📊 Experiments & Results
Evaluation Setup
Greedy and sampling-based generation (n=8) on math competition problems.
Benchmarks:
- AIME 2024 (High-school competition mathematics)
Metrics:
- avg@8 (Average pass rate over 8 attempts)
- cov@8 (Coverage: success in at least 1 of 8 attempts)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance on Medium-level questions shows that style transfer via minimal SFT (500-1K samples) is sufficient to reach near-perfect accuracy. | ||||
| AIME 2024 (Medium Tier) | avg@8 | 10.0 | 90.0 | +80.0 |
| On Hard-level questions, data scaling follows a logarithmic law but plateaus, and curation offers only minor benefits. | ||||
| AIME 2024 (Hard Tier) | avg@8 | 28.4 | 33.6 | +5.2 |
| AIME 2024 (Hard Tier) | avg@8 | 28.4 | 35.4 | +7.0 |
| Extremely Hard (Exh) questions represent a fundamental barrier for SFT models. | ||||
| AIME 2024 (Exh Tier) | avg@8 | 0.0 | 0.0 | 0.0 |
Experiment Figures
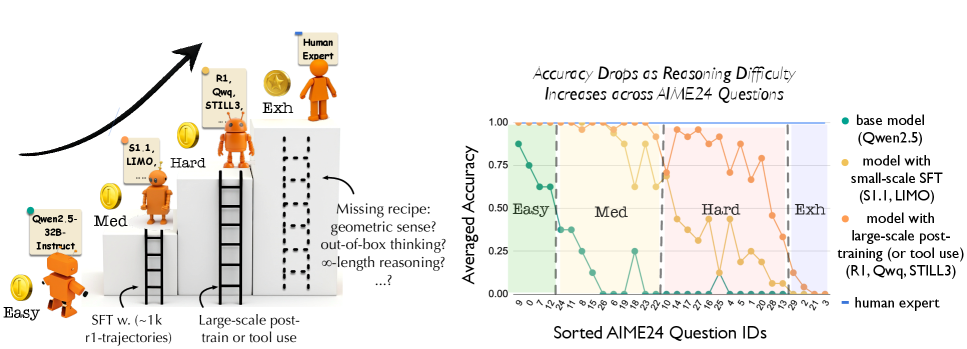
Heatmap of model performance across AIME24 questions sorted by difficulty, showing a clear 'ladder' structure.
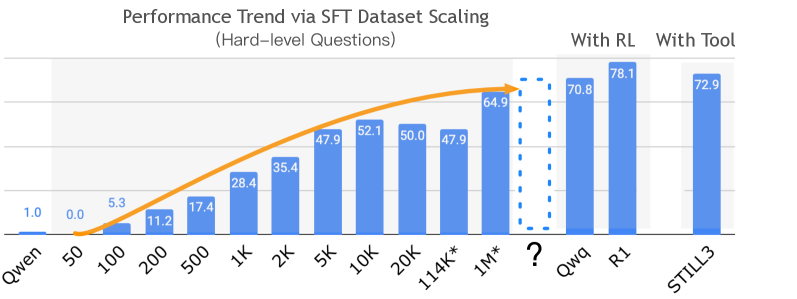
Scaling curves of accuracy vs. SFT dataset size for Hard-level questions.
Main Takeaways
- Progression from Easy to Medium is a 'sudden leap' driven by adopting the R1 reasoning style (long context, verification), requiring minimal data (500-1K samples).
- Progression from Medium to Hard is gradual and logarithmic; the bottleneck is 'stability' in long reasoning chains, which SFT improves but plateaus at ~65%.
- Extremely Hard problems are not solvable via SFT scaling; they require unconventional strategies or geometric intuition that current SFT trajectories do not effectively transfer.
- Careful data curation (finding similar problems) yields marginal gains compared to simply increasing dataset size for Hard problems.