📊 Experiments & Results
Evaluation Setup
Comparison of in-domain math performance vs out-of-domain general knowledge retention
Benchmarks:
- MATH-500 (Mathematical Reasoning)
- GSM8k (Grade School Math)
- MMLU (General Knowledge)
- GPQA-Diamond (Expert-level Science/QA)
- AIME24 (Competition Math)
Metrics:
- Accuracy
- KL Divergence (per-token)
- Normalized Frobenius Norm (parameter updates)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Training Stability | Learning Rate | Not reported in the paper | 1e-6 | Not reported in the paper |
Experiment Figures
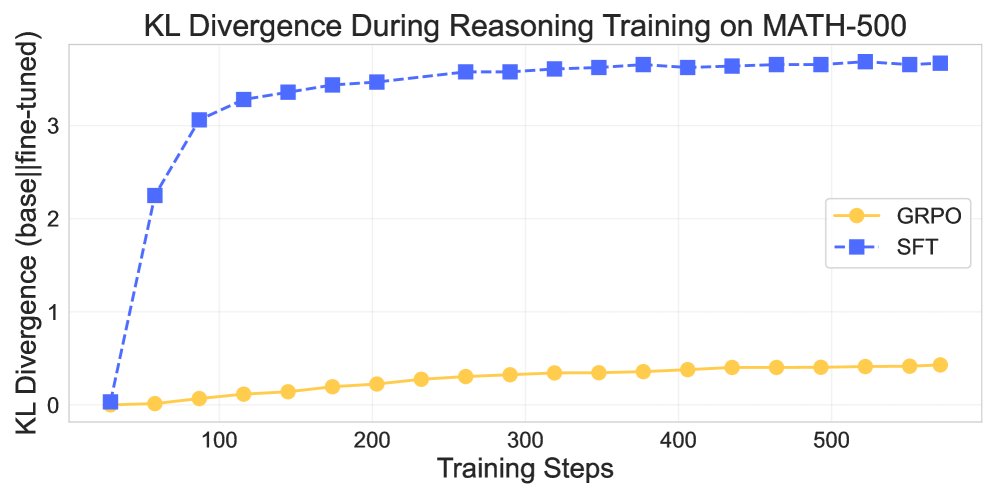
KL Divergence between the base model and checkpoints throughout training for GRPO and SFT.
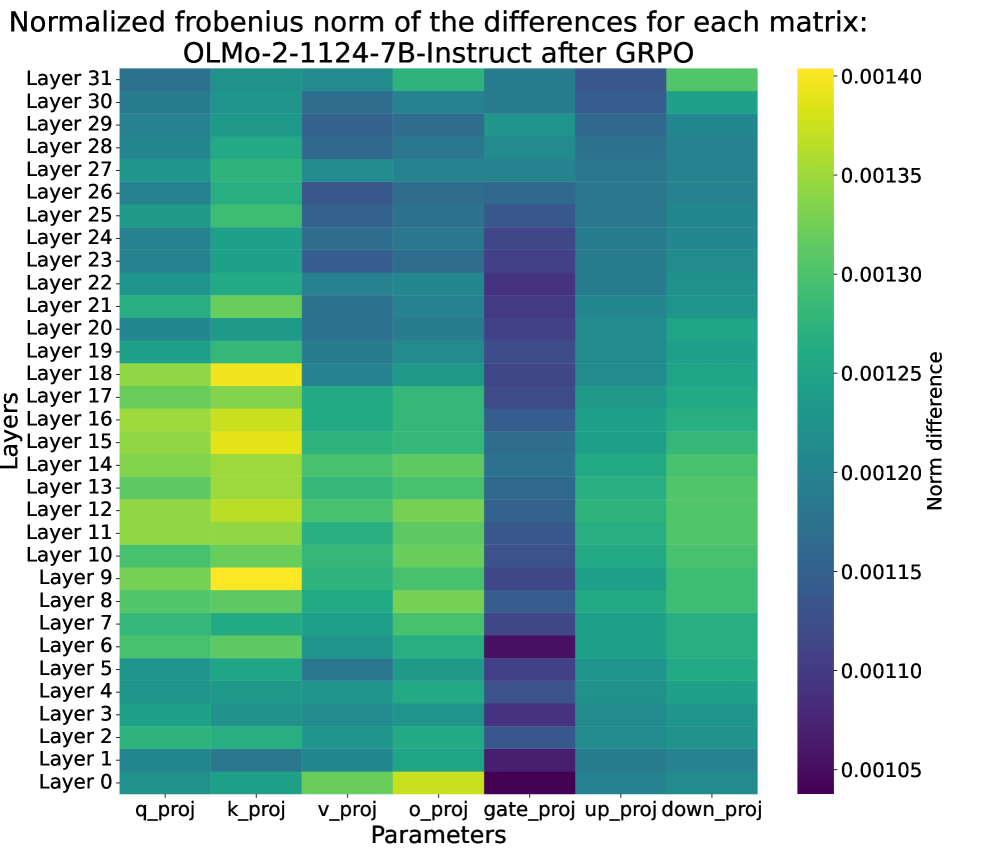
Normalized Frobenius norm of parameter differences (base model vs trained model) across layers for GRPO.
Main Takeaways
- SFT acts as a 'hammer': it provides larger gains on in-domain MATH-500 but significantly degrades performance on knowledge benchmarks (MMLU, MMLU-Pro) and existing skills (GSM8k few-shot).
- GRPO acts as a 'scalpel': it yields modest in-domain gains but largely preserves out-of-domain capabilities and general knowledge.
- Internal Dynamics: SFT causes large parameter updates in mid-layer MLPs (factual memory), while GRPO reinforces existing capabilities via subtle updates to attention query/key weights.
- Distribution Shift: SFT causes a sharp, early increase in KL divergence (fitting a new distribution), whereas GRPO shows gradual divergence (refining the existing distribution).