📝 Paper Summary
Post-training optimization
Reasoning models
Scaling SFT data (prompts and responses) and carefully tuning RL temperature enables a 7B model to achieve state-of-the-art math and code reasoning performance.
Core Problem
Systematic studies on the interplay between SFT and RL for reasoning are limited, specifically regarding data scaling strategies and how SFT strength influences final RL performance.
Why it matters:
- Current frontier models use large-scale RL but lack technical transparency on the synergy with SFT.
- It is unclear whether stronger SFT models consistently yield better RL outcomes or if improvements plateau.
- Determining the optimal exploration-exploitation balance (temperature) during RL remains a heuristic process without clear guidelines.
Concrete Example:
When RL training is applied to a weak SFT model versus a strong one, it is often assumed the gap closes; however, this paper finds the stronger SFT model maintains a lead, necessitating better SFT initialization strategies.
Key Novelty
Synergistic Post-Training Recipe (AceReason-Nemotron 1.1)
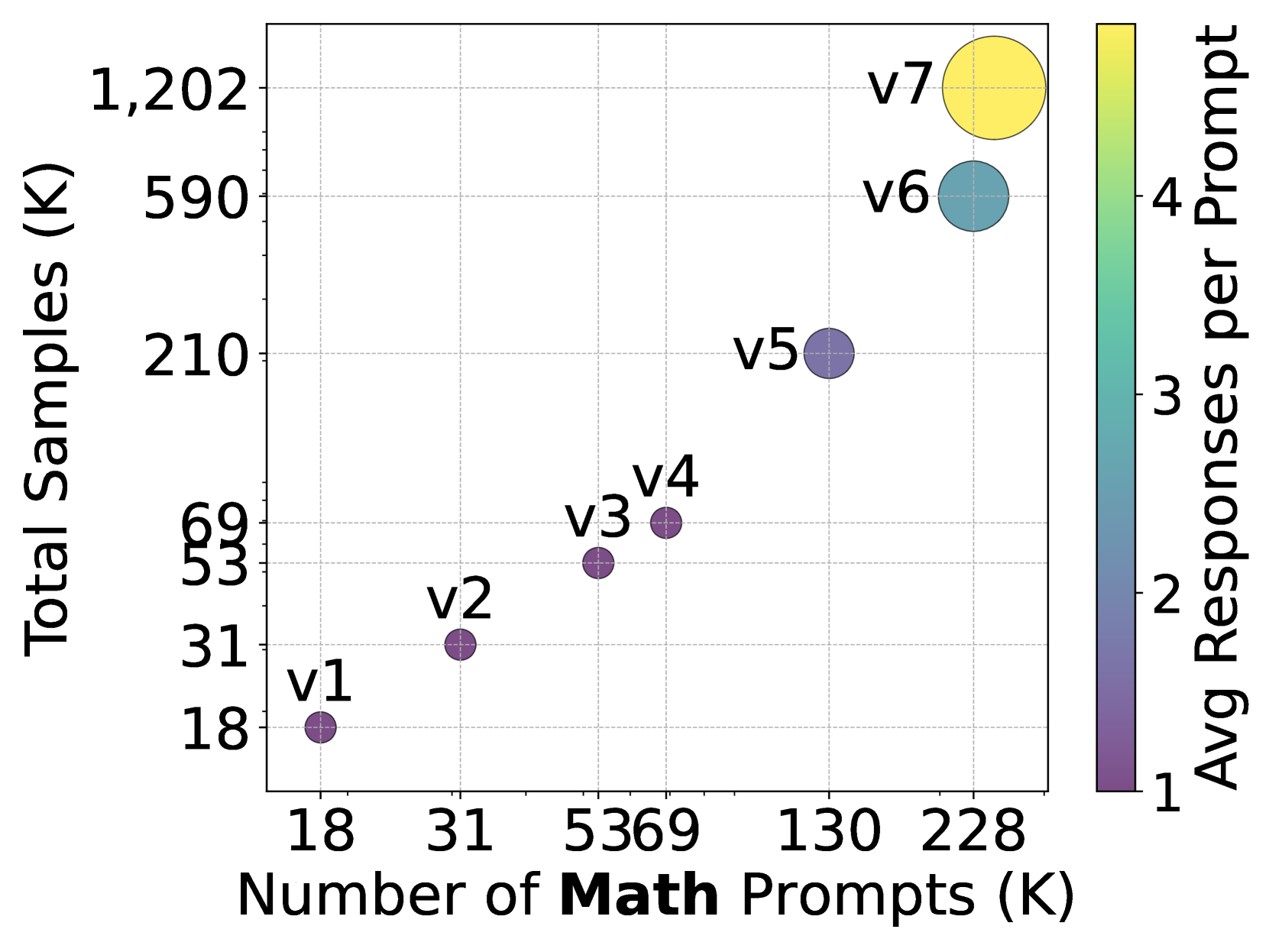
- Demonstrates that scaling SFT prompts yields higher gains than scaling responses per prompt, and that stronger SFT consistently leads to better RL outcomes.
- Introduces a temperature selection rule for RL: setting sampling temperature to maintain temperature-adjusted entropy around 0.3 balances exploration and exploitation.
- Proposes a curriculum where 'overlong filtering' (masking samples exceeding token budgets) is beneficial only for short budgets (8K/16K) but harmful for long budgets (24K/32K).
Architecture
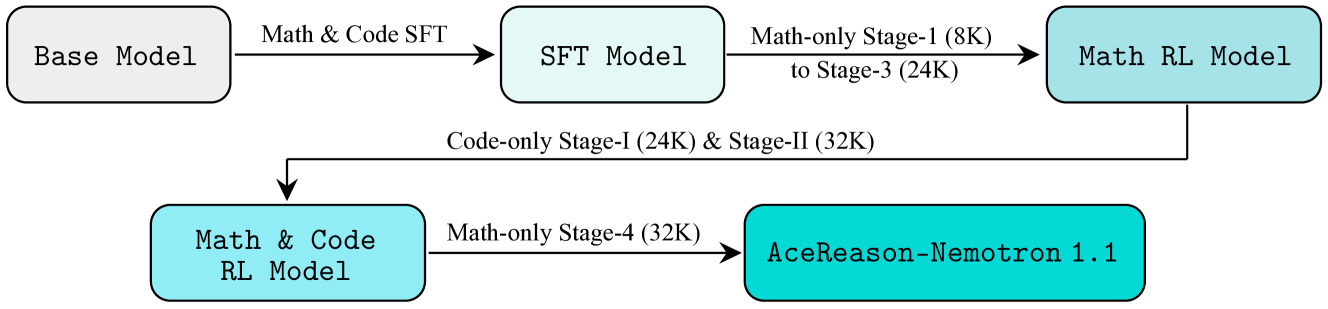
The overall training pipeline including Data Curation, SFT Scaling, and Multi-stage RL.
Evaluation Highlights
- Achieves state-of-the-art performance among Qwen2.5-7B-based models on math and code benchmarks.
- Scaling SFT prompts from 36K to 247K (math) significantly improves pass@1 performance.
- RL training narrows the gap between weak and strong SFT models but preserves the rank order, with stronger SFT starts yielding higher final peaks.
Breakthrough Assessment
7/10
Provides a comprehensive, empirical recipe for post-training reasoning models, offering concrete scaling laws for SFT and practical heuristics for RL temperature, achieving SOTA for its size class.