📝 Paper Summary
LLM Post-training
Alignment
Supervised Fine-Tuning (SFT)
The paper proposes On-Policy SFT by introducing a theory to quantify in-distribution data and applying it to reweight training losses and re-align dataset generation.
Core Problem
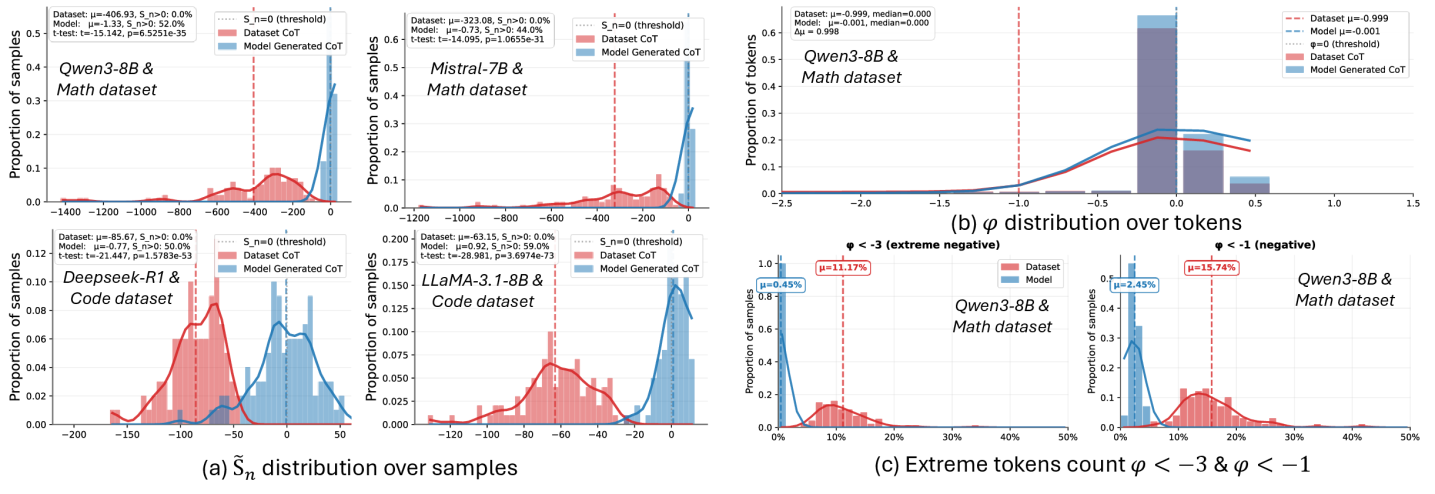
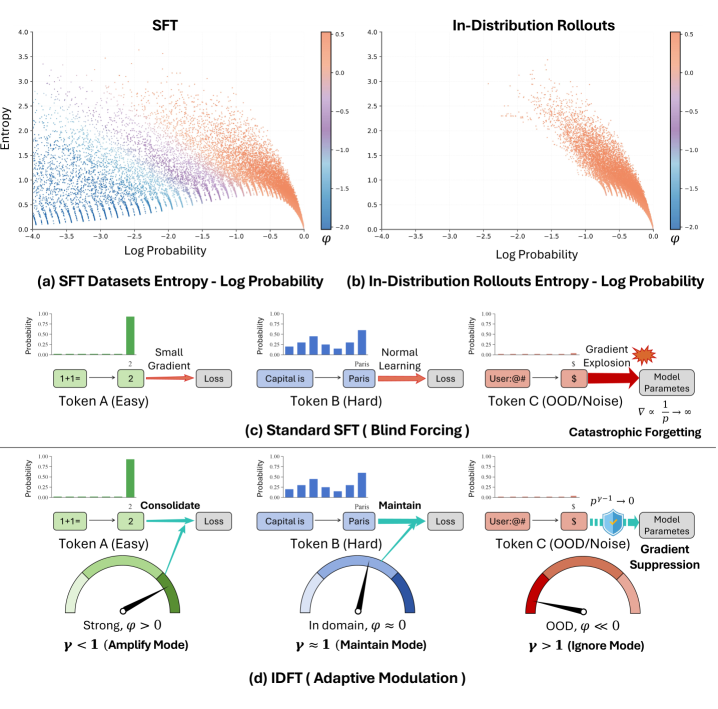
Standard Supervised Fine-Tuning (SFT) forces models to fit all data equally, including out-of-distribution samples, which disrupts pre-trained knowledge and leads to inferior generalization compared to Reinforcement Learning (RL).
