📝 Paper Summary
Code Generation
Competitive Programming
Synthetic Data Generation
X-Coder demonstrates that a fully synthetic data pipeline, using domain-specific feature evolution and dual-verification of solutions and tests, can train expert-level competitive programming models without real-world data.
Core Problem
Training expert-level code reasoning models is bottlenecked by the scarcity of high-quality competitive programming data; existing real-world datasets are small and contaminated, while standard synthetic methods lack the complexity and correctness rigor required.
Why it matters:
- Real-world competitive programming problems are finite and heavily exhausted, limiting scaling laws for reasoning models
- Off-the-shelf synthesis methods often yield trivial or ill-defined tasks that fail to challenge models
- Without rigorous verification, synthetic solutions and tests contain noise that pollutes SFT and misleads RL
Concrete Example:
Generating a competitive task often results in simple problems solvable by basic logic. Without strict verification, a synthetic solution might pass weak test cases but fail on edge cases, providing false rewards during RL training.
Key Novelty
Domain-Adapted Feature Evolution & Dual-Verification Synthesis
- Evolve tasks not from generic instructions but from specific 'competition-related features' extracted from code snippets, using a two-stage process to ensure complexity
- Implement a dual-verification strategy where candidate solutions vote to establish ground truth outputs for tests, and then tests (weighted by difficulty) verify the best solution
Architecture
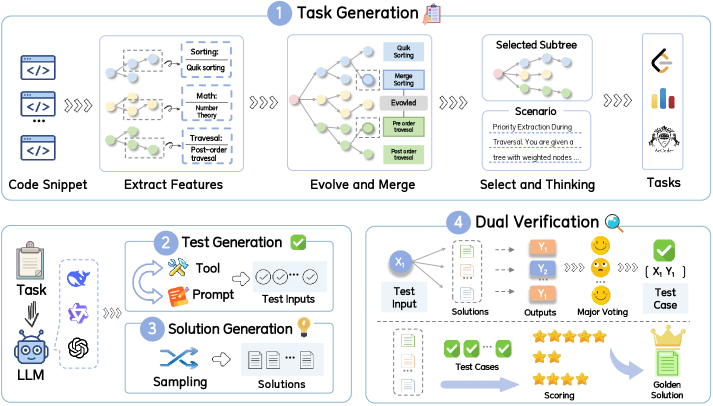
The synthesis pipeline for constructing the X-Coder dataset.
Evaluation Highlights
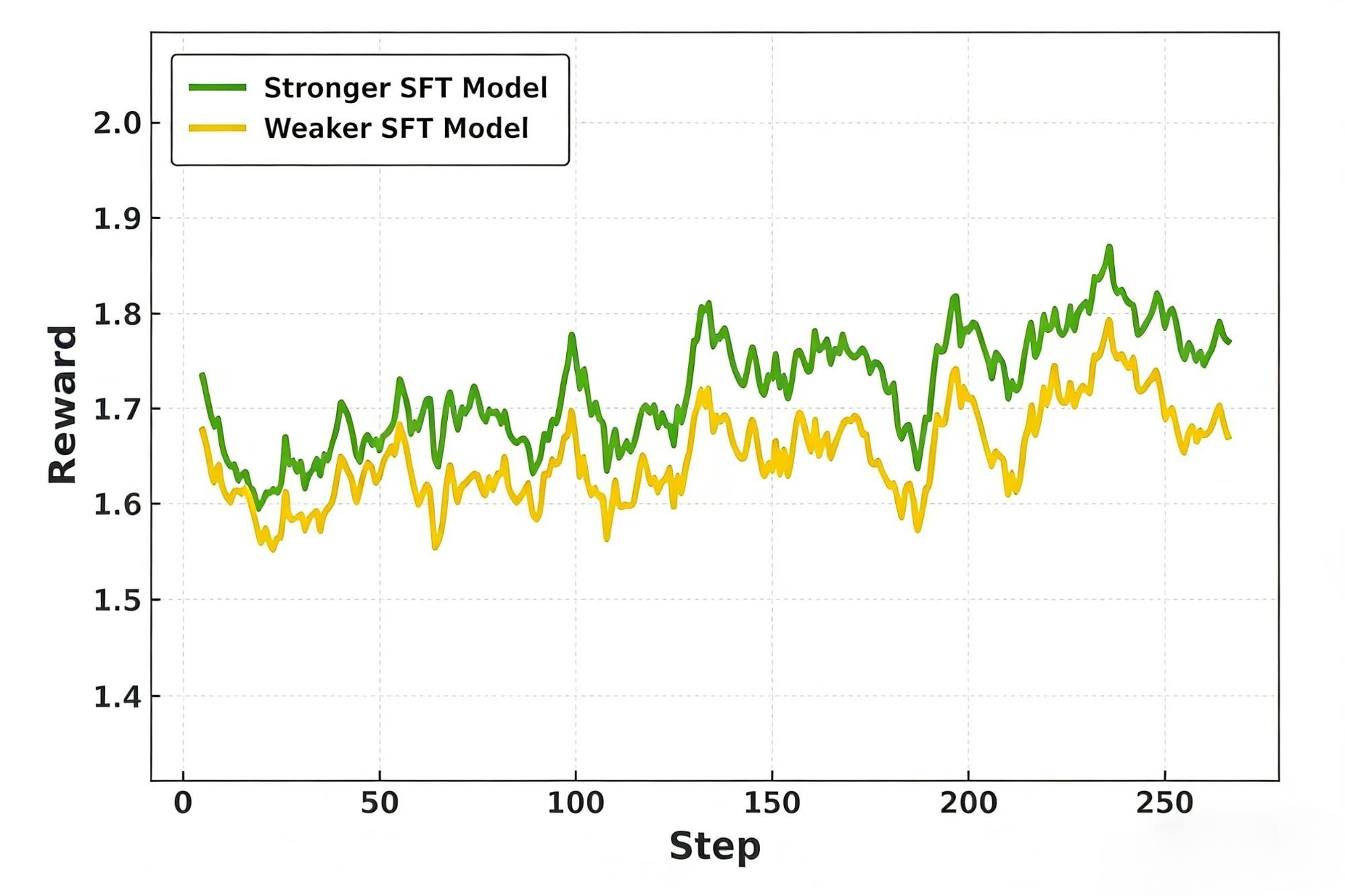
- +6.7 pass@8 improvement on LiveCodeBench (SFT stage) compared to OpenCodeReasoning (real-world data) when trained on equal tokens
- X-Coder-7B achieves 62.9% pass@8 on LiveCodeBench v5, outperforming larger models like DeepCoder-Preview-14B
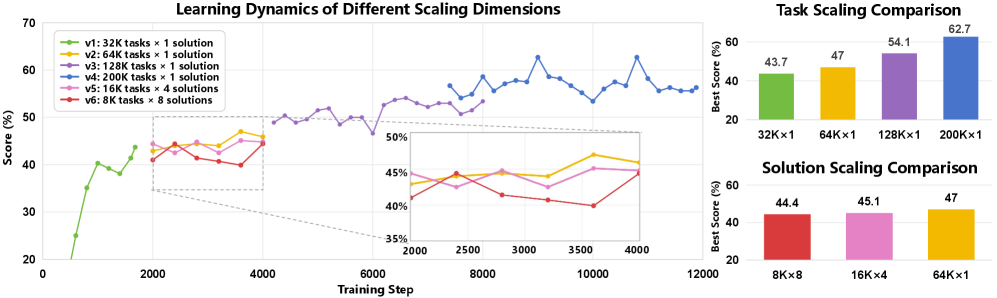
- Synthetic data scaling shows monotonic improvement: scaling unique tasks is significantly more effective than scaling solutions per task
Breakthrough Assessment
8/10
Strong empirical evidence that fully synthetic data can replace real-world data for complex reasoning tasks. The rigorous dual-verification pipeline addresses key reliability issues in synthetic data.