📝 Paper Summary
Code Large Language Models
Automated Program Repair (APR)
PDC & DM-SFT enhances SQL bug-fixing in LLMs by mining real-world user repair patterns and training with a dynamic masking loss that focuses the model on code edits rather than unchanged lines.
Core Problem
Existing Code LLMs struggle with SQL bug repair because standard training treats all tokens equally, causing the loss function to be dominated by the large volume of unchanged code rather than the critical fixes.
Why it matters:
- SQL bugs often involve complex nested query structures that are harder to fix than errors in other languages
- Debugging SQL at the task level is time-consuming and computationally expensive, making efficient automated repair highly valuable
- Default generative fine-tuning leads to 'disorientation' and slow convergence because >92% of the code in bug-fixing samples remains identical to the input
Concrete Example:
In a SQL bug-fixing scenario, the input might be a 100-line query with a single syntax error. The correct output is nearly identical to the input. Standard SFT trains the model primarily to copy the 99 correct lines, diluting the signal for the 1 line that needs repair.
Key Novelty
Progressive Dataset Construction (PDC) & Dynamic Mask Supervised Fine-tuning (DM-SFT)
- PDC builds training data via 'breadth-first' mining of online user edit logs (extracting successful human fixes) and 'depth-first' synthetic generation of hard/rare bug types using Code LLMs
- DM-SFT modifies the training loss by randomly masking out lines of code that remain unchanged between input and output, forcing the model to focus its learning capacity on the 'diff' lines (the actual fixes)
Architecture
