📝 Paper Summary
LLM Reasoning
Reinforcement Learning for LLMs
Post-training methodologies
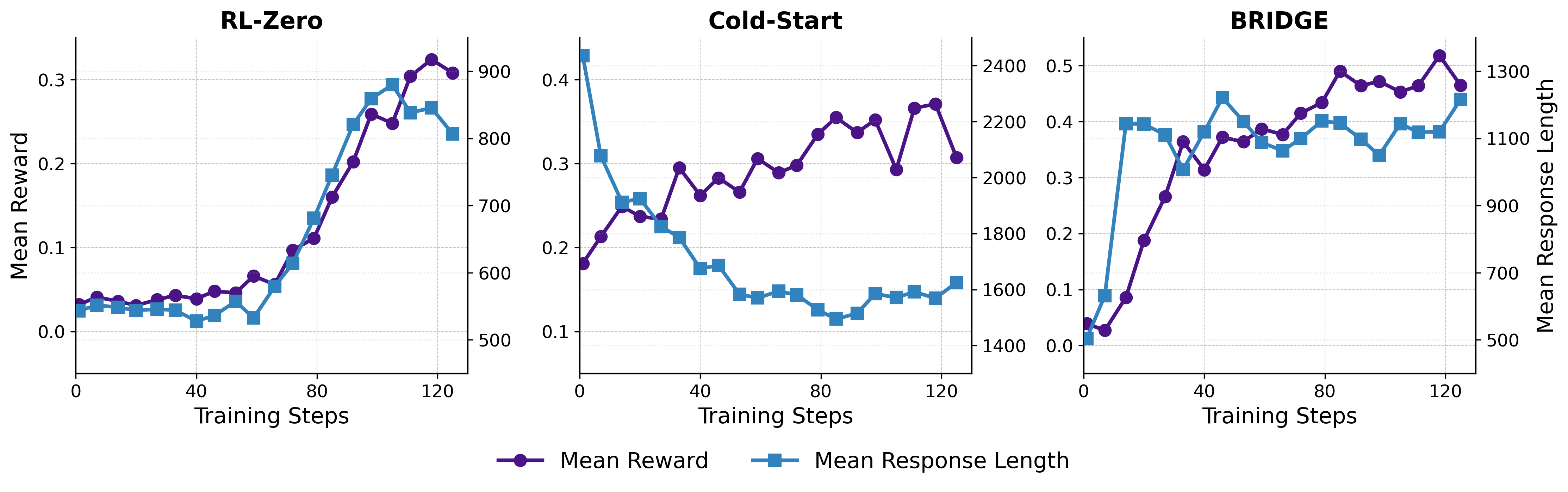
BRIDGE unifies SFT and RL into a single cooperative bilevel optimization process, where SFT meta-learns to guide RL, preventing catastrophic forgetting and improving exploration.
Core Problem
The standard two-stage 'cold start' pipeline (SFT followed by RL) suffers from catastrophic forgetting, where the model loses SFT-acquired behaviors during RL, and inefficient exploration due to lack of guidance.
Why it matters:
- Current reasoning models like OpenAI o1 rely on large-scale RL, but the trial-and-error nature is highly inefficient without guidance.
- The decoupled nature of two-stage training causes a 'dip-then-rise' performance trajectory, wasting compute and data efficiency.
- SFT alone generalizes poorly, while RL alone is slow to converge; existing methods fail to synergize their complementary strengths.
Concrete Example:
In cold-start training, response lengths initially drop sharply during the RL stage before recovering (a U-shaped trajectory), indicating the model forgets expert reasoning patterns from SFT before painfully relearning them through trial and error.
Key Novelty
BRIDGE (Bilevel Reinforcement and Imitation for Diverse Generation and Exploration)
- Formulates training as a bilevel optimization game where SFT is the upper-level 'teacher' and RL is the lower-level 'student'.
- Uses an augmented architecture: a base model optimized by RL and a LoRA module optimized by SFT to maximize the 'cooperative gain' (improvement over RL alone).
- Enables bidirectional information flow: SFT sees the RL solution and updates parameters to guide the next RL step, rather than just providing a static initialization.
Architecture
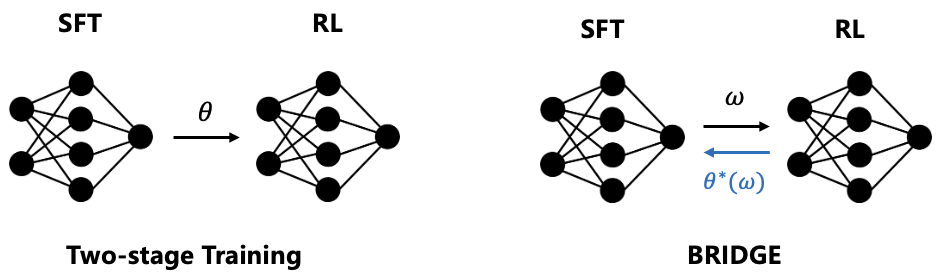
The bilevel optimization framework of BRIDGE. It illustrates the interaction between the Upper-Level (SFT) and Lower-Level (RL) objectives.
