📝 Paper Summary
Supervised Fine-Tuning (SFT)
Token-level training objectives
Data-Efficient Instruction Tuning
ProFit modifies the Supervised Fine-Tuning loss by masking low-probability tokens during training, limiting optimization to high-confidence 'core' tokens that carry essential reasoning logic rather than stylistic noise.
Core Problem
Traditional SFT forces models to strictly align with a single reference answer, treating valid paraphrases as errors and causing overfitting to non-essential stylistic tokens rather than core reasoning logic.
Why it matters:
- Language is inherently one-to-many; penalizing valid variations degrades generalization and leads to rote memorization
- Multi-reference SFT is prohibitively expensive to annotate and often suffers from optimization instability due to conflicting gradients
- Standard SFT can degrade performance on complex reasoning tasks compared to base models by introducing noise from non-core expressions
Concrete Example:
If a reference answer uses the phrase 'result is' but the model predicts 'answer is' (a valid synonym), standard SFT penalizes this valid prediction heavily because it doesn't match the specific reference token. ProFit identifies 'result' as a low-probability, non-essential token and masks it, preventing this harmful penalty.
Key Novelty
Probability-Guided Hard Masking
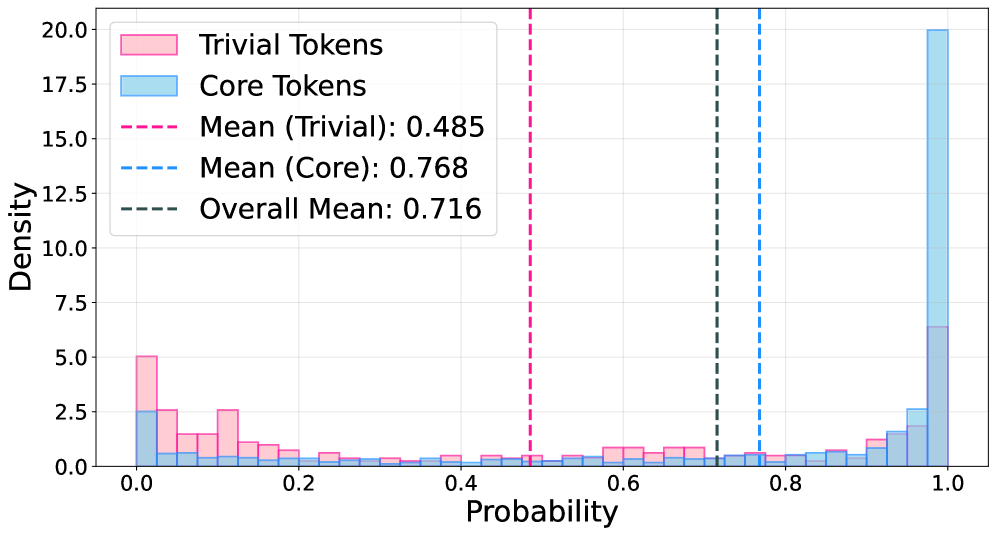
- Uses the model's own online prediction probability as a proxy for semantic importance: high-probability tokens are treated as 'core' logic, while low-probability tokens are treated as 'trivial' noise
- Applies a hard binary mask to the loss function: only tokens with probability above a threshold contribute to gradient updates, effectively filtering out stylistic variations dynamically
Architecture
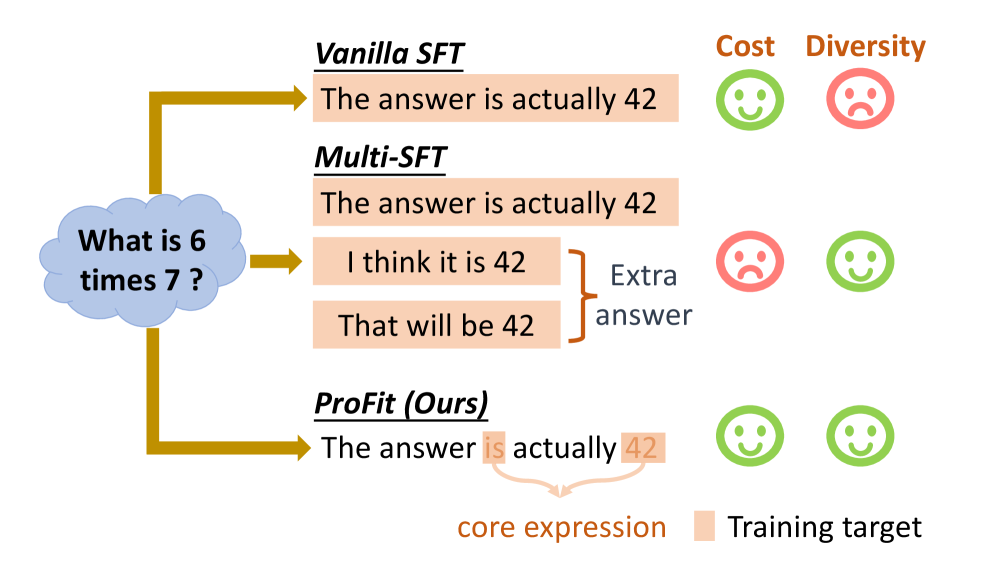
Illustration of the ProFit strategy compared to Traditional SFT. It shows how ProFit filters out low-value signals (trivial tokens) from a single reference answer.
Evaluation Highlights
- +10.94% average accuracy improvement on Qwen3-4B-Base compared to standard SFT across 5 benchmarks (52.33% vs 41.39%)
- Reverses performance degradation on Qwen3-14B-Base: where SFT drops -1.88% vs Vanilla, ProFit achieves +5.64% gain
- Consistently outperforms probability-aware baselines like DFT (+1.29% on Qwen3-0.6B) and entropy-based tuning on reasoning and math tasks
Breakthrough Assessment
7/10
Simple, intrinsic, and effective method that addresses a fundamental flaw in SFT (one-to-one mapping). Shows significant gains on reasoning tasks without external models, though relies on the heuristic that probability equals importance.