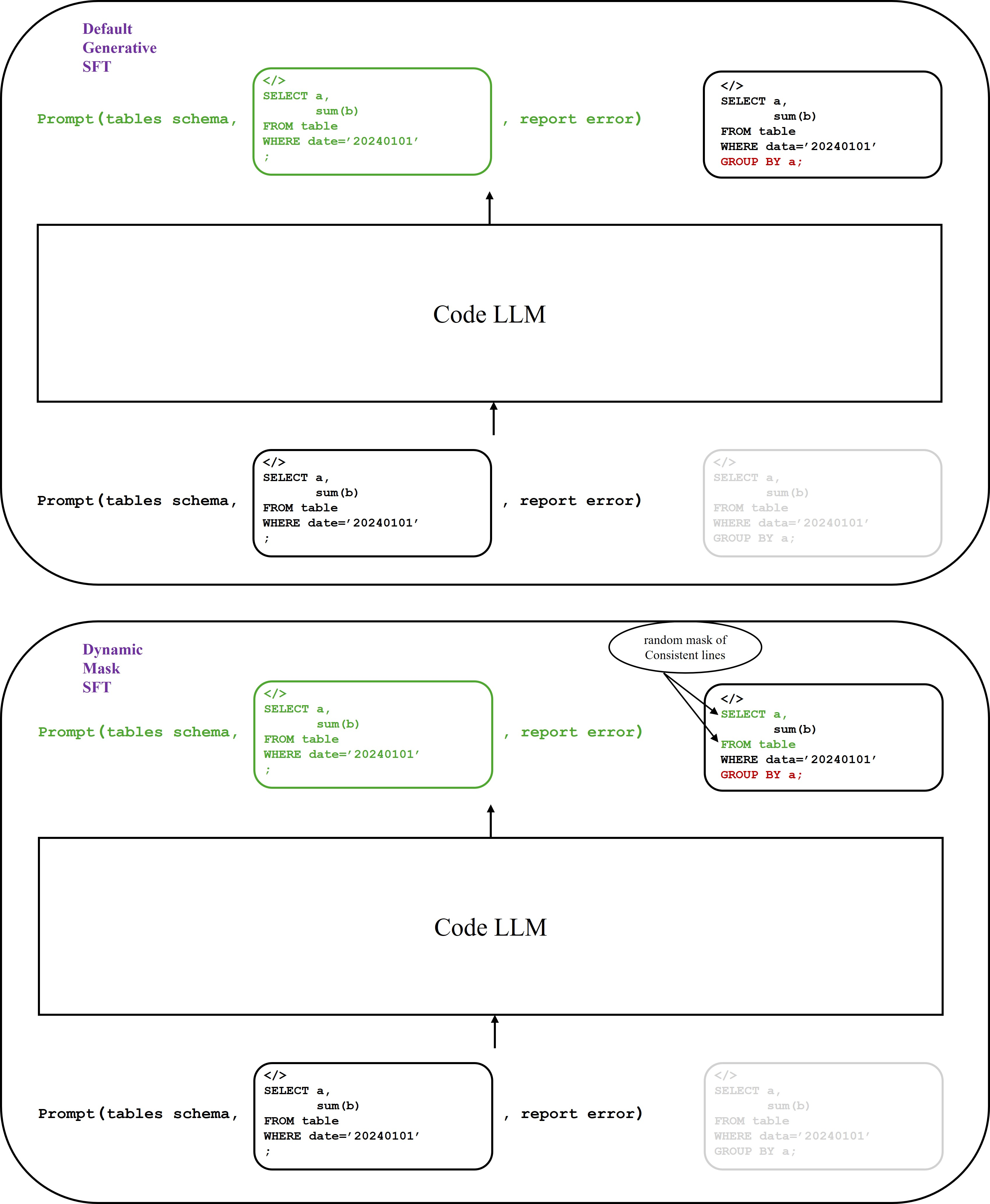
Comparison of Standard SFT vs. Dynamic Mask SFT loss calculation strategies.
Evaluation Highlights
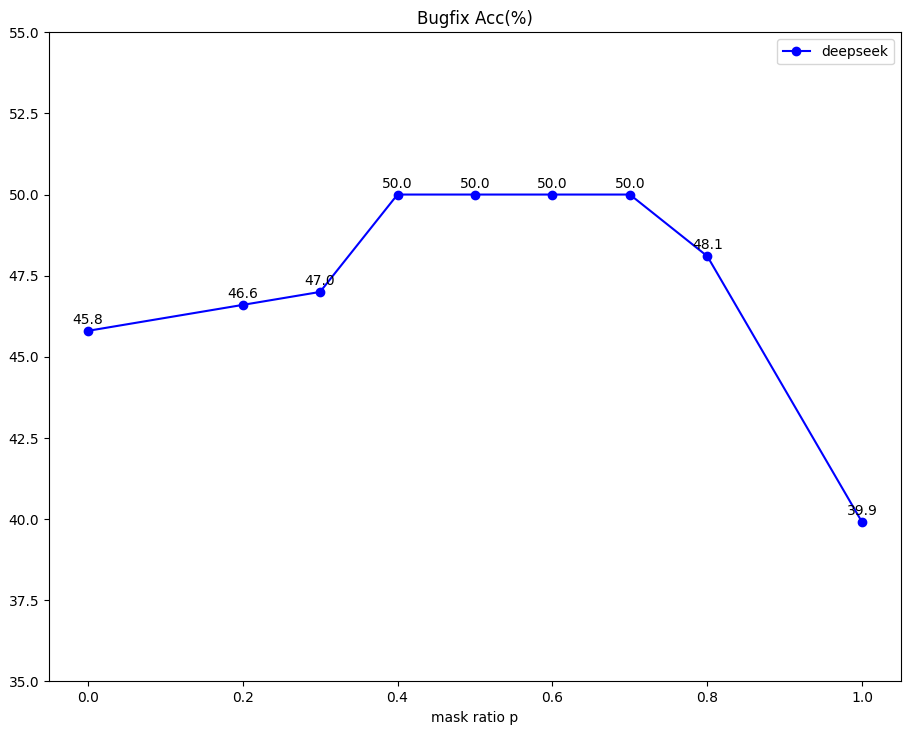
- Training with PDC data improves DeepSeek-Coder-6.7B-instruct's bug-fixing accuracy by over 50% relative to the base model (28.5% -> 43.8%)
- DM-SFT further improves performance by ~10% relative to standard SFT (e.g., DeepSeek-Coder-6.7B-instruct improves from 43.8% to 49.8%)
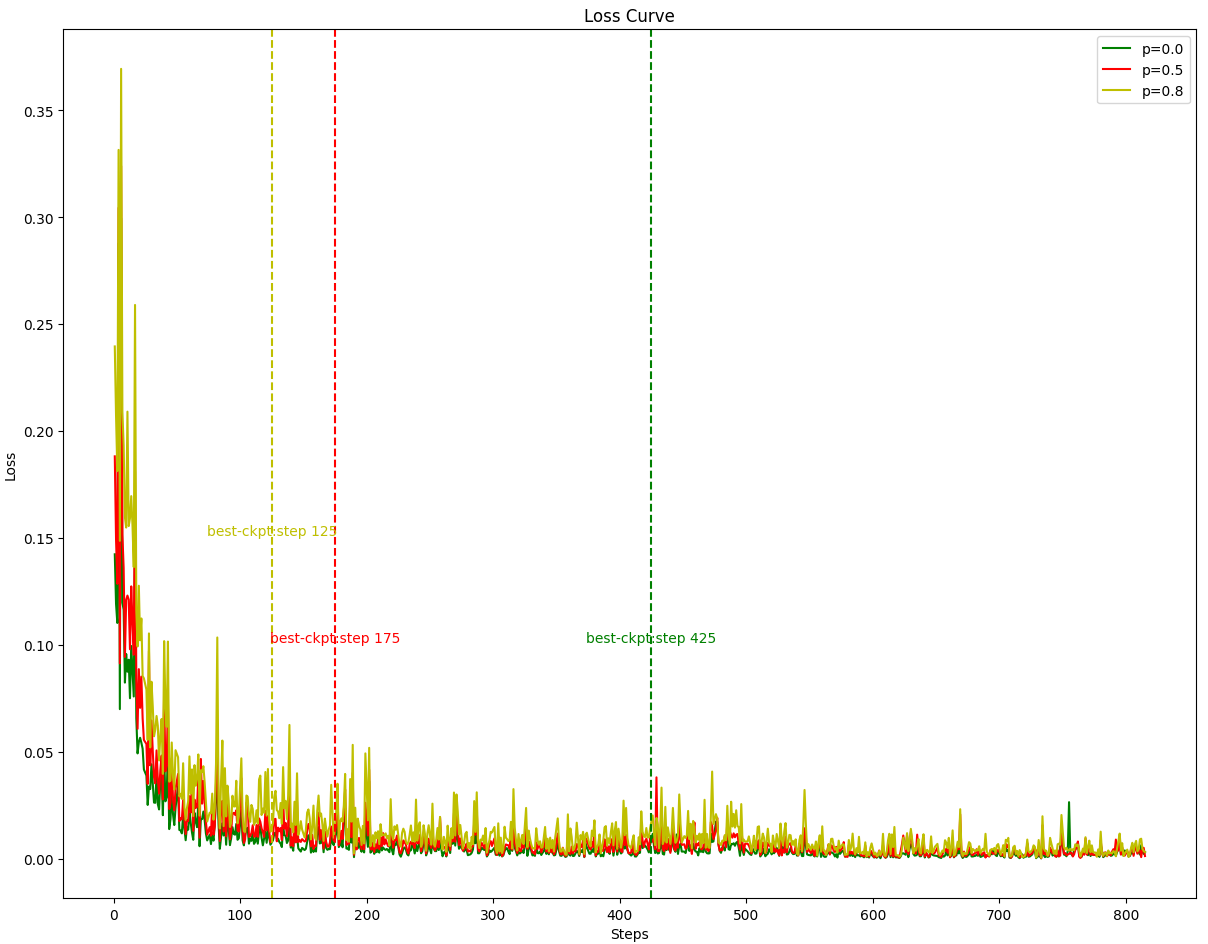
- DM-SFT accelerates convergence, requiring fewer training steps to reach optimal performance compared to default SFT
Breakthrough Assessment
7/10
Simple yet highly effective domain-specific adaptation of SFT for editing tasks. The methodology for mining user logs (PDC) is practical, and the dynamic masking (DM-SFT) addresses a fundamental inefficiency in training repair models.