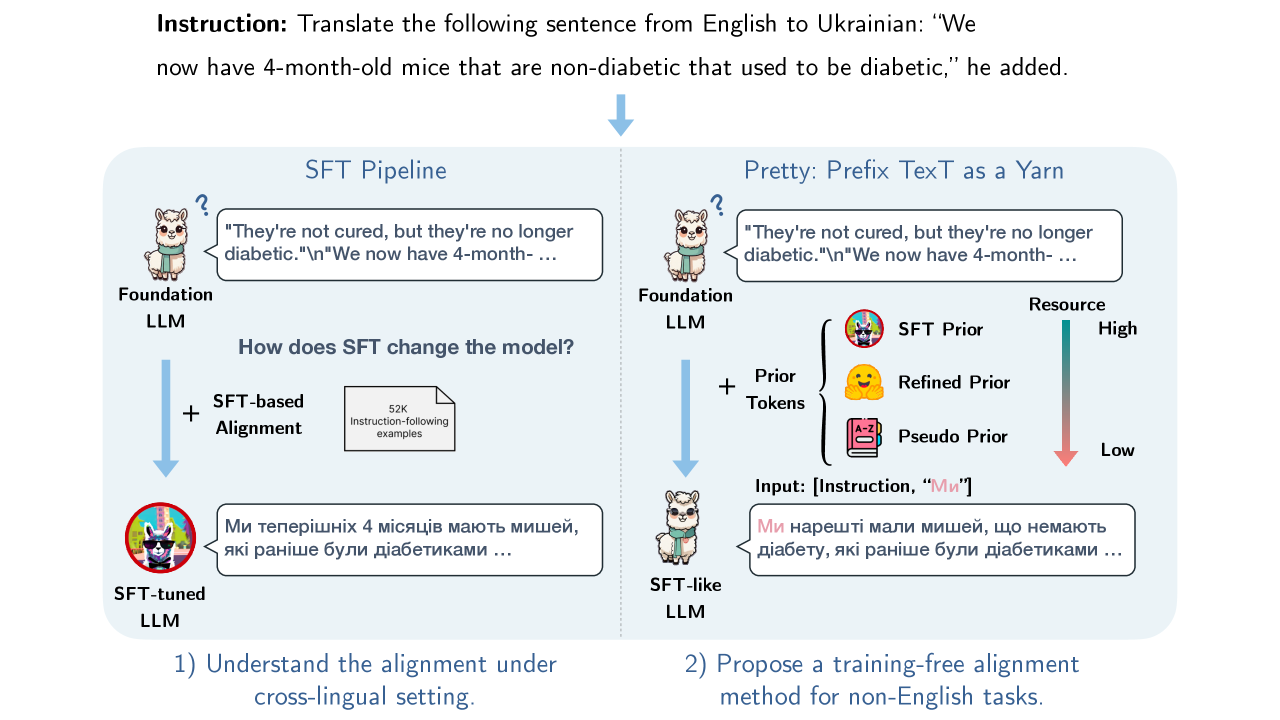
Comparison of decoding behaviors between a Foundation Model, an SFT Model, and the 'Pretty' method.
Evaluation Highlights
- Achieves comparable performance to SFT models on machine translation, summarization, and POS tagging across 8 languages using only 2 prior tokens
- Using a single prior token, the foundation model's token selection aligns with the SFT model 90.8% of the time (within top-20 probabilities)
- Significantly reduces the disparity in decision space (measured by KL divergence) between foundation and SFT models without any training
Breakthrough Assessment
7/10
Provides a strong counter-narrative to the necessity of SFT for alignment, offering a simple, training-free alternative. While the method is simple, the insight about the 'superficiality' of cross-lingual alignment is significant.