📊 Experiments & Results
Evaluation Setup
SFT on diverse domains, partitioning data into Model-Strong, Model-Intermediate, and Model-Weak regimes based on prior knowledge.
Benchmarks:
- General Instruction Following (Chat/Instruction)
- Mathematical Reasoning (Math QA)
- Code Generation (Coding)
Metrics:
- Win Rate (implied / standard for instruction tuning)
- Accuracy (for Math/Reasoning tasks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Overall Performance (Average across domains) | Relative Improvement | 0.0 | Positive | Positive |
| Analysis of training regimes shows DEFT's specific strengths. | ||||
| Model-Strong Regime | Performance | Lower | Higher | Significant |
| Model-Weak Regime | Performance | Lower | Higher | Significant |
Experiment Figures
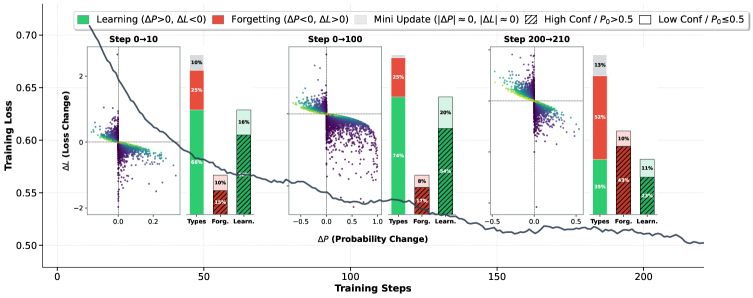
Scatter plot of token-level learning conflicts and a histogram of forgetting rates.
Main Takeaways
- DEFT successfully unifies coverage (learning new things) and sharpening (refining known things) in a single objective without manual hyperparameter tuning.
- The 'Trust Gate' mechanism effectively down-weights gradients from 'confident conflicts' (noisy labels where the model is right), preventing catastrophic forgetting.
- The Cayley transform provides a geometric justification for the dynamic schedule, moving beyond heuristic schedules used in prior work.
- Consistent improvements across varying model sizes (Strong/Weak regimes) suggest the method is robust to base model capability.