📝 Paper Summary
Video Large Language Models
Temporal Reasoning
Model Alignment
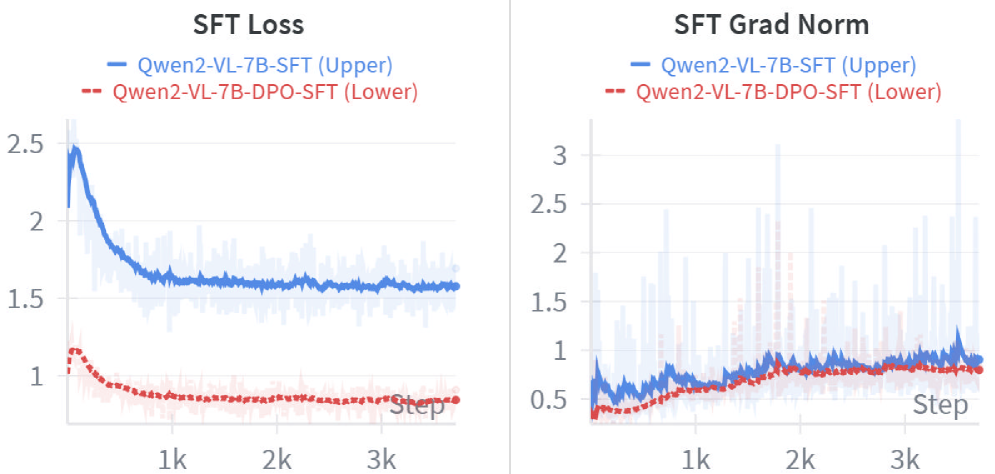
TEMPLE improves Video LLMs' temporal reasoning by generating synthetic preference pairs via video perturbation and applying Direct Preference Optimization before standard supervised fine-tuning.
Core Problem
Current Video LLMs struggle with temporal reasoning because standard next-token prediction on static datasets fails to enforce dynamic understanding, leading to reliance on visual shortcuts.
Why it matters:
- Models frequently hallucinate or overlook events in videos, leading to unreliable responses for dynamic content
- Existing datasets lack strong temporal correspondence, making it hard for models to learn event sequencing
- Standard post-SFT alignment assumes basic capabilities are already learned, but temporal understanding is often missing from the base model
Concrete Example:
In a video analysis of an archery clip, a standard model (Qwen2-VL) hallucinates that the archer 'releases the arrow' when the video only shows the preparation phase, failing to recognize the specific temporal segment provided.
Key Novelty
Progressive Pre-SFT Alignment with Synthetic Temporal Preferences
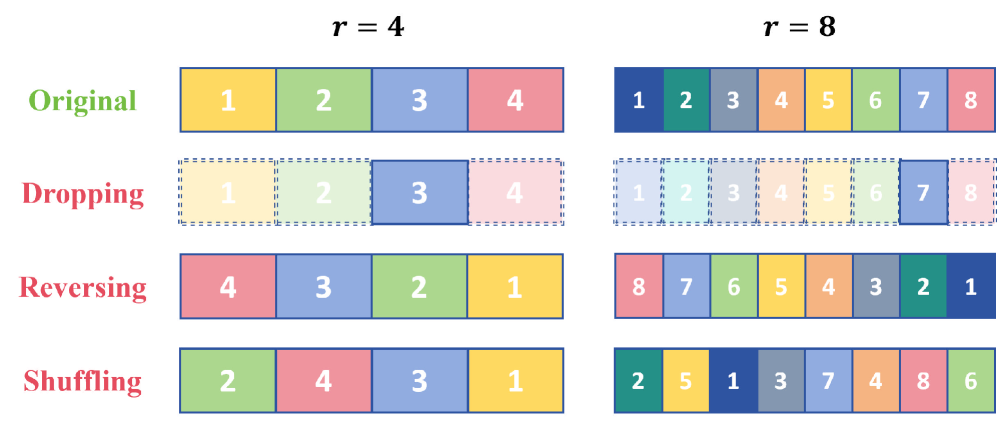
- Constructs a self-supervised preference dataset by comparing model responses to clean videos (chosen) vs. temporally perturbed videos (rejected) like reversed or shuffled clips
- Reverses the standard training order by applying DPO *before* instruction tuning (SFT) to establish fundamental temporal alignment first
- Uses a curriculum learning strategy that gradually increases the difficulty of perturbations during training to improve data efficiency
Architecture
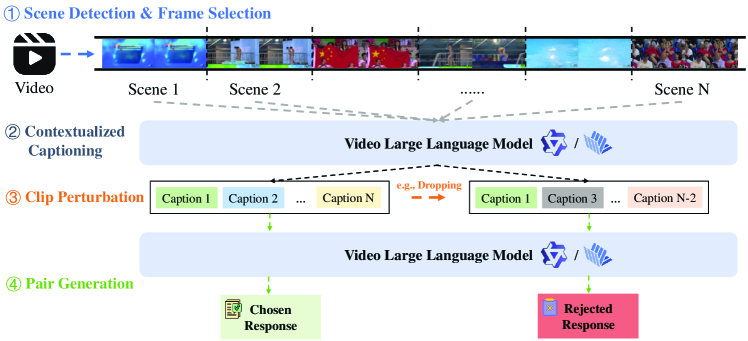
The automated data construction pipeline for TEMPLE.
Evaluation Highlights
- +3.4% improvement on Video-MME (temporal dimension) using Qwen2-VL-7B compared to standard SFT baselines
- Consistently outperforms standard SFT-then-DPO approaches across MLVU and Vinoground benchmarks with a relatively small set of self-generated data
- Demonstrates high transferability across different model architectures (LLaVA-Video, Kangaroo) and scales (7B, 8B)
Breakthrough Assessment
7/10
Offers a clever, scalable data generation pipeline and challenges the standard SFT-then-DPO paradigm. While improvements are consistent, they are incremental rather than transformative shifts in architecture.