Evaluation Highlights
- Achieves 44% faster training with a 13% performance gain on Qwen2.5-3B compared to baselines.
- Achieves 14% faster training with a 10% improvement on Qwen3-8B compared to baselines.
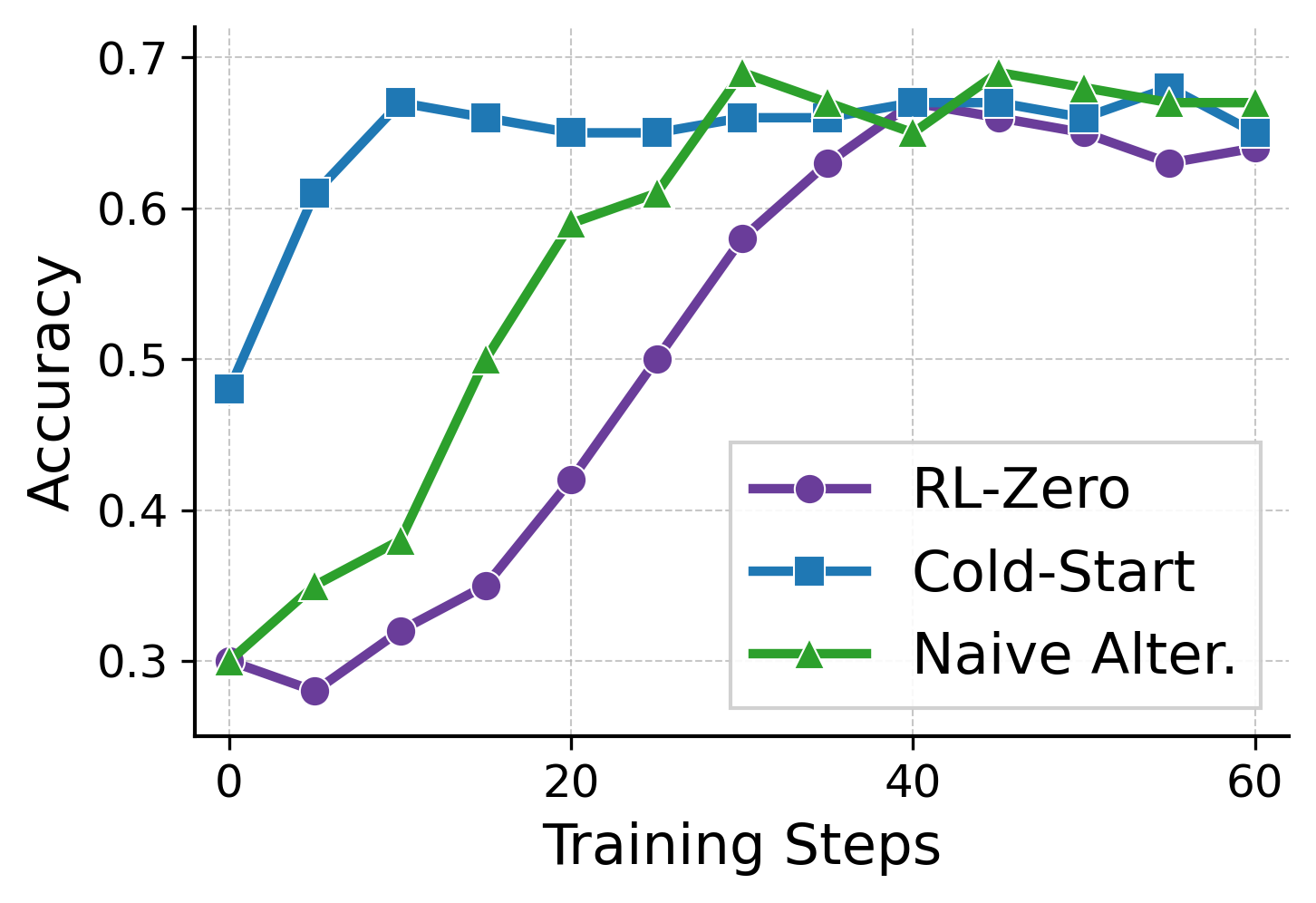
- Consistently outperforms SFT, RL-zero, cold-start, and alternating baselines across five math benchmarks (including MATH and OlympiadBench).
Breakthrough Assessment
8/10
Offers a mathematically grounded solution to the well-known 'alignment tax' or forgetting problem in RLHF/RLVR pipelines. The bilevel formulation is a significant conceptual advance over simple multi-task learning.