📝 Paper Summary
Post-training for Reasoning LLMs
Reinforcement Learning with Verifiable Rewards (RLVR)
Mechanistic Analysis of Reasoning
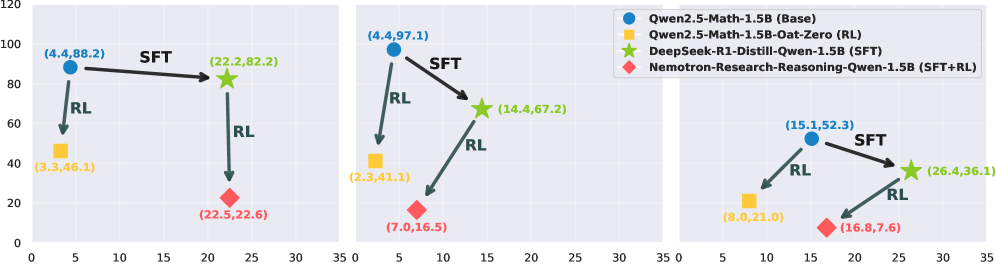
By modeling reasoning as both trajectories and graphs, this study reveals that RL consolidates reasoning into fewer, high-frequency correct paths (squeezing), while SFT diversifies valid strategies (expanding), justifying the two-stage SFT+RL training paradigm.
Core Problem
While RL and SFT are standard for training reasoning LLMs, their specific effects on the underlying reasoning process remain unknown, as evaluations typically rely only on final answer accuracy (Pass@k).
Why it matters:
- Current training recipes (SFT followed by RL) are developed through trial-and-error without understanding why they work effectively together.
- Pass@k metrics can mask underlying behaviors, such as whether a model is memorizing specific paths or generalizing to new strategies.
- Understanding how training alters reasoning topology is crucial for designing better data curation strategies and more efficient post-training methods.
Concrete Example:
When an RL model is sampled multiple times, it often collapses to a few specific solution paths (high repetition), whereas an SFT model might generate many diverse valid paths. Without analyzing this 'squeezing' vs 'expanding' behavior, researchers cannot explain why RL improves Pass@1 but degrades Pass@k at large k.
Key Novelty
Trajectory and Step-Level Reasoning Analysis Framework
- Trajectory-level: Clusters entire generated reasoning chains to quantify 'unique' correct vs. incorrect paths, revealing how training objectives alter the diversity of solutions.
- Step-level: Constructs a 'reasoning graph' where nodes are clustered sentence embeddings and edges are transitions, analyzing topological properties like centrality and modularity to see how reasoning flows change.
Architecture
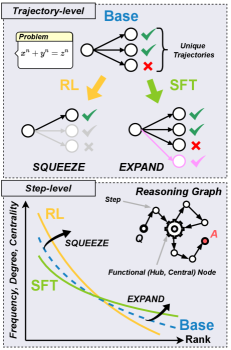
Conceptual overview of the analysis framework. Left: Trajectory-level analysis showing unique clusters of correct/incorrect paths. Right: Step-level analysis showing the reasoning graph construction and topology.
Evaluation Highlights
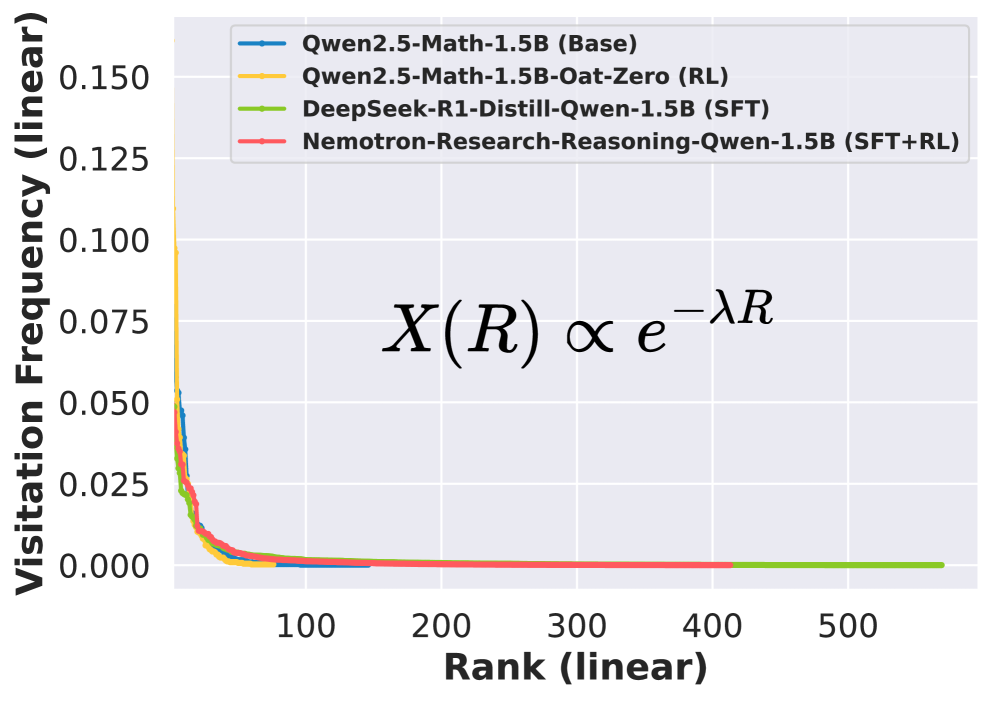
- RL steepens the decay rate of node visitation frequency in reasoning graphs by ~2.5x, indicating concentration of reasoning into fewer hub steps.
- SFT flattens the decay rate of node visitation frequency to ~1/3, indicating expansion of reasoning across diverse steps.
- SFT increases the count of unique correct trajectories (expansion), whereas RL drastically reduces the count of unique incorrect trajectories (squeezing/compression).
Breakthrough Assessment
8/10
Provides the first comprehensive mechanistic explanation for the success of the standard SFT+RL pipeline. The graph-theoretic perspective offers a novel, quantitative way to measure 'reasoning diversity' beyond simple accuracy metrics.