📝 Paper Summary
LLM Post-training
AI for Software Engineering
This paper establishes a comprehensive post-training pipeline for vulnerability detection, demonstrating that on-policy RL with fine-grained root-cause rewards significantly outperforms static supervision and binary evaluation metrics.
Core Problem
Existing vulnerability detection approaches rely on static supervision (SFT/DPO) that limits self-exploration and use coarse-grained binary rewards that fail to capture reasoning quality.
Why it matters:
- Binary outcome rewards often mislead training by crediting correct guesses derived from flawed logic (reward hacking)
- Static datasets for SFT and DPO become outdated as the policy improves, preventing the model from learning from its own successful rollouts
- Lack of context in function-level datasets leads to semantic blindness, causing hallucinations about missing sanitizers or trigger conditions
Concrete Example:
A student model trained via rationalization (where the teacher sees the ground truth) may hallucinate irrelevant CVE IDs because it learns to conflate external knowledge with internal reasoning, unlike a model trained via rejection sampling.
Key Novelty
Full-Pipeline Optimization for Vulnerability Detection (SFT → RL)
- First systematic investigation of the complete post-training pipeline for vulnerability detection, comparing SFT, off-policy preference optimization (DPO/ORPO), and on-policy RL (GRPO)
- Introduction of difficulty-aware data curation (filtering and curriculum scheduling) to address reward sparsity in reinforcement learning
- Development of multi-granularity reward systems ranging from binary detection to fine-grained, specification-based root cause analysis using LLM-as-a-Judge
Architecture
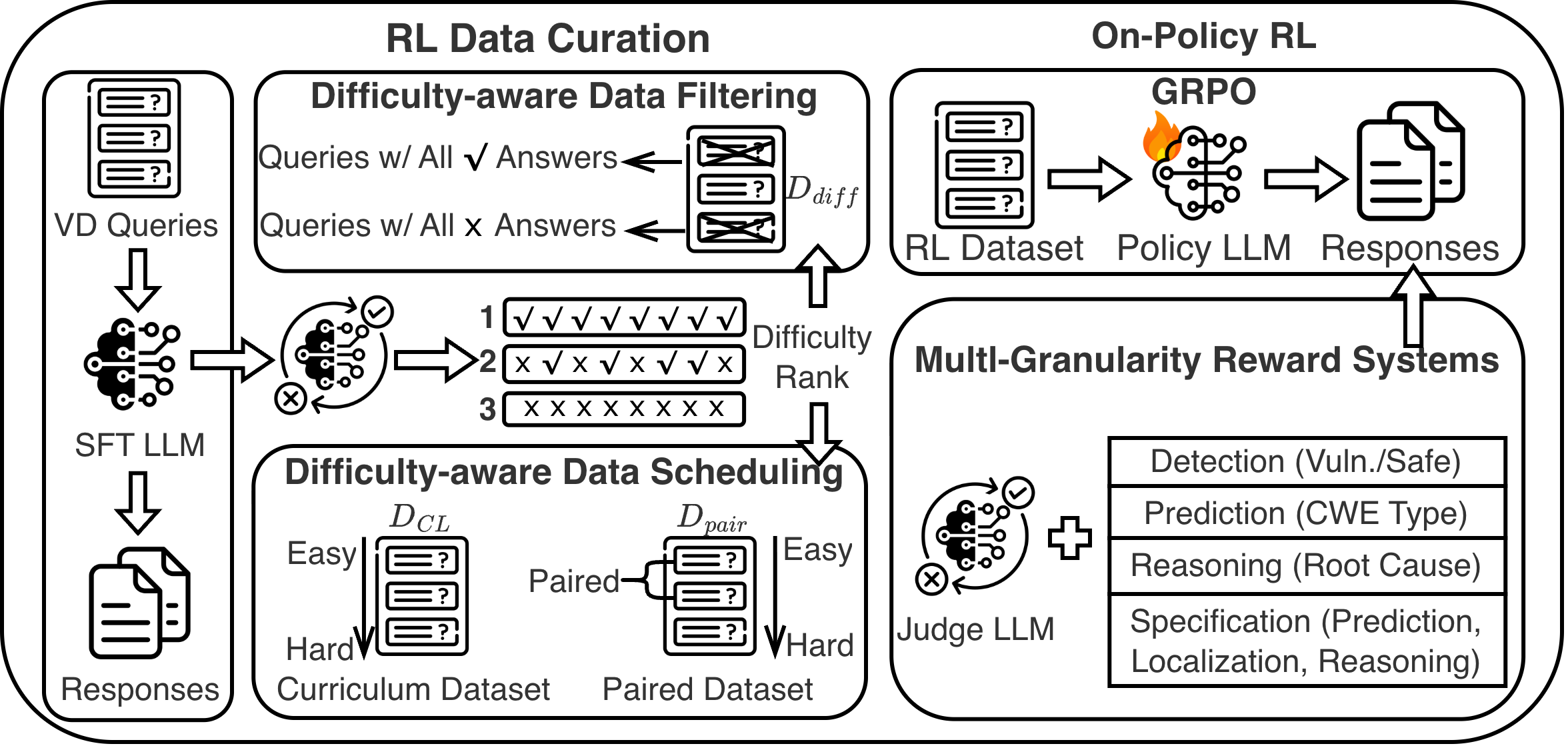
The on-policy RL pipeline using GRPO with difficulty-aware data curation mechanisms.
Breakthrough Assessment
8/10
Comprehensive analysis of the SFT-to-RL pipeline for a specific domain (security). The shift from binary matching to root-cause rewards and the application of GRPO to vulnerability detection are significant methodological advancements.