📝 Paper Summary
Domain-specific Large Language Models
Industrial LLMs
Inference Acceleration
SOAEsV2-7B/72B optimizes Chinese State-Owned Enterprise language models through continual pre-training, curriculum-driven progressive fine-tuning, and logit-distilled speculative decoding for faster model inference.
Core Problem
Existing domain-specific Large Language Models (LLMs) for State-Owned Enterprises suffer from limited model capacity, abrupt domain shifts during single-stage fine-tuning, and slow inference speeds for larger models.
Why it matters:
- Overemphasizing generalizability leads to shallow integration of industry-specific knowledge, limiting accurate decision support for complex industrial tasks.
- Small 7-billion parameter models lack the capacity for deep domain knowledge, while large 72-billion parameter models suffer from critical inference latency bottlenecks in practical deployments.
- Traditional single-stage supervised fine-tuning neglects progressive knowledge transfer, preventing models from smoothly adapting from general capabilities to specialized domain expertise.
Concrete Example:
Traditional single-stage fine-tuning struggles with abrupt domain shifts when moving directly to expert State-Owned Assets and Enterprises (SOAEs) tasks, whereas progressive training smooths this transition by first building foundational competencies like financial analysis.
Key Novelty
Full-Pipeline SOAEs LLM Optimization Framework
- Injects domain knowledge into a massive 72-billion parameter model via continual pre-training on meticulously filtered corpora, enhancing capacity without catastrophic forgetting.
- Uses a two-stage curriculum, first training on weakly-relevant general dialogues, then on expert-annotated domain data to sequentially build specialized mastery.
- Accelerates inference using a small 7-billion parameter draft model aligned via logit distillation, reducing latency through a speculative decoding mechanism.
Architecture
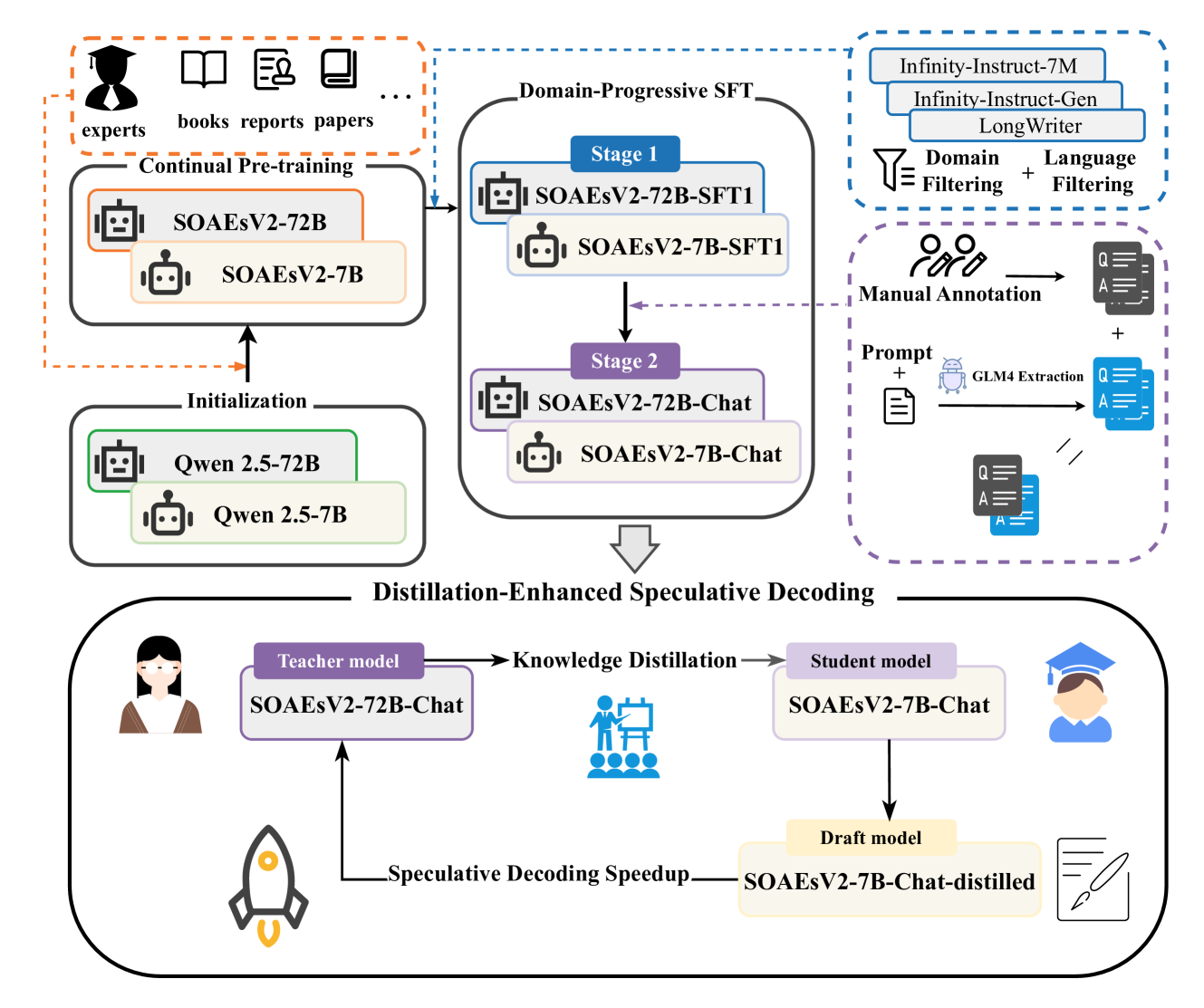
The full-pipeline optimization framework for SOAEsV2, detailing Continual Pre-Training, Domain-Progressive SFT, and Distillation-Enhanced Speculative Decoding.
Evaluation Highlights
- Domain-specific pre-training maintains 99.8% of original general capabilities while improving domain Rouge-1 by 1.08x and BLEU-4 by 1.17x.
- Domain-progressive Supervised Fine-Tuning (SFT) outperforms single-stage training, achieving 1.02x improvement in Rouge-1 and 1.06x in BLEU-4.
- Speculative decoding achieves 1.39 to 1.52x decoding speedup for the 72-billion parameter model without any loss in accuracy.
Breakthrough Assessment
7/10
Provides a robust, end-to-end framework integrating proven techniques (curriculum learning, speculative decoding) specifically tailored and successfully scaled up for the Chinese State-Owned Enterprise domain.