Why it matters:
- RL is computationally expensive and difficult to apply in sparse-reward settings (e.g., mathematical proofs) or where verifiers are biased
- SFT suffers from catastrophic forgetting because it lacks the ability to distinguish whether a sequence matches the model's internal distribution
- Bridging the gap allows SFT to retain high data efficiency while achieving the superior generalization capabilities typically associated with on-policy RL
Concrete Example:
When a model is forced to learn a response that is stylistically valid but statistically 'out-of-distribution' (like a teacher's forcing style), the standard SFT loss imposes large gradients because the probability is low. This aggressive update destabilizes the model's general structure. In contrast, the proposed method detects this mismatch and suppresses the gradient.
Key Novelty
Distribution Discriminant Theory (DDT) & In-Distribution Finetuning (IDFT)
- Introduces Centered Log-Likelihood (CLL) as a theoretically optimal statistic to distinguish in-distribution tokens from out-of-distribution ones, based on Signal Detection Theory
- Proposes IDFT, a loss function that dynamically reweights updates: it suppresses gradients for statistically distant (OOD) tokens to prevent forgetting and reinforces in-domain tokens
- Develops Hinted Decoding, a method that mixes a teacher's guidance with the model's own distribution during data generation to create training samples that are both correct and aligned
Architecture
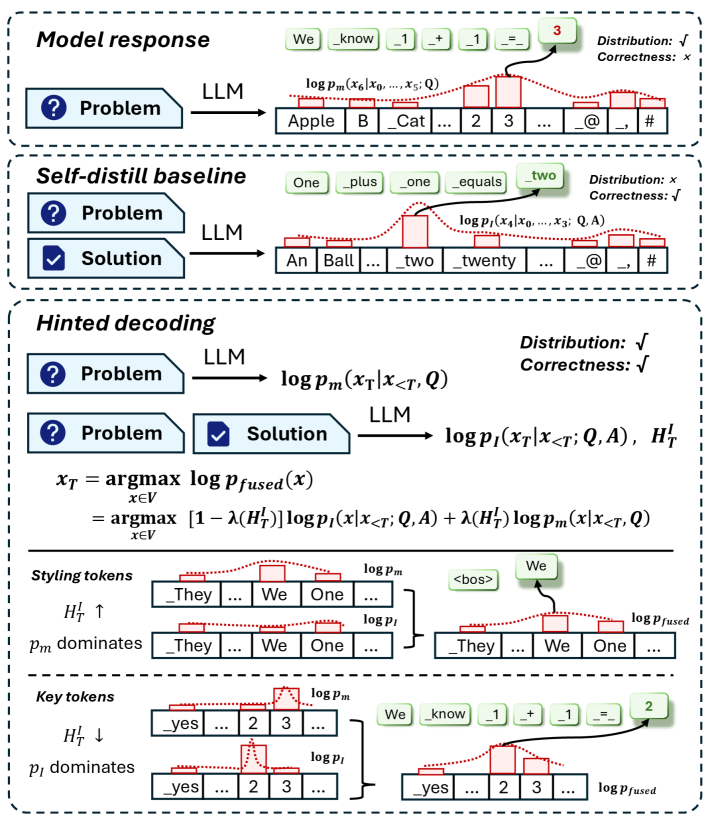
Conceptual process of Hinted Decoding mixing distributions
Evaluation Highlights
- Surpasses prominent offline RL algorithms, including DPO and SimPO, on generalization performance
- Achieves higher data efficiency and uses less compute compared to offline RL methods on the same data
- Demonstrates that IDFT delivers substantial gains over standard SFT when training base models on fixed datasets
Breakthrough Assessment
8/10
Provides a rigorous theoretical foundation (DDT) for a longstanding empirical problem (SFT vs RL gap) and offers practical, efficient solutions that outperform complex RL methods.